分享时间:2025-06-08 | 主讲:程治玮
录屏回看
1 什么是 Prefix Caching
前缀缓存(Prefix Caching)是一种大语言模型推理优化技术,它的核心思想是缓存历史对话中的 KV Cache,以便后续请求能直接重用这些中间结果。这样可以显著降低首 token 延迟,提升整体推理效率。Prefix Caching 尤其适用于多轮对话、长文档问答等高前缀复用场景。 Prefix Caching 在大语言模型推理中的应用场景主要包括以下几类: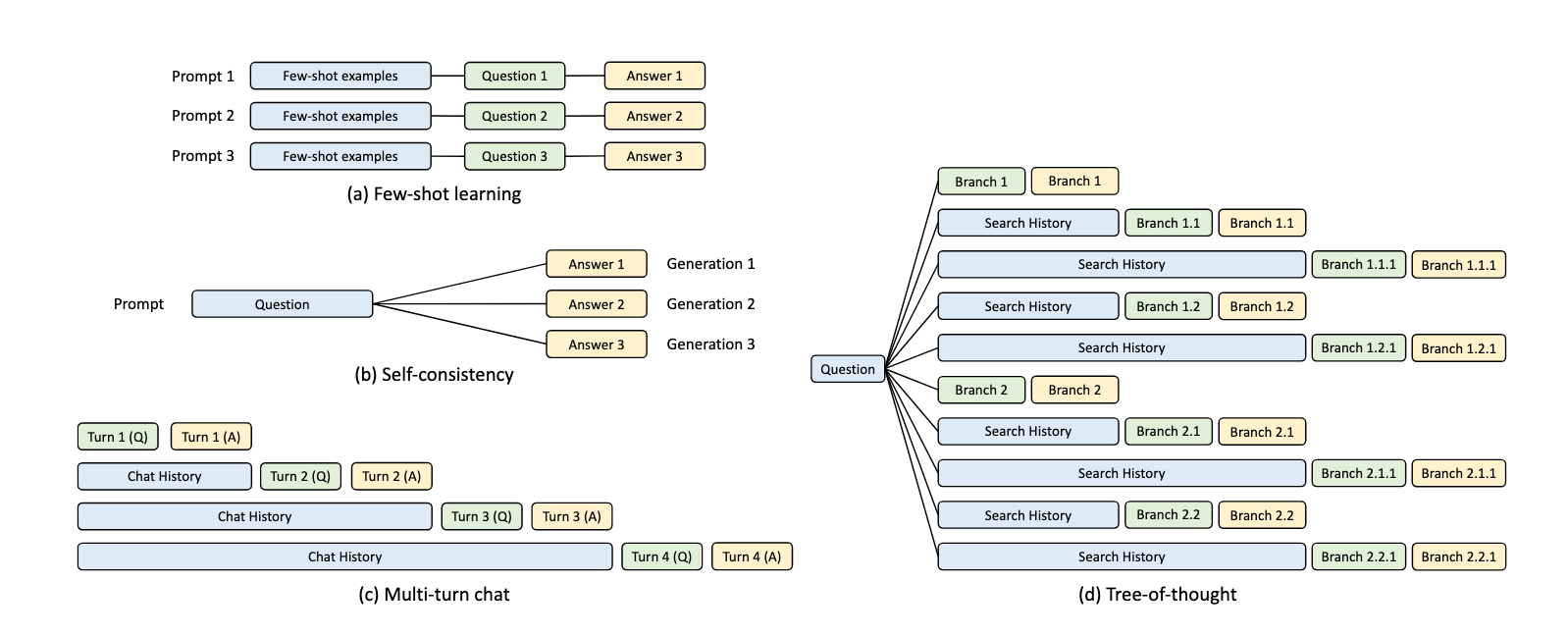
- Few-shot learning(少样本学习):多个请求都包含相同的 few-shot 示例部分,只是最后的问题不同。Prefix Caching 可以将这些 few-shot 示例的 KV Cache 复用,避免每次都重新计算相同的示例内容。
- Self-consistency(自洽性):对于同一个问题,先采样多个不同的推理路径(重复请求多次),然后选择最一致的答案。这些请求都共享相同的前缀(问题部分),Prefix Caching 可以让每次 decode 时都直接复用问题部分的缓存,只计算不同的答案部分。
- Multi-turn chat(多轮对话):多轮对话中,每一轮的对话都基于之前的聊天历史。Prefix Caching 允许每一轮都复用之前聊天历史的KV缓存,只对新增的问答部分进行计算。
- Tree-of-thought(思维树):复杂推理任务中,一个问题会被分解成多个分支,每个分支下又有进一步的分支。每个分支都共享前面的搜索历史作为前缀。Prefix Caching 可以让所有分支共享公共的历史部分缓存,只对各自独立的分支内容做增量计算。
Prefix Caching 只会减少处理查询(prefill 阶段)的时间,而不会减少生成新 token(decode 阶段)的时间。
2 PagedAttention 和 Prefix Caching 的关系
- PagedAttention 主要解决 KV Cache 如何在 GPU 显存中“按需分配”,通过分页机制让 KV Cache 可以非连续存储和动态扩容,极大缓解内存碎片化问题,实现高效的内存管理。
- Prefix Caching 则专注于“避免重复算”,即当多个请求有相同的 prompt 前缀时,只需计算一次并缓存其 KV,后续请求直接复用,显著降低首 token 时延,尤其适合多轮对话和长 system prompt 场景。
3 RadixAttention
论文 SGLang: Efficient Execution of Structured Language Model Programs 中提出通过 RadixAttention 来实现Prefix Caching。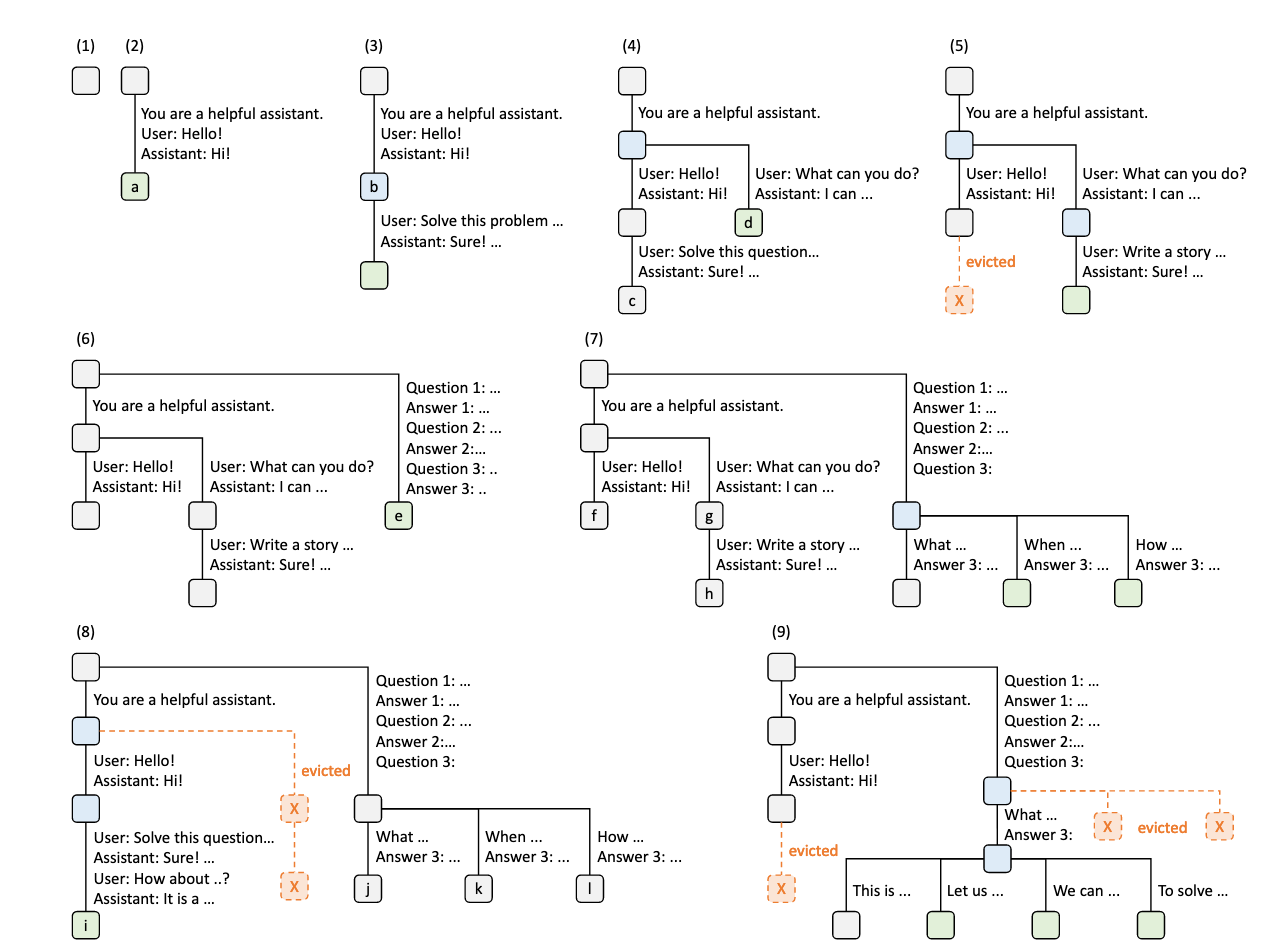 上图展示了采用 LRU 淘汰策略的 RadixAttention 操作示例,描绘了 Radix Tree(基数树)在不同请求作用下的动态演化过程。这些请求包括两个对话会话、一批 few-shot 学习查询,以及一次自洽性采样(self-consistency sampling)。树的每条边标注了一个子字符串或一段 token 序列,节点则通过颜色编码以区分不同状态:
上图展示了采用 LRU 淘汰策略的 RadixAttention 操作示例,描绘了 Radix Tree(基数树)在不同请求作用下的动态演化过程。这些请求包括两个对话会话、一批 few-shot 学习查询,以及一次自洽性采样(self-consistency sampling)。树的每条边标注了一个子字符串或一段 token 序列,节点则通过颜色编码以区分不同状态:
- 绿色表示新添加的节点,
- 蓝色表示当前时间点访问到的缓存节点,
- 红色表示已经被淘汰的节点。
- 步骤(1):Radix Tree 初始为空。
- 步骤(2):服务器接收到用户消息
"Hello",并生成 LLM 回复"Hi"。系统提示"You are a helpful assistant"、用户消息"Hello!"和模型回复"Hi!"被整合为一条边,并连接到一个新节点。 - 步骤(3):新的 prompt 到达,服务器在树中找到了该 prompt 的前缀(即第一轮对话),并重用其 KV cache。新的对话轮次作为新节点追加进树中。
- 步骤(4):开启新的对话会话。为了让两个会话共享系统提示,“b” 节点被拆分成两个节点。
- 步骤(5):第二个会话继续,但由于内存限制,第 (4) 步中的 “c” 节点被淘汰。新的轮次被追加在 “d” 节点之后。
- 步骤(6):服务器收到一个 few-shot learning 查询,将其插入树中。由于该查询和现有节点没有公共前缀,根节点被拆分。
- 步骤(7):服务器收到一批新的 few-shot learning 查询。它们共享相同的 few-shot 示例,因此将 (6) 中的 “e” 节点拆分以实现共享。
- 步骤(8):服务器收到来自第一个对话会话的新消息。由于使用 LRU 策略,第二个对话的所有节点(如 “g” 和 “h”)被淘汰。
- 步骤(9):服务器收到一个请求,要求对 (8) 中 “j” 节点的问题进行更多回答采样,可能是用于自洽性采样(self-consistency sampling)。为了腾出空间,第 (8) 步中的 “i”、 “k”、 “l” 节点被淘汰。
4 vLLM 中的 Prefix Caching
最初,vLLM 支持手动前缀缓存,用户需通过prefix_pos 参数显式指定前缀边界位置。
PR:https://github.com/vllm-project/vllm/pull/1669
从 v0.4.0 版本开始,vLLM 引入了自动前缀缓存(Automatic Prefix Caching),无需手动指定即可自动识别并复用共享前缀。
PR:https://github.com/vllm-project/vllm/pull/2762
4.1 在 vLLM 中启用 Prefix Caching
4.1.1 环境准备
执行以下命令安装 vLLM。4.1.2 离线推理(Offline Inference)
在 vLLM 中设置enable_prefix_caching=True 可以启用 Automatic Prefix Caching。下面这段代码展示了 vLLM 的 Automatic Prefix Caching 功能:第一次生成关于 “John Doe 年龄” 的回答时,需要完整构建 KV Cache;而第二次询问 “Zack Blue 年龄”,由于两次问题共享相同的长表格前缀,vLLM 会自动复用已有缓存,从而显著减少重复计算,加速生成过程。
4.1.3 在线推理(Online Serving)
在 GPU 后端中,v1 版本 的 vLLM 默认启用 Prefix Caching(v0 默认禁用),可以通过--no-enable-prefix-caching 参数禁用 Prefix Caching。执行以下命令启动 vLLM 服务提供在线推理:
4.2 实现原理
vLLM 选择了基于哈希的方法来实现 Prefix Caching。具体来说,vLLM 根据每个 KV block 内的 token 和该 block 之前前缀中的 token 来计算该 block 的哈希值:4.2.1 Block 的哈希值计算
在 vllm v1 中,一个 block 的哈希值由 3 个因素决定:- parent_block_hash:父 block 的哈希值。
- cur_block_token_ids:该 block 中维护的 token ids。
- extra_keys:用于确保该 block 唯一性的其他信息,例如 LoRA ID、多模态输入的哈希值,以及在多租户环境下用于隔离缓存的 cache salt 等。
4.2.2 数据结构
在 vLLM 中实现 Prefix Caching 的数据结构如下图所示: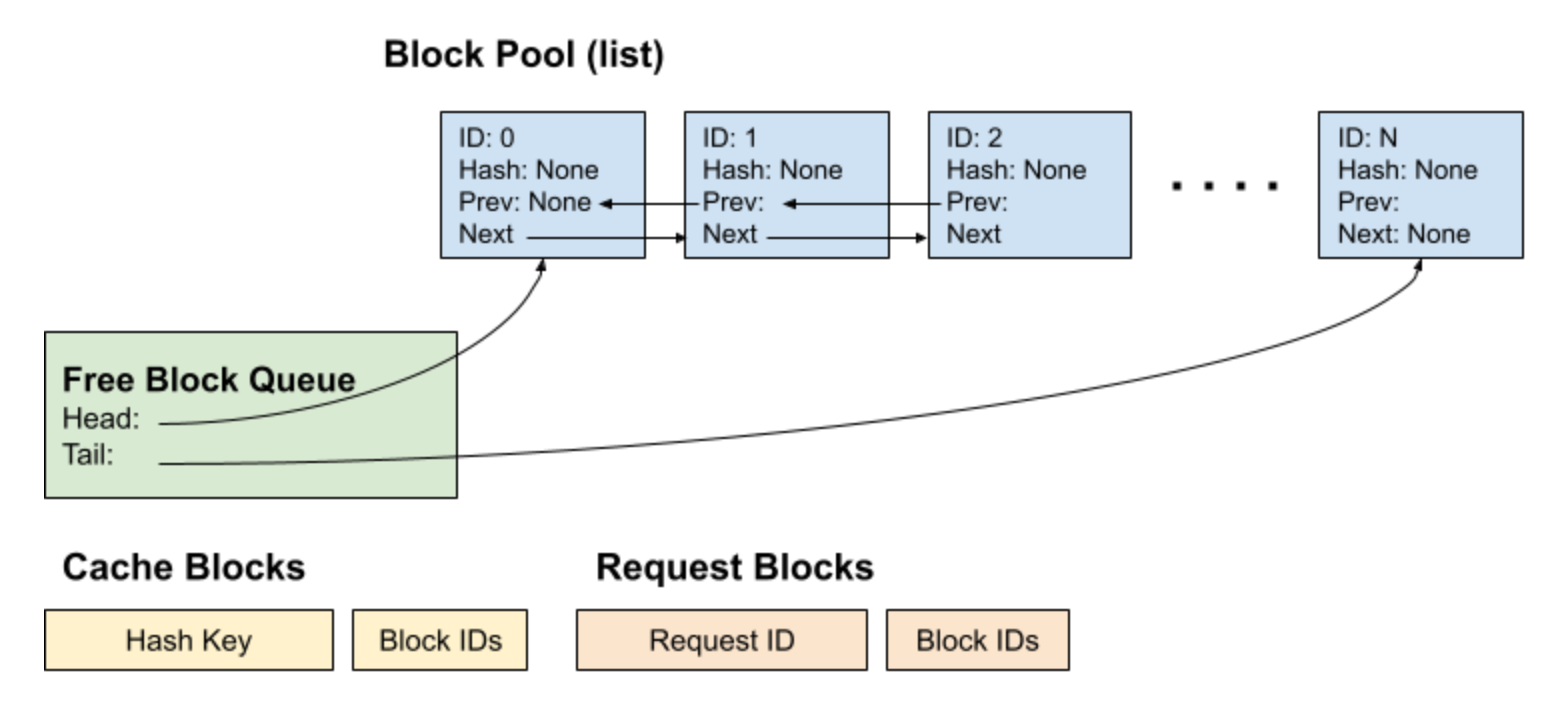
- Block Pool:管理所有 KV Cache block,提供分配、释放和缓存 block 的方法。Block Pool 包含所有的
KVCacheBlock,以及用于管理空闲块的FreeKVCacheBlockQueue,同时还通过 Cache blocks (cached_block_hash_to_block)(Dict[BlockHashType, Dict[block_id, KVCacheBlock])维护哈希值与缓存 block 之间的映射关系。
- Free Block Queue(free_block_queue 属性,FreeKVCacheBlockQueue 实例):是一个由
KVCacheBlock组成的双向链表结构,用于维护所有空闲的 KV Cache block。 队列本身仅维护head和tail指针,每个 block 通过其 prev_free_block 和 next_free_block 字段链接。该结构支持以 O(1) 时间复杂度添加、删除或移动任意位置的 block,便于高效实现 LRU 淘汰策略和资源调度。
当一个 block 被分配后再释放时,会根据以下淘汰顺序重新添加到队列中(越靠前缓存越先被淘汰):
- 最近最少使用(LRU)的 block 排在最前;
- 如果多个 block 的最后访问时间相同(例如由同一个请求分配), 那么**哈希 token 数更多的 block **排在更前。“哈希token数更多”在 vLLM 的中指的是在 block 链中位置更靠后的 block。在一个序列中:第一个块的哈希只依赖于其自身的 token,第二个块的哈希依赖于第一个块的哈希和自身的 token,第三个块的哈希依赖于第二个块的哈希和自身的 token,以此类推。因此序列末尾的块通常包含特定于当前请求的内容,复用价值较低 序列开头的块(如系统提示)更可能在不同请求间共享。
- Request blocks 以及 Block Pool 都维护在 KVCacheManager 类中。
req_to_blocks:Dict[req_id: List[KVCacheBlock]],记录一个请求下所有的 block。req_to_block_hashes:Dict[req_id, List[BlockHashType]],记录一个请求下所有的 block 的 hash 值。由于只有满块才可以被计算 hash 值,因此相同请求下,可能存在len(List[BlockHashType]) < len(List[KVCacheBlock])的情况。
4.2.3 操作
4.2.3.1 分配 Block
调度器为新请求分配 KV Cache block 的流程如下:-
调用
kv_cache_manager.get_computed_blocks(): 根据请求的 prompt tokens 进行哈希,并在缓存中查找对应的 Cache Blocks,获取已计算的 block 序列。 -
调用
kv_cache_manager.allocate_slots():执行以下步骤:- 计算当前请求需要分配的新 block 数量;若可用 block 数不足,则直接返回;
- “触碰(touch)”已命中的缓存 block:即增加其引用计数,并将其从 Free Block Queue 中移除(如果当前没有其他请求在用),这样做是为了防止这些缓存 block 被淘汰。
- 通过弹出 Free Block Queue 的队头来分配新 block;如果该 block 是缓存 block,则同时会驱逐该 block,其他请求将无法再复用此 block。
- 如果新分配的 block 已经被 token 填满,则立即将其添加到 Cache Blocks 中,以便在同一批次中的其他请求可以复用。
kv_cache_manager.allocate_slots():执行以下步骤:
- 计算当前需要分配的新 block 数量;若可用 block 不足,则返回;
- 同样从 Free Block Queue 的队头弹出 block;如果弹出的 block 是缓存 block,则同时驱逐该 block,避免其他请求再复用;
- 将 token ID 写入已有 block 和新分配的 block 中的空槽位。如果某个 block 被填满,则将其添加到 Cache Blocks 中以进行缓存。
4.2.3.2 释放 Block
当一个请求结束时,如果其占用的 block 没有被其他请求使用(引用计数为 0),则释放这些 block。 在本例中,释放了请求 1 以及其关联的 block 2、3、4 和 8。可以看到,释放的 blocks 会按照逆序添加到 Free Block Queue 的尾部。这是因为请求的最后一个 block 通常哈希了更多的 token,更具请求特异性,不太可能被其他请求复用,因此应当优先被淘汰。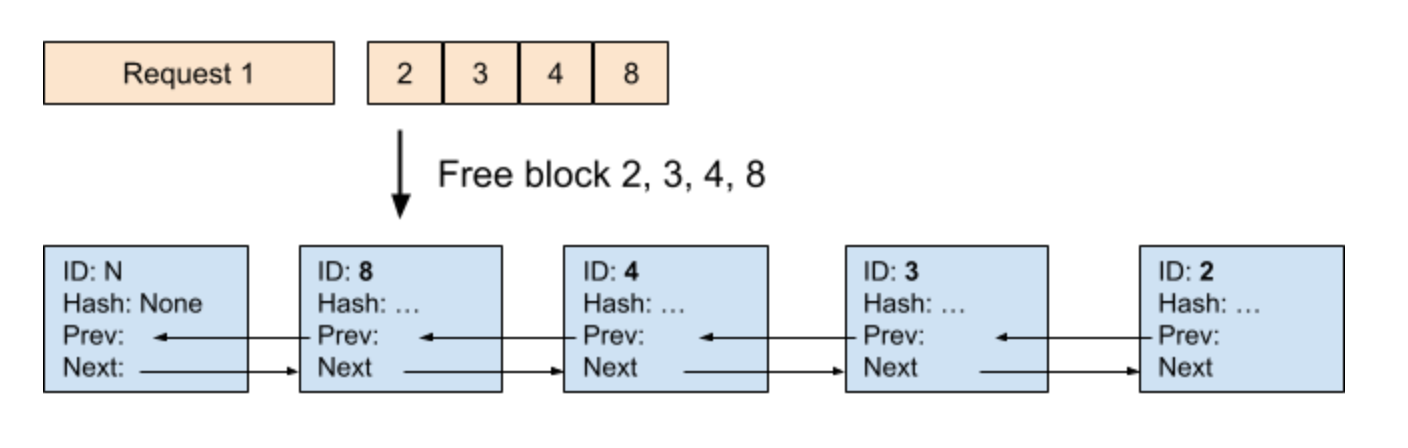
4.2.3.3 驱逐(LRU)
当 Free Block Queue 的队头 block(即最近最少使用的 block)仍处于缓存状态时,必须将其驱逐,以防止被其他请求继续使用。 具体的驱逐过程包括以下步骤:- 从 Free Block Queue 的队头弹出该 block,即要被驱逐的 LRU block;
- 从 Cache Blocks 中移除该 block 的 ID;
- 从 KVCacheBlock 移除该 block 对应的哈希值。
4.3 示例
在本示例中,假设每个 block 的大小为 4(即每个 block 可缓存 4 个 token),整个 KV Cache Manager 中共有 10 个 block。 时刻 1:缓存为空,一个新请求Request 0(ABCD|EFGH|IJKL|MNO) 到来。分配了 4 个 block,其中 3 个已填满并被缓存,第 4 个 block 部分填充,仅包含 3 个 token。所有 prompt tokens 都被调度。
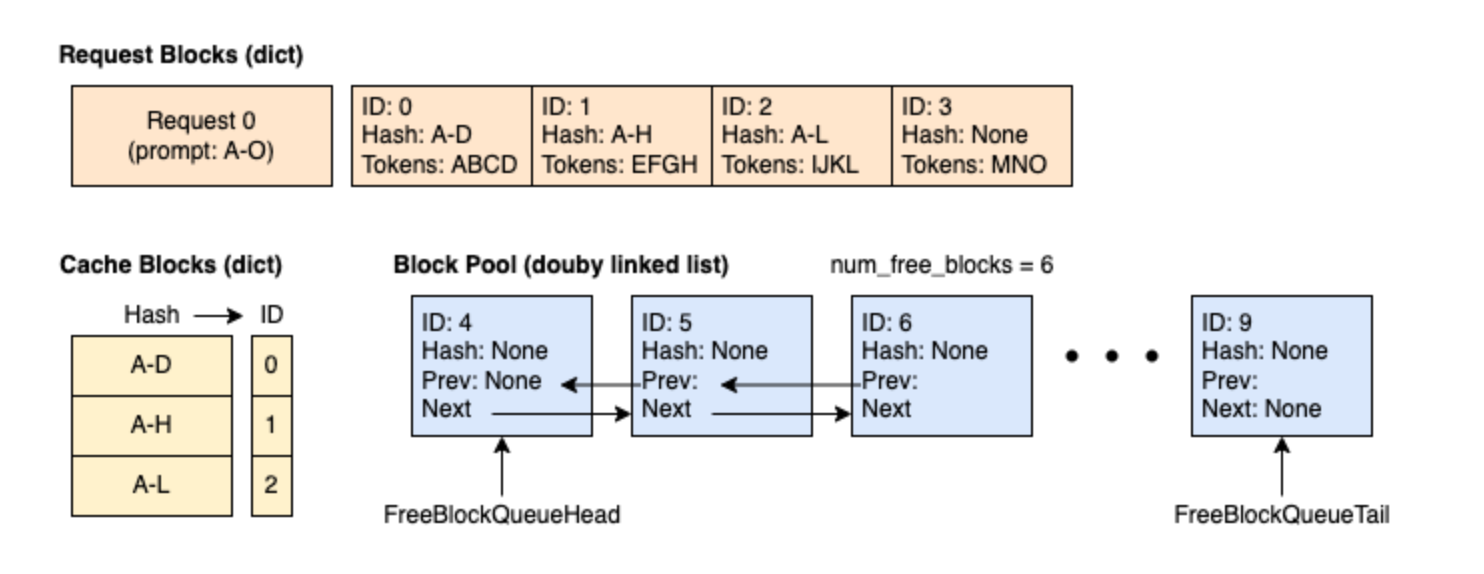
Block 的哈希值不是只基于自己的 token,而是包含了完整的前缀路径信息。例如,ID=2 的 hash 是 “A-L”,表示这是一个对 token时刻 3:Request 0 经过 2 次推理过程(1 次 prefill + 1 次 decode),达到下面这个状态。Request 0 将 block 3 填满,并请求一个新 block 以继续 decode。此时将 block 3 缓存,并分配 block 4。A到L的 prefix 路径(前缀+当前块)的唯一哈希标识。
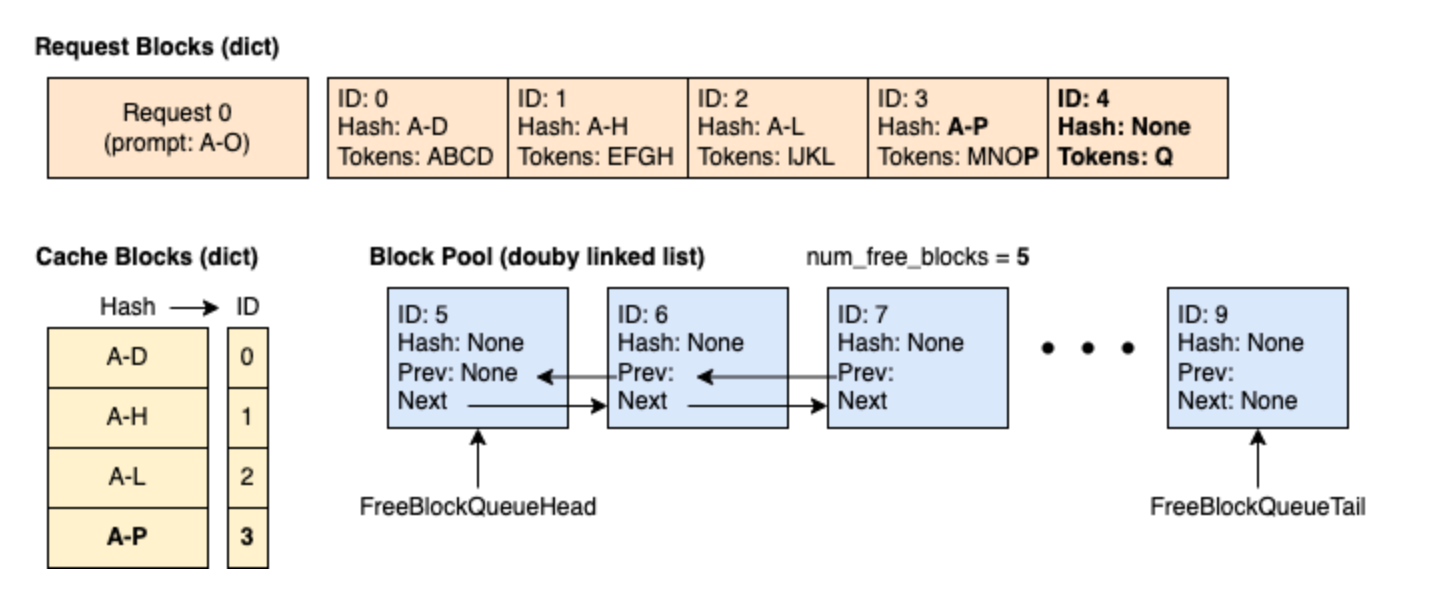 时刻 4:新的请求
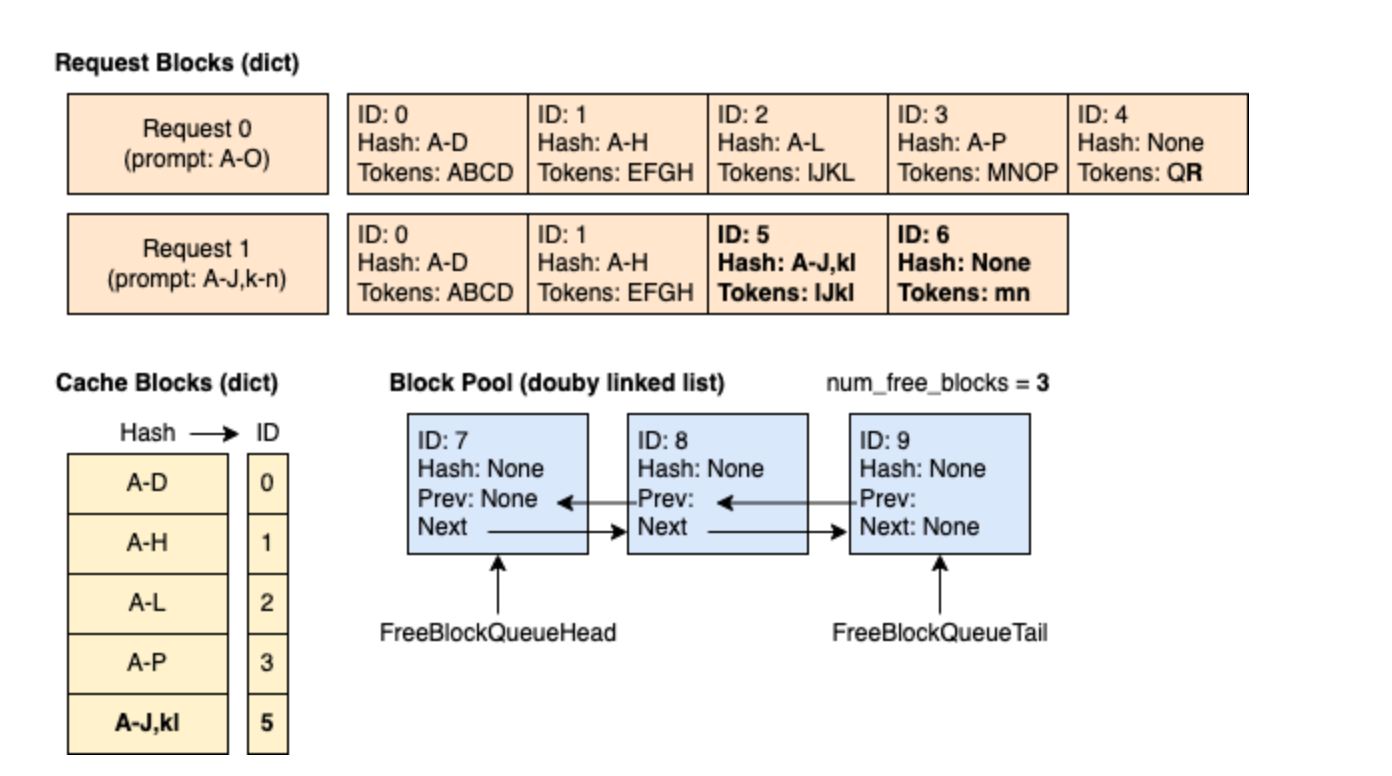
时刻 4:新的请求 Request 1(ABCD|EFGH|IJkl|mn) 带着 14 个 prompt token 到来,其中前 10 个 token 与 Request 0 相同。可以看到,只有前两个 block(共 8 个 token)命中缓存,因为第 3 个 block 仅匹配了其 4 个 token 中的前 2 个。Request 1 使用的 block 5 已经被 token 填满,因此被缓存。
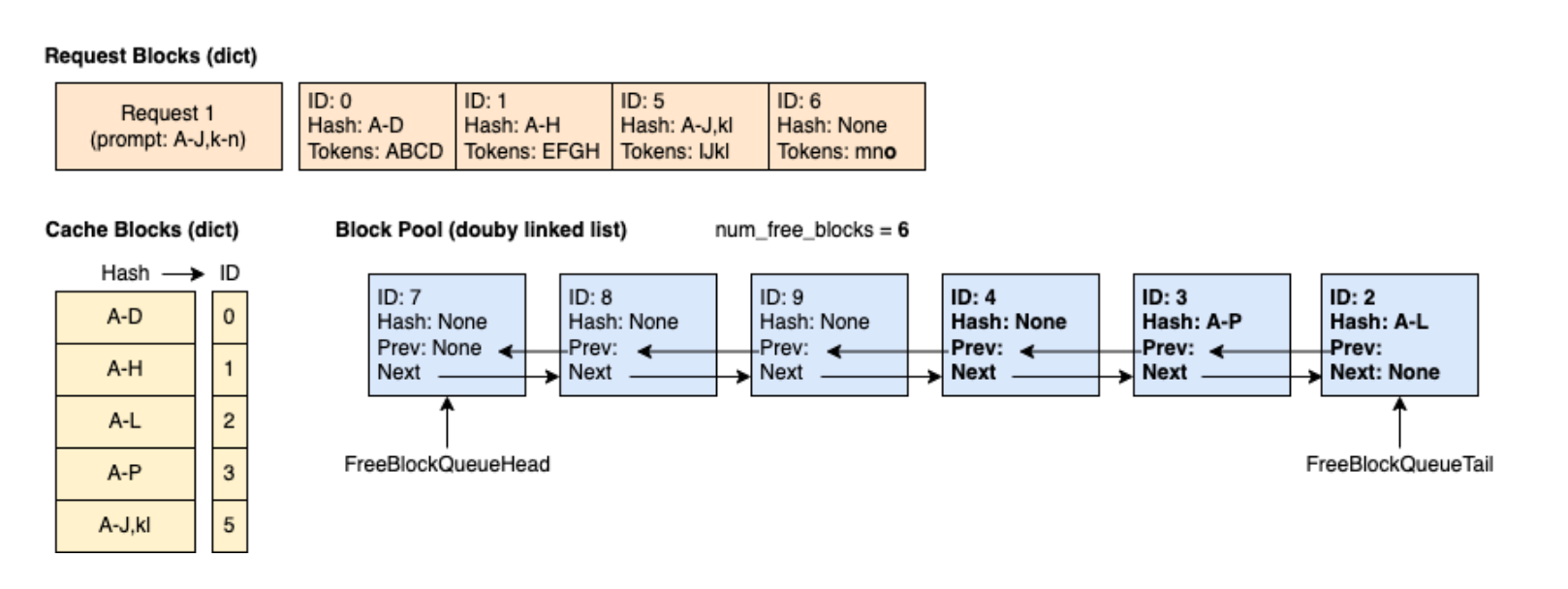
 时刻 5:Request 0 已完成并被释放。Block 2、3 和 4 按照逆序被添加到空闲队列中(但 Block 2 和 3 仍处于缓存状态)。Block 0 和 1 未被加入空闲队列,因为它们仍被 Request 1 使用。
时刻 5:Request 0 已完成并被释放。Block 2、3 和 4 按照逆序被添加到空闲队列中(但 Block 2 和 3 仍处于缓存状态)。Block 0 和 1 未被加入空闲队列,因为它们仍被 Request 1 使用。
 时刻 6:Request 1 推理完毕,同样需要释放掉相关资源。(原图有误,用红笔做了修正)
时刻 6:Request 1 推理完毕,同样需要释放掉相关资源。(原图有误,用红笔做了修正)
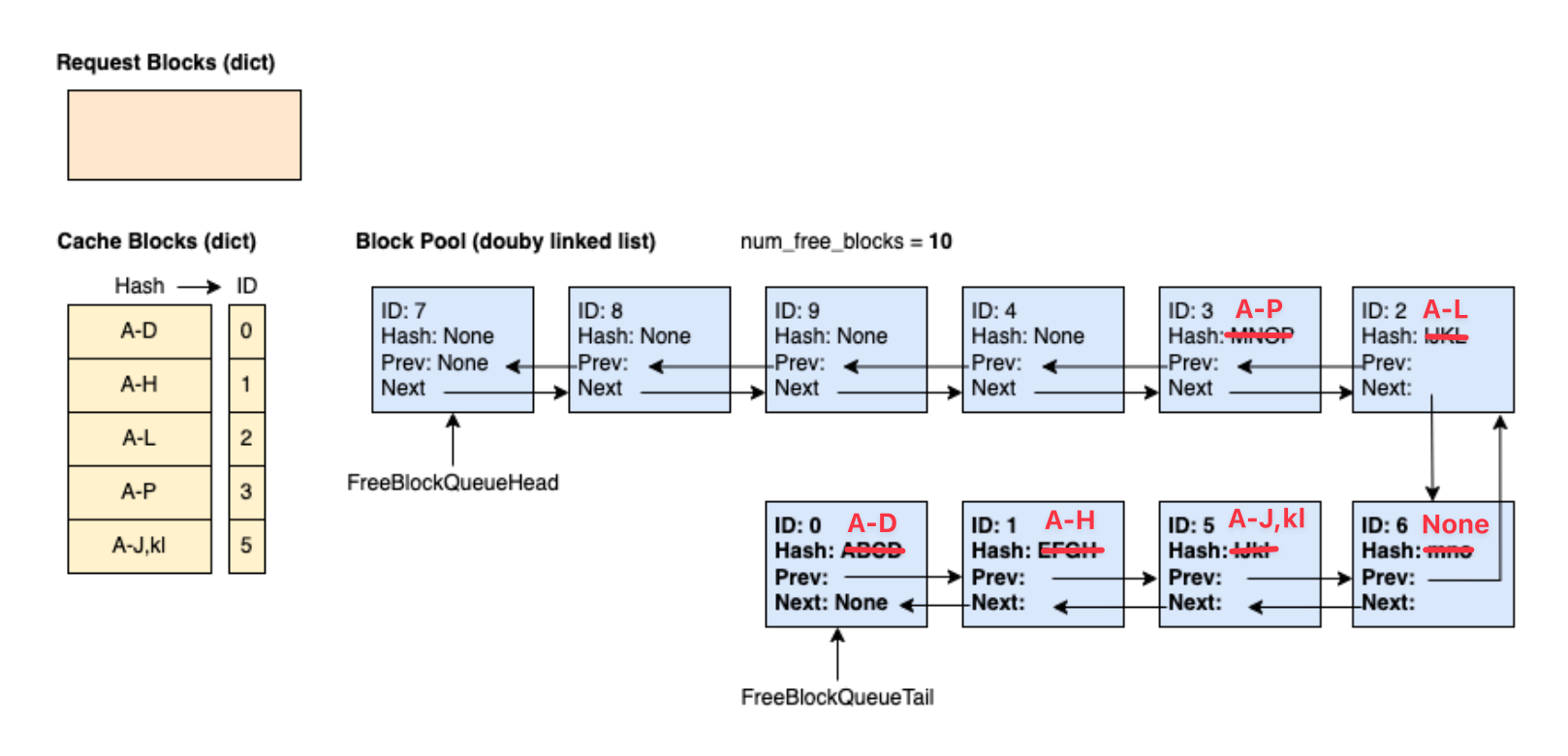 时刻 7:
时刻 7:Request 2(ABCD | EFGH | IJKL | 0-3 | 4-7 | 8-11 | 12-15 | 16) 带着 29 个 prompt token 到来,其中前 12 个 token 与 Request 0 完全相同。此时,前 3 个 block(block 0 ~ block 2)可以命中缓存,因此在正式分配新 block 之前,会先被 touch 并从 Free Block Queue 中移除。队列顺序从原本的 7 - 8 - 9 - 4 - 3 - 2 - 6 - 5 - 1 - 0 更新为 7 - 8 - 9 - 4 - 3 - 6 - 5。剩余 5 个所需 block 将从 Free Block Queue 头部依次分配,因此获取了 block 7、8、9、4 和 3。由于 block 3 仍处于缓存状态(哈希值 A–P),因此需要将其从缓存中驱逐。
这个例子可以帮助我们更好体会到不立刻驱逐 block、以及逆序 append block 的好处。
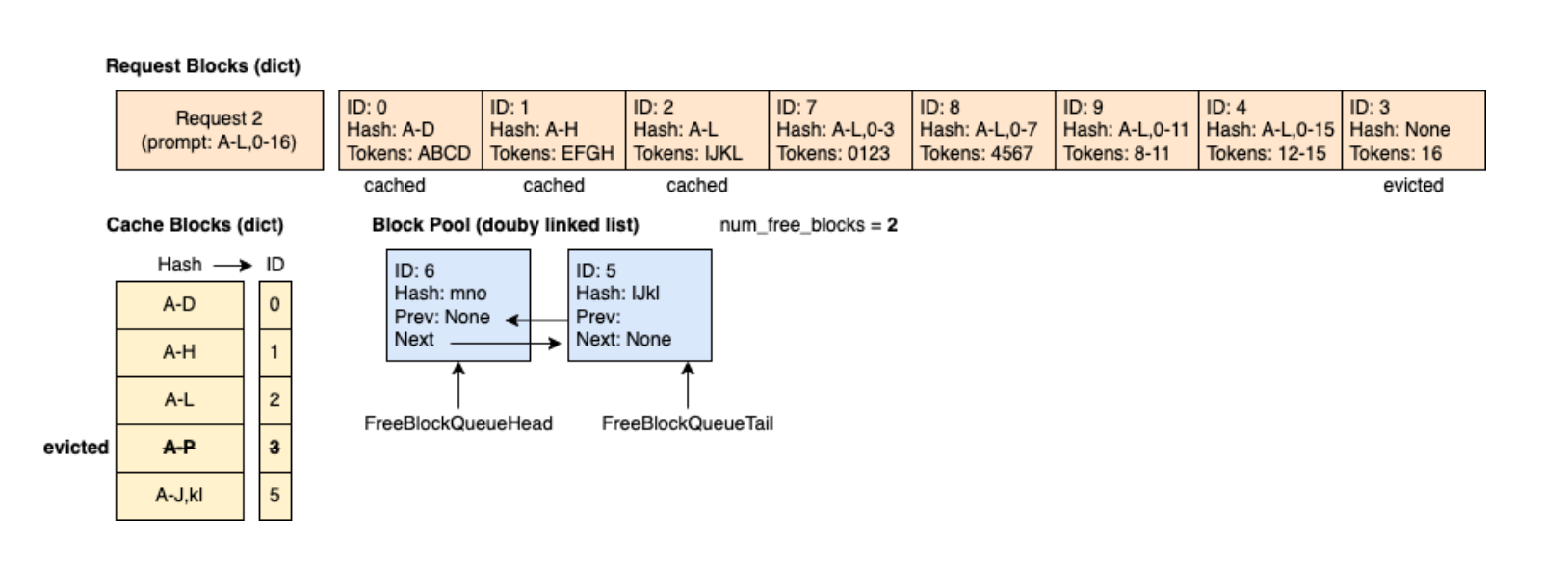
4.4 几个注意点
4.4.1 只缓存完整的 block
在 vLLM 中只缓存完整的 block,假如一个 block 没有被 token 完全填满,那么这个 block 就不会被缓存。4.4.2 哈希冲突
哈希键结构并不能 100% 避免冲突。从理论上讲,不同的前缀 token 仍然有可能产生相同的哈希值。为了在多租户环境中避免哈希冲突,建议使用 SHA256 作为哈希函数,而不是默认的内置哈希。自 vLLM v0.8.3 起已支持 SHA256,可通过--prefix-caching-hash-algo 命令行参数启用。但请注意,这会带来一定的性能开销:大约每个 token 增加 100–200 ns(对于 5 万个 token,大约增加 6 ms)。
4.4.3 前缀相同才能复用缓存
只有前缀相同的部分才能复用缓存,中间某一段相同是无法复用的。EFGH 部分的 token 内容完全一致,但 req2 不能复用 req1 的 EFGH block。
这是因为 Transformer 的每一层都具有前向依赖性——每个 token 的表示不仅依赖它自身,还受到前面所有 token 的影响。因此,只要前缀不同,即使中间的 token 完全相同,其 KV 缓存结果也会不同,无法共享。
5 Prefix Cache Aware Routing
Prefix Caching 虽然能有效减少单个实例内部的 KV Cache 重复计算,但在多副本部署场景下,仅靠单实例的缓存复用远远不够。即使多个请求具有相同前缀,仍可能被随机分配到不同实例,导致每个实例都重复计算并缓存相同前缀。Prefix Cache Aware Routing 则是为了解决这个问题,它能根据请求前缀的匹配情况,智能地将请求路由到已有缓存的 worker,从而在集群层面实现更高效的 KV Cache 利用率。 目前,已经有不少项目实现了 Prefix Cache Aware Routing,例如:- vLLM Production Stack 支持通过 LMCache 实现 Prefix Cache Aware Routing。另外 vLLM Production Stack 还有一个提案 RFC: prefix-cache-aware routing 中,其中实现了两种策略:基于 HashTrie 的匹配和基于 SimHash 的一致性哈希。其中,HashTrie 的方案在缓存命中率上表现更优。
- SGLang 则采用了一种基于请求历史构建 Radix Tree(基数树)的缓存感知路由策略。
- AIBrix 实现了一个分布式前缀缓存池,并对 vLLM 进行了定制化修改以支持从该缓存池加载缓存。在请求路由阶段,它的 Prefix Router 能最大化模型服务器上的前缀缓存命中率。目前支持两种策略:一种是类似 vLLM 的哈希匹配,另一种是类似 SGLang 的 Radix Tree 匹配。
- KubeAI 使用了一种带有负载边界的一致性哈希算法(CHWBL),它会对请求前缀(可配置长度)进行哈希,但可能因此牺牲一部分精度。当服务器负载过高时,它还会触发 “overflow” 策略将请求溢出到其他节点。
- Gateway API Inference Extension EPP(End-point Picker) 通过模拟模型服务器的缓存淘汰策略(如 LRU)构建一张所有后端服务器的近似前缀缓存索引表,用于指导后续请求的智能路由。关于 Gateway API Inference Extension 的详细解释可以参考:为 Kubernetes 提供智能的 LLM 推理路由:Gateway API Inference Extension 深度解析。
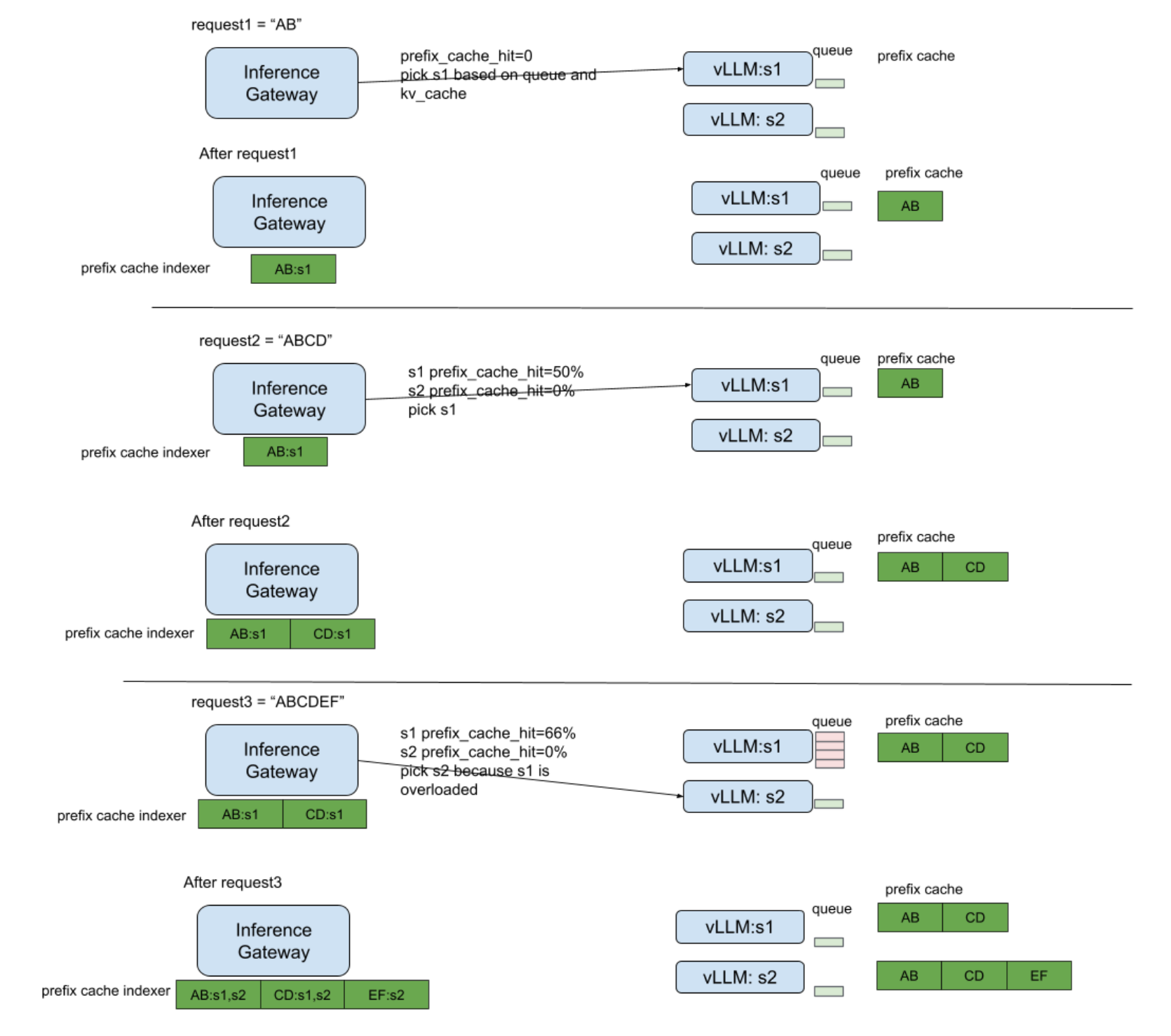 SGLang v0.4 为 LLM 推理引擎引入了具备缓存感知(cache-aware)能力的负载均衡器。该负载均衡器能预测各个 worker 的 prefix KV cache 命中率,并自动选择匹配率最高的 worker。测试显示其吞吐量最高提升 1.9 倍,缓存命中率改善达 3.8 倍,且工作节点越多优势越显著。下图展示了缓存感知负载均衡器与传统轮询负载均衡器在数据并行中的差异。缓存感知负载均衡器会维护一个与 worker 实际基数树近似的基数树。该树会进行惰性更新,几乎没有任何开销。
SGLang v0.4 为 LLM 推理引擎引入了具备缓存感知(cache-aware)能力的负载均衡器。该负载均衡器能预测各个 worker 的 prefix KV cache 命中率,并自动选择匹配率最高的 worker。测试显示其吞吐量最高提升 1.9 倍,缓存命中率改善达 3.8 倍,且工作节点越多优势越显著。下图展示了缓存感知负载均衡器与传统轮询负载均衡器在数据并行中的差异。缓存感知负载均衡器会维护一个与 worker 实际基数树近似的基数树。该树会进行惰性更新,几乎没有任何开销。
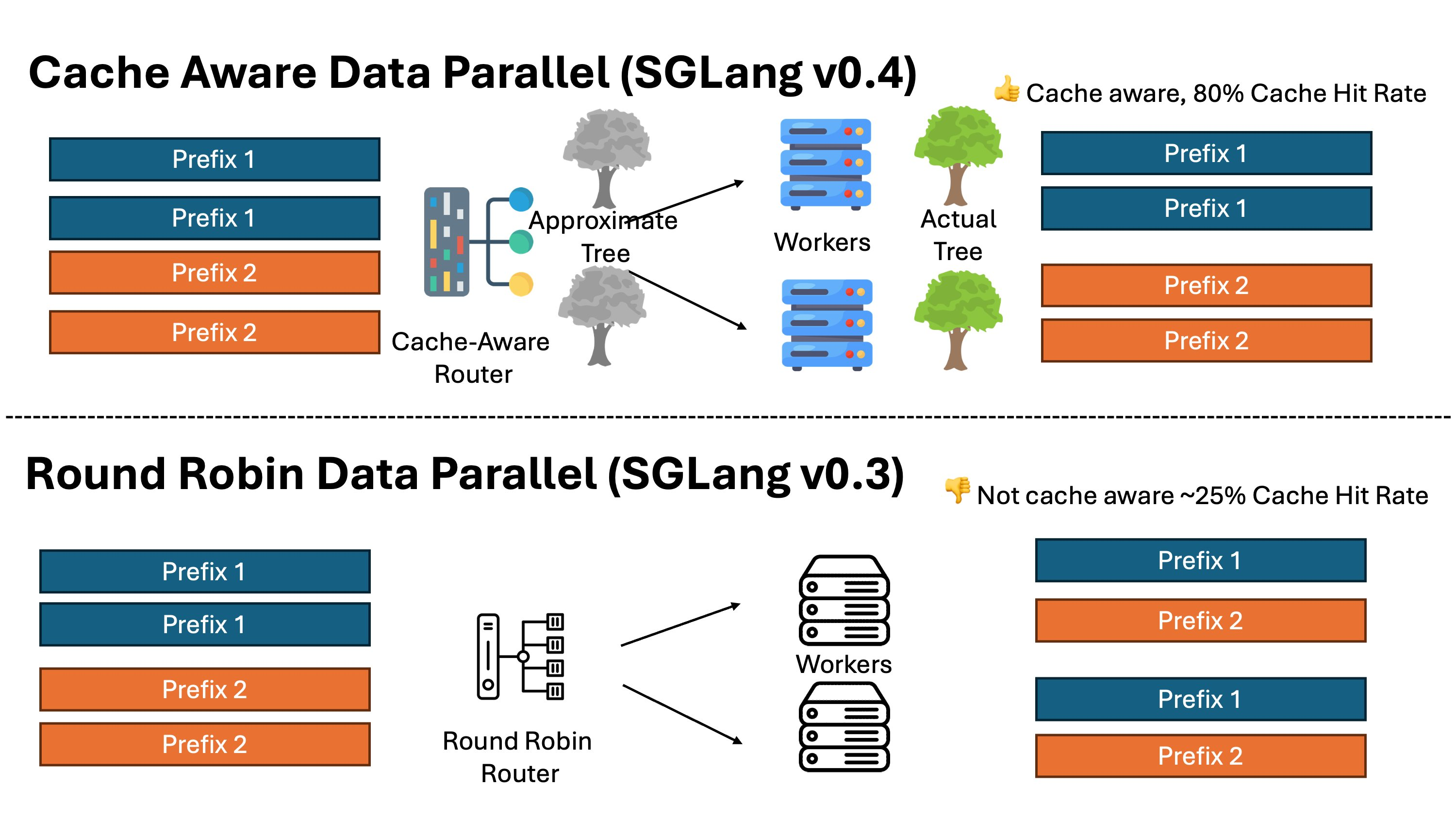 SGLang Router 的主要特性包括:
SGLang Router 的主要特性包括:
- 多节点支持:支持在多台机器上部署 worker,单个 Router 可连接分布式的多个 worker,便于水平扩展,同时在分布式环境中保持对缓存命中的感知能力。
- 感知缓存的路由机制:将请求优先发送到缓存命中率更高的 worker,并结合负载均衡策略避免负载不均。
- 免通信设计:worker 之间无需同步缓存状态,Router 通过跟踪请求历史来近似推断各个 worker 的缓存状态,而不是直接查询 worker 的实际缓存信息。
- 高性能实现:使用纯 Rust 编写,支持高并发,开销极低,性能相比基于 Python 的方案提升达 2 倍。
- 独立包形式发布:以
sglang-router包发布,提供 Python 接口,并配有 CLI 工具,方便用户快速上手使用。
sglang 和 sglang-router 包。
sglang_router.launch_server 一起启动 SGLang Router 和多个 worker。--dp-size 表示你要启动多少个独立的 worker 来进行数据并行(data parallel)。这里启动了 2 个 worker,因此你的服务器上需要 2 个 GPU。
sglang_router.launch_router。
6 总结
Prefix Caching 通过缓存并复用多个请求中相同前缀的 KV Cache,有效降低了大语言模型推理中的首 token 延迟和计算成本。与 PagedAttention 关注内存管理不同,Prefix Caching 专注于跨请求的计算复用,特别适用于多轮对话、few-shot 学习等场景。实现方式上,SGLang 采用基数树(RadixAttention)方案,而 vLLM 则使用基于哈希的方法。在分布式部署环境中,Prefix Cache Aware Routing 进一步优化了集群级别的缓存利用率,通过智能路由将请求发送到缓存命中率更高的节点。7 附录
7.1 Few-shot learning
Few-shot learning 就是通过在 prompt 中给模型少量任务示例,让模型在没有专门微调的情况下,理解并完成新任务。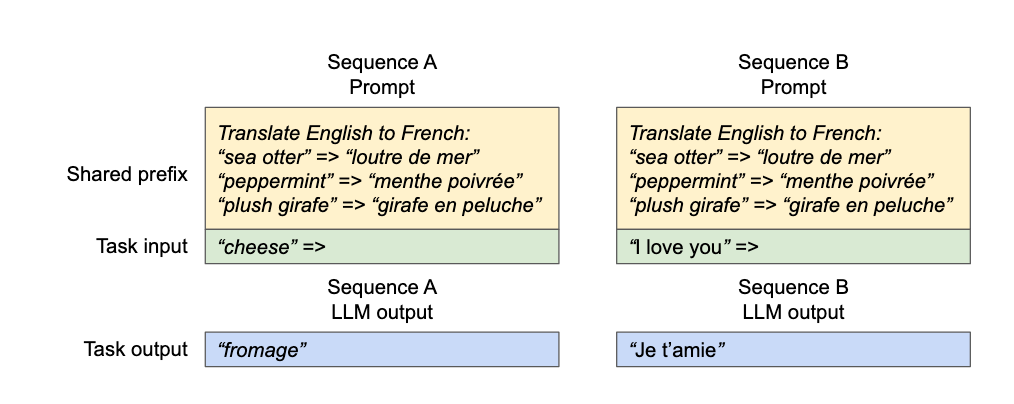
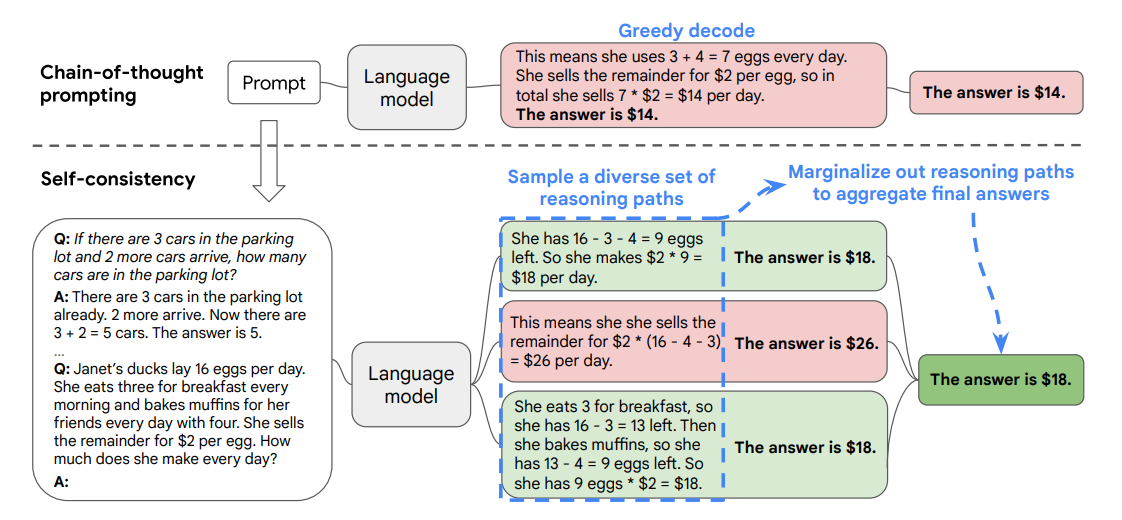
7.2 Self-consistency
Self-consistency 的概念来源于论文 Self-Consistency Improves Chain of Thought Reasoning in Language Models。 该方法基于这样的假设:在复杂推理任务中,从问题到唯一正确答案通常存在多种不同的推理路径。 其核心方案是用 self-consistency 解码策略替代传统的贪婪解码。具体做法是:对语言模型进行多次采样,生成多条不同的推理路径(即重复请求多次),然后根据这些路径的最终答案进行投票,选出最一致的答案作为最终输出。 Self-consistency 策略认为复杂推理任务往往可以通过多条路径获得正确解,因此通过抽样生成一个多样化的推理路径集合,并选取一致性最高的结果,有效降低了贪婪解码带来的随机性。 Self-consistency 的核心流程如下:- Step 1:使用思维链(Chain-of-Thought)提示,引导模型进行逐步推理;
- Step 2:对语言模型进行多次采样,生成多个推理路径;
- Step 3:对不同路径的最终答案进行投票,选择一致性最高的答案输出。
7.3 Chain of Thought
Chain of Thought (CoT) 是一种增强语言模型推理能力的技术,特别适用于需要多步推理的问题。通过在模型的提示中加入一系列的中间推理步骤,可以帮助模型进行复杂的推理任务,从而避免单纯的“直接回答”模式。CoT 使得模型能够理解并生成推理过程,而不是直接给出答案,从而提高其在复杂问题上的表现。 CoT 有两种应用模式: Few-Shot CoT 在 Few-Shot CoT 中,开发者给出一两个示例,在示例中明确展示如何进行思维链的推理。通过这些示例,模型能够学习如何通过逐步推理得出结论。 示例:7.4 Tree of Thought
Tree of Thought (ToT) 进一步扩展了 CoT 的理念,特别适用于需要多步骤推理的复杂任务。与 CoT 不同,ToT 框架不仅要求生成思维链,而是生成多个思维路径,并通过“思维树”进行探索。每个思维步骤都具有多个备选方案,模型会在这些方案中搜索最优解。 示例:- CoT:专注于引导模型逐步推理,强调思考的过程,可以通过单一路径进行推理并得出答案。
- ToT:在 CoT 的基础上,加入了多条推理路径的选择,使得模型能够在多条思维路径中搜索最优解。ToT 更适合处理复杂问题,尤其是需要多个选择和深度探索的场景。
7.5 前缀树(Trie)和 基数树(Radix Tree)
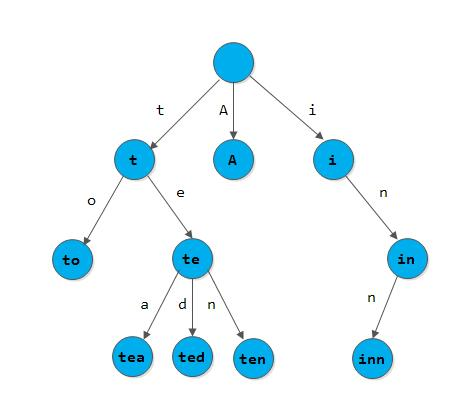
基数树(Radix Tree)和前缀树(Trie)的区别主要在于结构的紧凑性和节点的表示方式:- 前缀树(Trie) 是一种按字符逐层拆分的树结构,每个节点只存储一个字符,路径上的字符连接起来表示字符串。它的层级深度通常等于字符串的长度,节点的子节点数较多(比如 26 个英文字母),空间利用率较低,但查找操作简单直观。Trie 这个术语来自于 retrieval。根据词源学,trie 的发明者 Edward Fredkin 把它读作
/ˈtriː/,不过,大部分人把它读作/ˈtraɪ/。
- 基数树(Radix Tree) 也称为压缩前缀树,是对 Trie 的空间优化。它将 Trie 中只有一个子节点的路径节点合并成一个节点,节点上存储的是一段字符序列(而非单个字符),从而减少树的深度和节点数量,提高空间利用率。基数树的边可以表示多个字符,查找时按块比较,适合处理长字符串和有长公共前缀的集合。
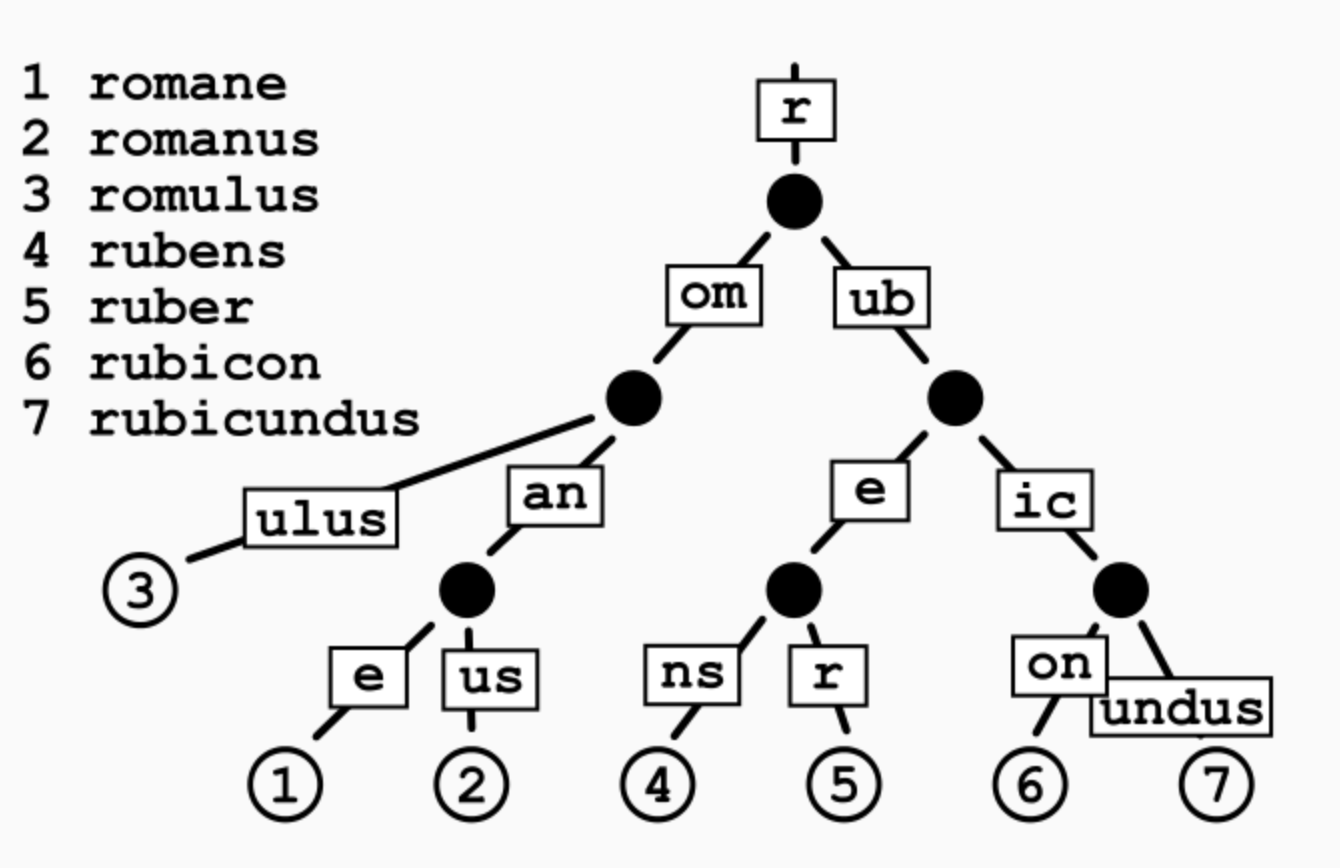 因此,基数树可以看作是前缀树的一种压缩和优化版本,兼具 Trie 的前缀查找特性和更高的空间效率。
因此,基数树可以看作是前缀树的一种压缩和优化版本,兼具 Trie 的前缀查找特性和更高的空间效率。
8 参考资料
- 图解Vllm V1系列5:调度器策略(Scheduler):https://zhuanlan.zhihu.com/p/1908153627639551302
- LLM Load Balancing at Scale: Consistent Hashing with Bounded Loads:https://www.kubeai.org/blog/2025/02/26/llm-load-balancing-at-scale-chwbl/
- SGLang Router for Data Parallelism:https://docs.sglang.ai/router/router.html
- SGLang v0.4: Zero-Overhead Batch Scheduler, Cache-Aware Load Balancer, Faster Structured Outputs:https://lmsys.org/blog/2024-12-04-sglang-v0-4/
- vLLM的prefix cache为何零开销:https://zhuanlan.zhihu.com/p/1896927732027335111
- Fast and Expressive LLM Inference with RadixAttention and SGLang:https://lmsys.org/blog/2024-01-17-sglang/
- EP05-vLLM源码讲解直播笔记-Prefix Caching:https://kevincheung2259.github.io/2025/04/16/vLLM-EP05/
- [Prefill优化][万字]🔥原理&图解vLLM Automatic Prefix Cache(RadixAttention): 首Token时延优化:https://zhuanlan.zhihu.com/p/693556044
- 图解Vllm V1系列6:KVCacheManager与PrefixCaching:https://mp.weixin.qq.com/s/Ta7jh-2g7lAEiFOjcSJHVw
- 图解大模型计算加速系列:vLLM源码解析3,Prefix Caching:https://mp.weixin.qq.com/s/bAY4OGqQlEeBaITIwxQEuw
- Prefix Cache Aware Proposal:https://github.com/kubernetes-sigs/gateway-api-inference-extension/issues/498
- AIBrix v0.3.0 发布:KVCache 多级卸载、前缀缓存、公平路由与基准测试工具:https://mp.weixin.qq.com/s/1__uUX7xMoQ6q7HFXrP2Bw
- 大模型推理加速与KV Cache(五):Prefix Caching:https://zhuanlan.zhihu.com/p/739669365
- CoT系列-Self-Consistency(year 2022.Mar, Google):https://zhuanlan.zhihu.com/p/609739922
- PR [Experimental] Prefix Caching Support:https://github.com/vllm-project/vllm/pull/1669
- PR Add Automatic Prefix Caching:https://github.com/vllm-project/vllm/pull/2762
- SgLang代码细读-3.Cache:https://www.cnblogs.com/sunstrikes/p/18891538