录屏回看
本章概要
2024 年底,中国初创公司 DeepSeek 用 2048 块受出口管制限制的 H800 GPU,训练出了 671B 总参数、每个 token 激活 37B 参数的 MoE 模型 DeepSeek-V3。根据其技术报告,DeepSeek-V3 在语言理解、阅读理解和推理等多项标准化测试上接近甚至部分超过 GPT-4,而完整训练仅需 278.8 万 H800 GPU 小时。假设 H800 的租赁价格为每小时 2 美元,总训练成本仅为 557.6 万美元(该数字仅包含正式训练,不含前期架构探索和消融实验)。 随后推出的推理模型 DeepSeek-R1 进一步逼近 OpenAI o1 的水平。消息一出,NVIDIA 股价单日跌了约 17%,据 路透社报道市值蒸发近 5930 亿美元,创下华尔街单只股票单日最大市值损失纪录。 作为对比,训练 GPT-4 估计花了约 1 亿美元,训练 Gemini Ultra 估计花了约 1.9 亿美元。在这个规模上,系统效率每提高一点,省下来的就不是小数目。而 DeepSeek 在硬件更受限的条件下,用不到 GPT-4 训练成本 1/18 的预算达到了相近效果,靠的正是硬件、软件和算法的协同设计。 本章先从 DeepSeek 在 H800 约束下的模型与系统优化讲起,包括 MoE 架构、DeepSeek-R1 以及 FlashMLA、DeepGEMM、DeepEP、3FS 等工程创新;再把视角扩展到万亿到百万亿参数模型面临的计算与内存瓶颈,以及 GB200、Vera Rubin 等机架式 AI 超级计算机如何提供系统级支撑;最后通过 FlashAttention、MLA 和低精度量化这些例子,说明大模型性能和成本的上限并不只取决于单个算法或单代 GPU,而取决于硬件、软件和算法能否围绕同一组瓶颈协同演进。章节详解
1. DeepSeek:硬件受限下的极致优化
2024 年底,中国初创公司 DeepSeek 在没有最新 NVIDIA GPU 的情况下,训练出了接近前沿水平的大语言模型,震动了整个 AI 社区。1.1 硬件约束
由于美国出口管制,DeepSeek 无法获得顶级的 Blackwell(B200、B300)或完整版 Hopper(H100、H200)GPU,只能使用出口合规的 H800。下面这张表可以看出 H800 和其他型号的差距:峰值算力单位
峰值算力单位
- T(Tera)=
- FL(Floating-Point)= 浮点
- OPS(Operations Per Second)= 每秒运算次数
数据精度
数据精度
精度格式一览
GPU 规格表里会出现多种数值精度格式,它们决定了每个数字占多少位、能表示多大范围和多高精度。位数越少,每个周期能算的数越多,TFLOPS 越高,但精度越低。浮点数的存储结构
浮点数的存储结构与科学计数法相同,由 符号位、指数 (exponent) 和 尾数 (mantissa) 三部分组成:(-1)^符号位 × 1.尾数 × 2^指数- 指数位越多 → 能表示的数值范围越大,但不影响精度
- 尾数位越多 → 有效数字越多、精度越高,但不影响范围
4.8125 为例:- 符号位 =
0:表示这个数是正数。 - 指数位 =
10000001₂ = 129:FP32 存的不是“真实指数”,而是“真实指数 + 偏移量(bias)”。FP32 的指数有 8 位,所以偏移量是 。因此这里的真实指数 = 129 - 127 = 2。这样设计的好处是,指数即使有正有负,存进硬件后也始终是非负整数,便于存储和比较。其他格式同理:如果指数位为 ,偏移量通常是 。 - 尾数位 =
0011010...:这里只存小数部分,前面的1.默认省略不写(称为“隐含前导 1”)。所以完整尾数其实是1.001101₂,换成十进制约为 1.203125。 - 最终值 = = 4.8125。
低精度格式的缩放机制
低精度格式(FP8、FP4)的刻度很粗,需要 scaling factor 来补偿。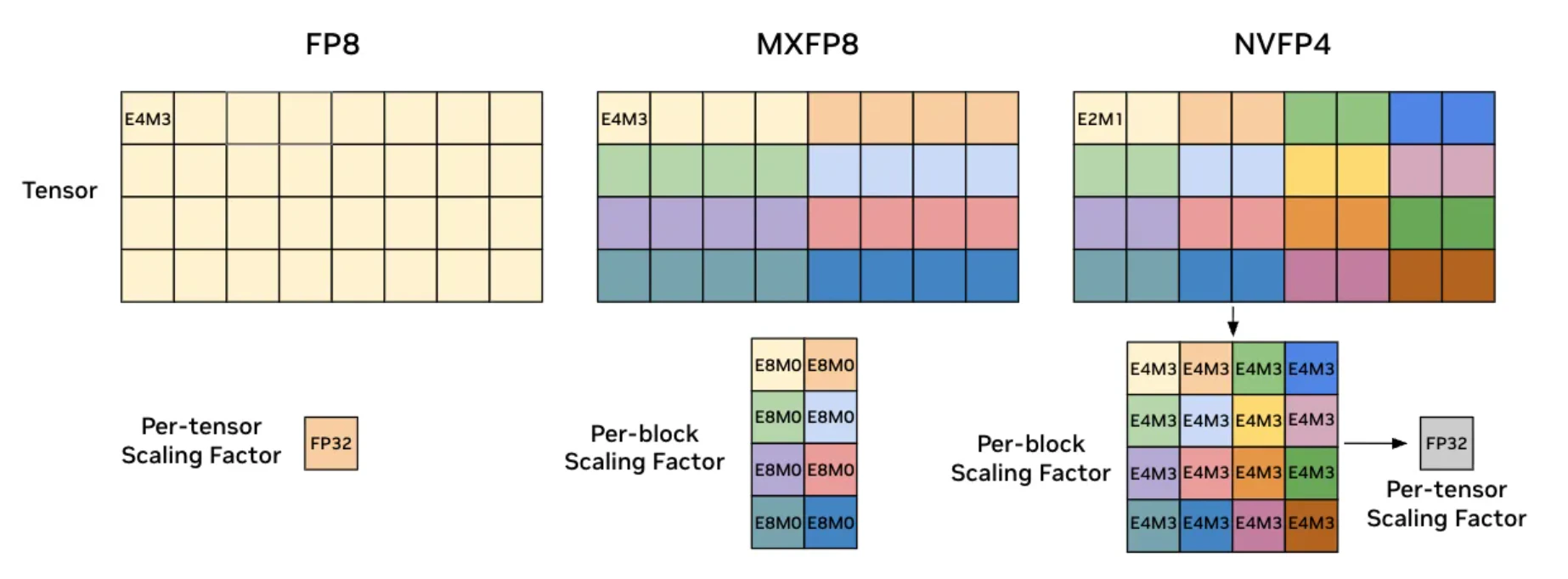
FP8、MXFP8、NVFP4 缩放策略对比。E = exponent(指数),M = mantissa(尾数)
- 传统 FP8:所有物品共用一个秤(per-tensor scaling),量程必须覆盖最重的东西,因此称很轻的物品时精度会明显变差
- MXFP8:把物品分成很多小组(通常每 32 个一组),每组发一个秤,量程根据这组物品的大小单独调(per-block scaling)。重的一组用大量程,轻的一组用小量程,因此每组内部都能称得更准
- NVFP4:秤的刻度更粗了(4 bit),只靠一个秤已经不够,所以要用两层秤:先给每个小组一个局部秤调组内相对大小(per-block E4M3 scaling),再给整批物品一个总秤校正整体范围(per-tensor FP32 scaling)
- Understanding the FP64, FP32, FP16, BFLOAT16, TF32, FP8 Formats — 各种精度格式的位布局和对比
- Floating-Point 8: An Introduction to Efficient, Lower-Precision AI Training — NVIDIA 官方 FP8 技术博客,解释 E4M3/E5M2 变体和 scaling 策略
- Accelerating AI Training with NVIDIA TF32 Tensor Cores — NVIDIA 官方 TF32 技术博客
- Using NVFP4 Low-Precision Model Training — NVIDIA 官方 FP4 训练技术博客
- From FP8 LLM Training to Inference: Language AI at Scale — GTC 2025 演讲,FP8 在大语言模型训练和推理中的实践
Sparse 与 Dense 矩阵乘法
Sparse 与 Dense 矩阵乘法
- 只存储非零元素(数据量减半,K → K/2)以及一组 2-bit 索引记录非零元素在原始 4 个位置中的偏移。
- Tensor Core 根据索引从 B 矩阵的 K 个元素中选出对应的 K/2 个元素,只对它们做乘累加。
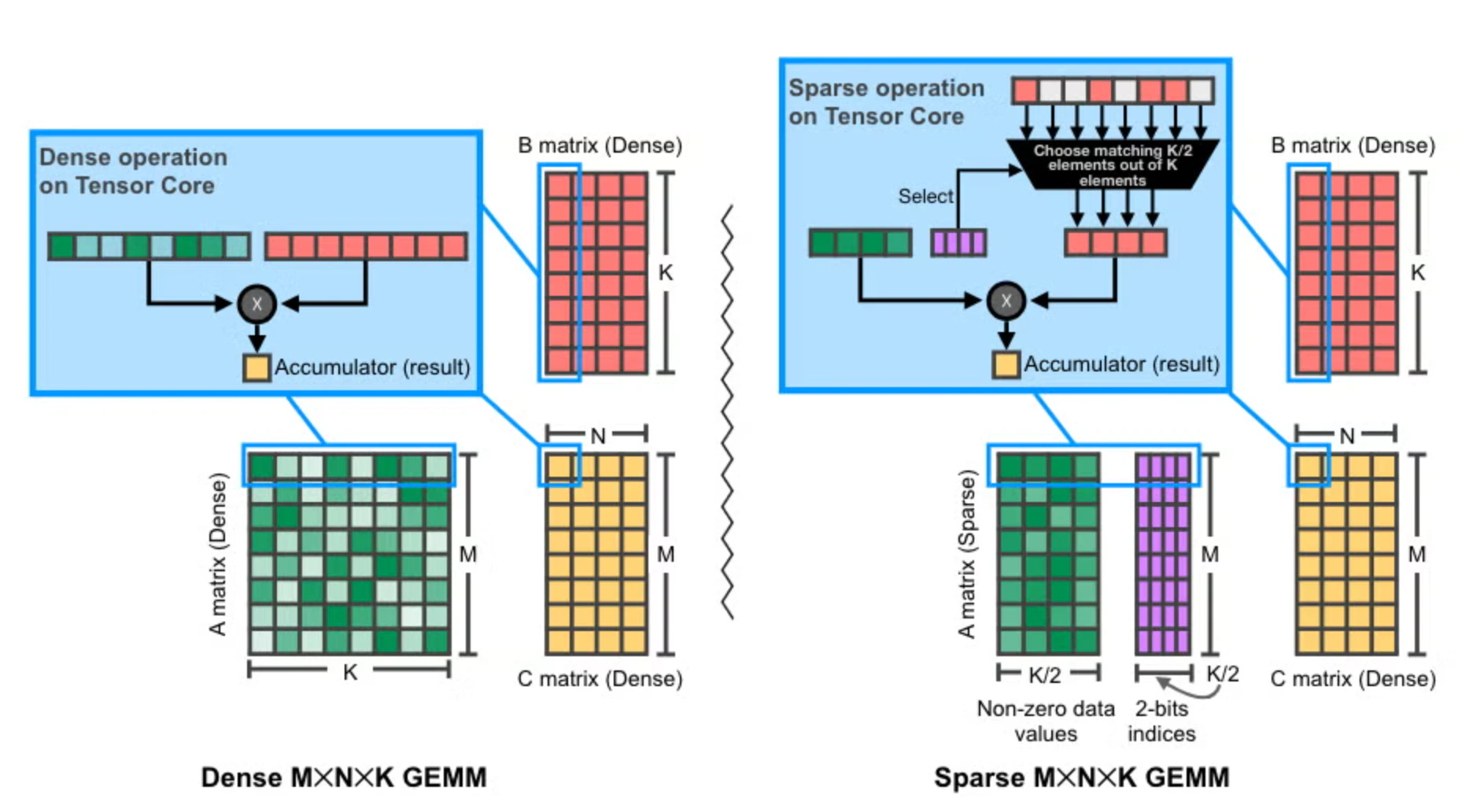
NVIDIA GPU 上 2:4(稀疏)矩阵乘法的示意图
- Structured Sparsity in the NVIDIA Ampere Architecture — NVIDIA 官方博客,介绍 2:4 稀疏的硬件支持与应用
- Accelerating Sparse Deep Neural Networks — NVIDIA 论文,系统评估 2:4 稀疏在各类网络上的精度影响,并给出剪枝与重训练的最佳实践
- Accelerating Neural Network Training with Semi-Structured (2:4) Sparsity — PyTorch 博客,动态稀疏训练的实现与加速效果
- Exploiting Ampere Structured Sparsity with cuSPARSELt — cuSPARSELt 库的使用
SXM、HGX、NVL 是什么
SXM、HGX、NVL 是什么
PCIe 插槽,而是把 GPU 直接安装到 HGX / DGX 底板上。在这类系统里,SXM GPU 通常配合 NVLink 和 NVSwitch 使用,因此往往有更高的供电、更强的散热,以及更高的 GPU 间互连带宽。HGX:服务器主板 / 平台HGX 是 NVIDIA 的多 GPU 服务器参考平台。常见的 HGX H100 / HGX H200 底板会集成 8 块 SXM GPU,并通过 NVSwitch 把它们全互连。Dell、HPE、浪潮等厂商通常在 HGX 底板之外再配上 CPU、内存和网卡,组装成完整的 AI 服务器。NVL:NVLink 互连版本NVL 代表 NVLink,H100 NVL 是把两块 H100 通过 NVLink 桥接焊在同一张 PCIe 大卡上,对外表现为单张卡。 这样做的好处是:不需要安装专用 HGX 主板就能拿到 NVLink 互连和更大的显存(两张合计 188 GB HBM3),适合快速部署在现有服务器基础设施上,尤其适合 LLM 推理场景。 NVL 版的核心性能接近 SXM,但 NVLink 带宽略低(600 GB/s vs SXM 的 900 GB/s)。1.2 DeepSeek-V3 的 MoE 架构
DeepSeek‑V3 是一个约 671B 参数的混合专家(MoE)模型,但每个输入 token 只会激活约 37B 参数:每层包含 1 个共享专家和 256 个路由专家,每个 token 从中选出 8 个路由专家,再加上共享专家,一共使用 9 个活跃专家。这样一来,激活参数量约占总参数的 5.5%,在保持大模型容量的同时显著降低了单 token 的实际计算开销。1.3 DeepSeek-R1:推理模型
在 DeepSeek-V3 基础上,团队进一步构建了专门的推理模型 DeepSeek-R1,路线接近 OpenAI 的 o1/o3 系列。与依赖大量人工反馈做后训练不同,R1 采用了 DeepSeek 开创的“冷启动”策略:只使用少量监督数据,把重点放在强化学习上,直接将思维链推理能力嵌入模型。这种做法同时压低了训练成本和训练时间,也说明软件和算法设计足够聪明时,可以在相当程度上弥补硬件瓶颈。1.4 DeepSeek 工程创新
DeepSeek 的工程团队几乎把整条系统栈都做了针对 H800 约束的重优化:从 attention kernel、FP8 矩阵乘法和 MoE 通信,到专家负载均衡、双向流水线并行,再到底层文件系统。2. 迈向百万亿参数模型
模型规模正在从千亿向万亿参数迈进。以下是 2026 年主流开源 LLM 中的千亿至万亿级模型(均为 MoE 架构):2.1 计算挑战
一个 dense 的 100 万亿参数模型,在约 29 万亿 token 上训练,需要约 1.2 × 10²⁹ FLOPS。这是一个天文数字——即使是 exascale 系统也需要数千年的 GPU 时间来完成一次训练。什么是 Exascale 系统
什么是 Exascale 系统
2.2 内存挑战
以 FP16(每参数 2 字节)存储 100 万亿参数,仅模型权重就需要约 182 TB 显存。单块 B200 GPU 有 192 GB HBM3e,仅加载模型就需要约 1,000 块 B200(约 125 个 8-GPU 节点)。若使用 B300(288 GB),则需约 700 块。这还只是模型权重——不包括激活值内存、优化器状态和输入数据,实际需求更大。B200 / B300 显存口径说明
B200 / B300 显存口径说明
HGX B200 / HGX B300 的单 GPU 口径,因此显存写成 180 GB 和 270 GB;这里这句沿用原书引用的 DGX B200 / DGX B300 口径,因此写成 192 GB 和 288 GB。两者对应的是不同系统形态下的规格,所以数字不完全一致。可参考 Blackwell Ultra Datasheet 和 NVIDIA DGX B300 Datasheet。2.3 MoE 是关键路径
LLM 的基本架构是 Transformer,由一系列 Transformer 模块像搭积木一样堆叠而成。每个模块内部有两个核心组件:- Attention:负责词与词之间的相互关联(“这句话里哪些词和当前词有关”)
- FFN(Feed-Forward Network):负责对每个词本身的深度理解(“这个词在当前语境下是什么意思”)
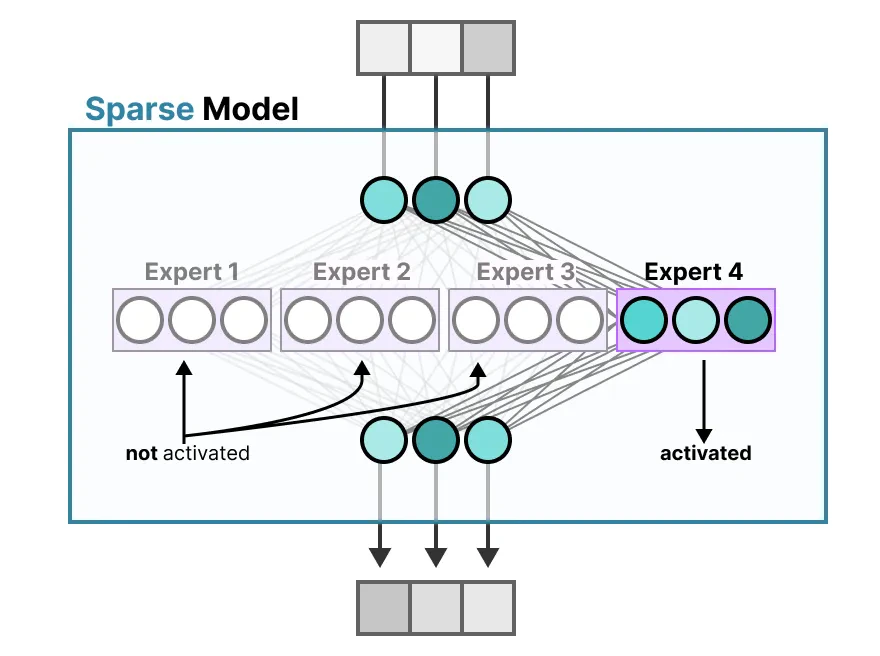
4 个专家中只有 Expert 4 被激活(高亮),其余 3 个不参与当前 token 的计算
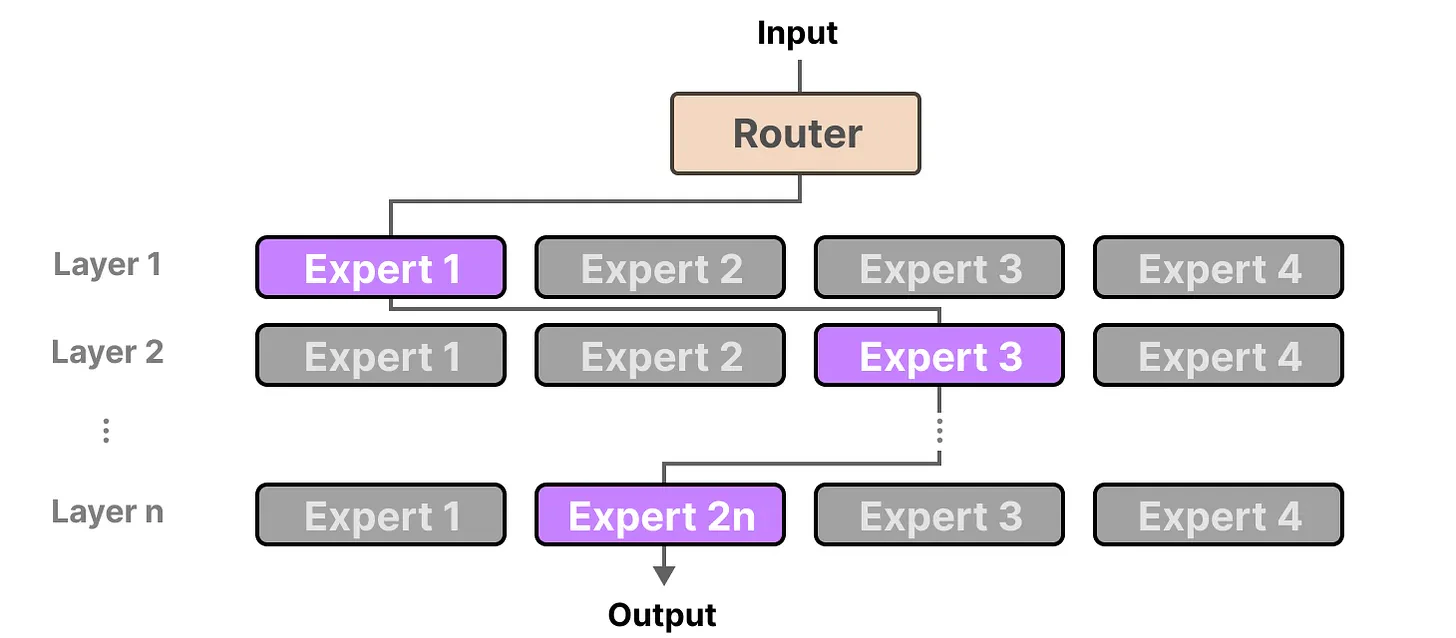
每层的路由器独立选择专家:Layer 1 选中 Expert 1,Layer 2 选中 Expert 3,Layer n 选中 Expert 2n
2.3.1 从 Switch Transformer 到 DeepSeek MoE
Switch Transformer(Google, 2021)是最早的大规模实践,采用 top-1 路由(每个 token 只选 1 个专家),训练速度达到同等 dense 模型的 7 倍。但它有一个缺陷:每个专家都要各自学一遍通用能力(语义理解、语法处理等),大量参数容量浪费在重复学习上。 DeepSeek MoE 的改进是两个:- 共享专家:划出一部分专家,所有 token 都经过它们,专门学习通用能力。其余专家只需在通用能力的基础上各自深耕专业领域。
- 细粒度专家:把每个专家的粒度做细、数量做多(DeepSeek-V3 用 256 个 routed expert 选 8 个),让专业分工更精细。
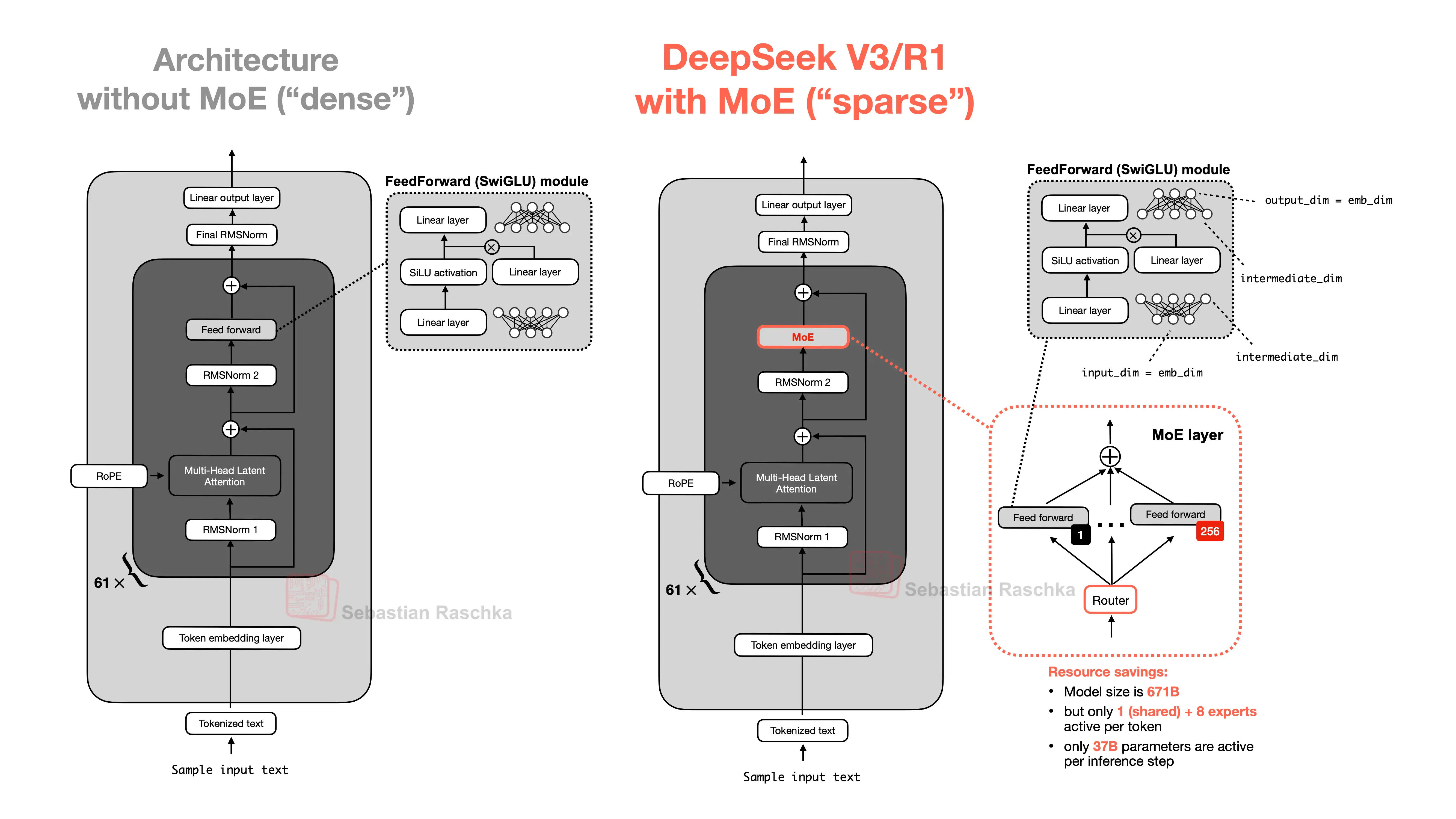
左:dense 架构,每层使用单个 FFN。右:DeepSeek V3/R1 的 MoE 架构,MoE 层包含 1 个 shared expert + 256 个 routed expert,每个 token 只激活 9 个专家(1 个 shared + 8 个 routed),总参数 671B,活跃参数仅 37B。
2.3.2 MoE 推理优化
1. 算子效率:更快的 CUDA kernel 通用的 NCCL collective 对 MoE 的 all-to-all 通信模式并非最优。DeepSeek 的 DeepEP 提供了专门为 MoE 优化的高效 all-to-all 通信 kernel。Perplexity 开源的 pplx-kernels 同样针对 MoE expert parallelism 场景,支持 NVLink、IBGDA、IBRC 等多种传输层,并在 kernel 层面提供通信与计算重叠的底层能力。IBGDA 与 IBRC
IBGDA 与 IBRC
- IBGDA(InfiniBand GPU-Direct Async):GPU 直接向网卡发起 RDMA 操作,完全绕过 CPU,延迟最低
- IBRC(InfiniBand Reliable Connection):传统模式,需要 CPU 代理线程协调 GPU 和网卡之间的通信,延迟较高
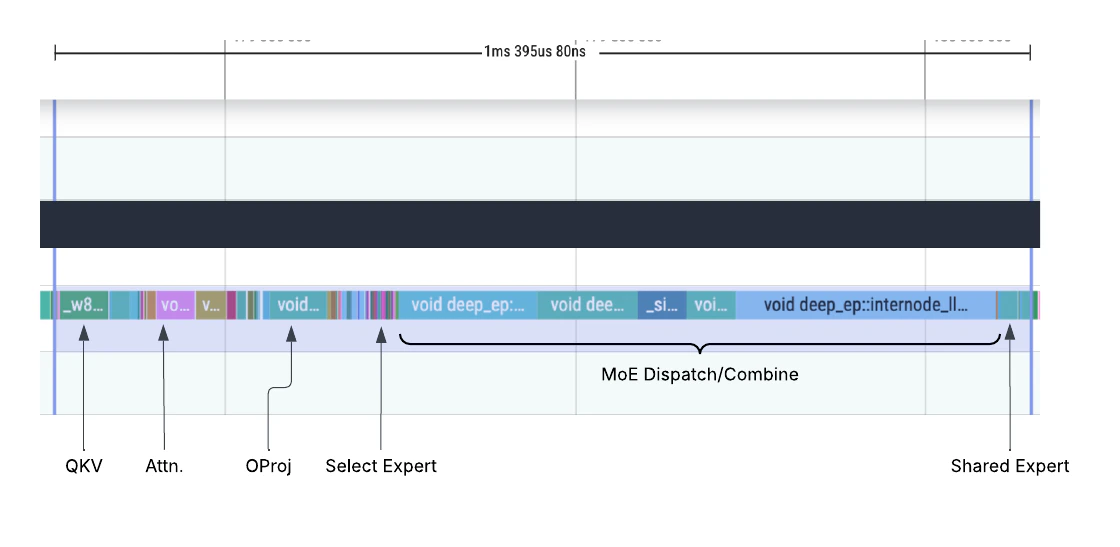
未启用 DBO:MoE Dispatch/Combine 的 collective communication 耗时远超实际计算。
- 线程 0 完成 dispatch(send + recv)后立刻让出给线程 1
- 线程 1 开始自己的 dispatch 通信,同时线程 0 收到的 token 在 SM 上做专家计算
- 线程 1 完成 dispatch 后让回给线程 0 做 combine
- 线程 0 完成 combine 后让出给线程 1 做 combine,如此交替
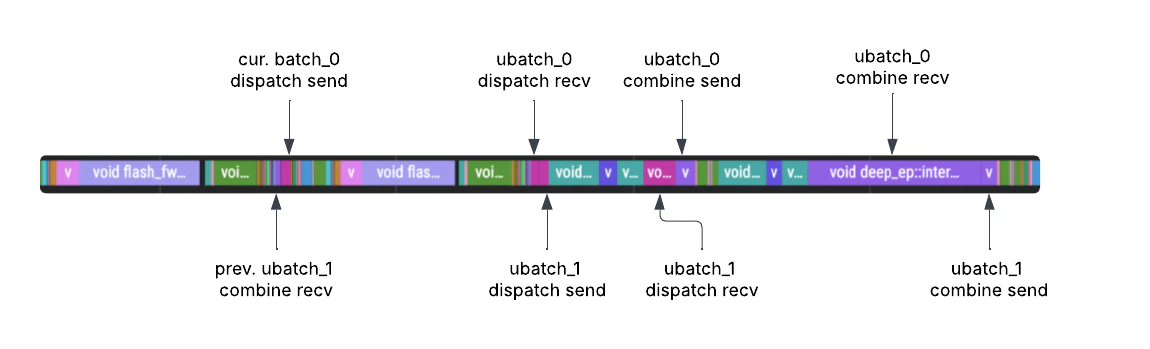
启用 DBO:两个 micro-batch 线程交替执行 dispatch 和 combine,通信与计算重叠,GPU 利用率显著提升。
MoE 在 Expert Parallelism 下的通信流程
MoE 在 Expert Parallelism 下的通信流程
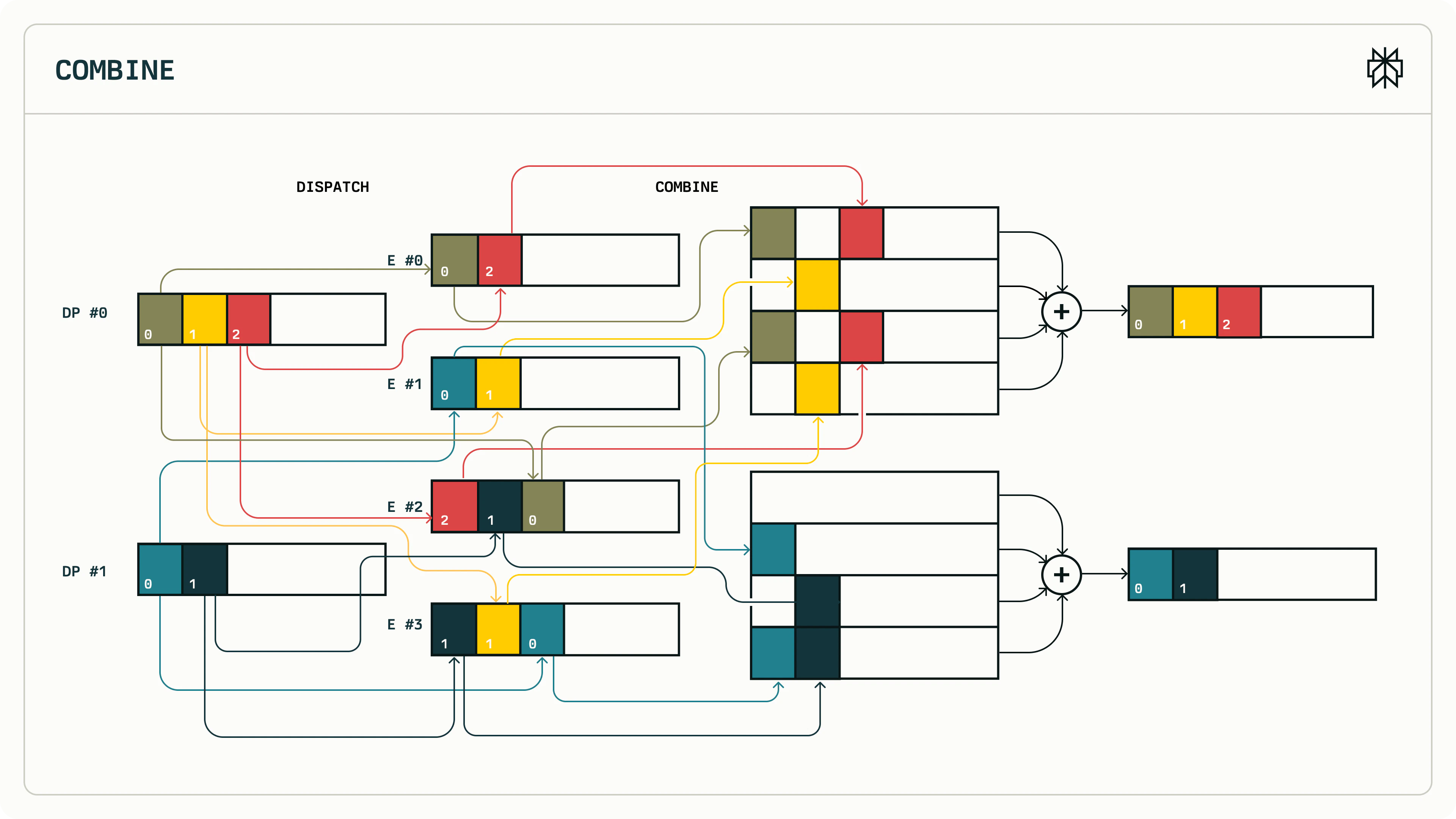
MoE Dispatch/Combine 流程:左侧 token 根据路由分发到各专家,中间专家独立计算,右侧结果发回来源并加权求和(⊕)
- 左侧 DISPATCH:DP #0 有 3 个 token(0, 1, 2),DP #1 有 2 个 token(0, 1)。根据路由结果,token 被分发到 4 个专家(E #0 ~ E #3),一个 token 可能被发给多个专家
- 中间 专家计算:每个专家收到各自的 token 后独立做前向计算
- 右侧 COMBINE:专家计算结果沿箭头发回各自的来源 DP rank,⊕ 表示加权求和——同一个 token 被多个专家处理后,按路由权重合并为最终结果
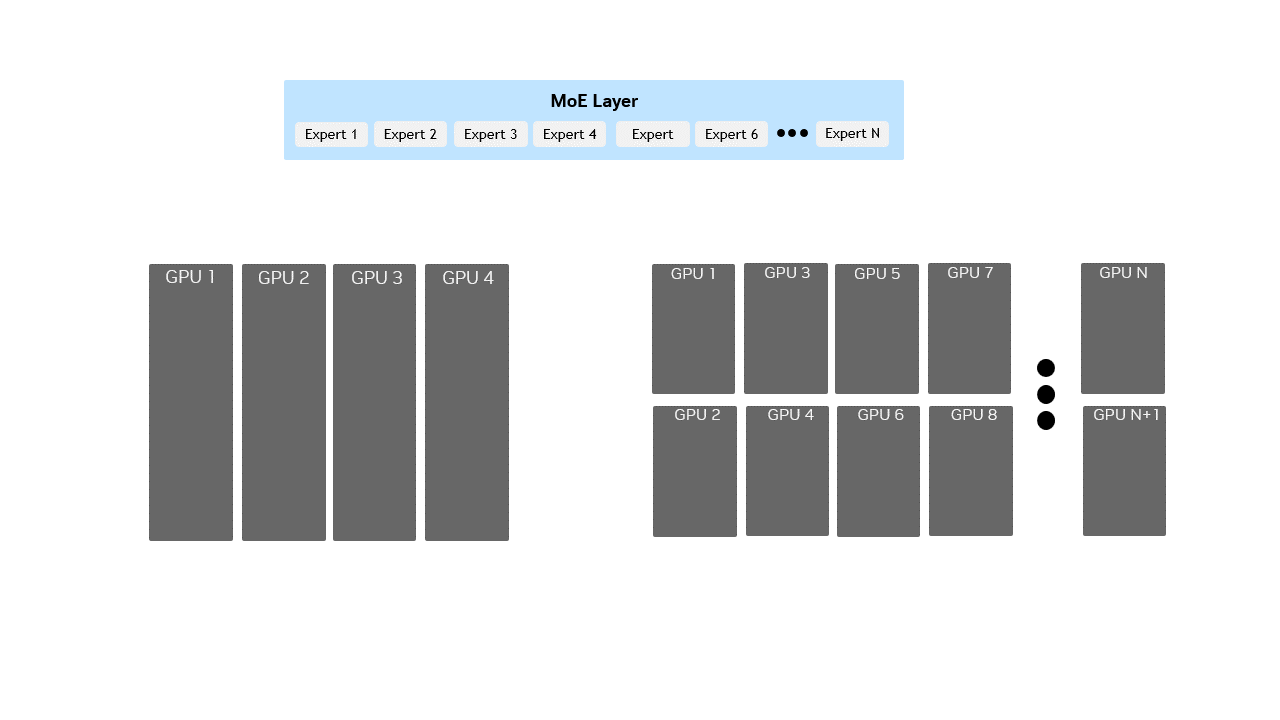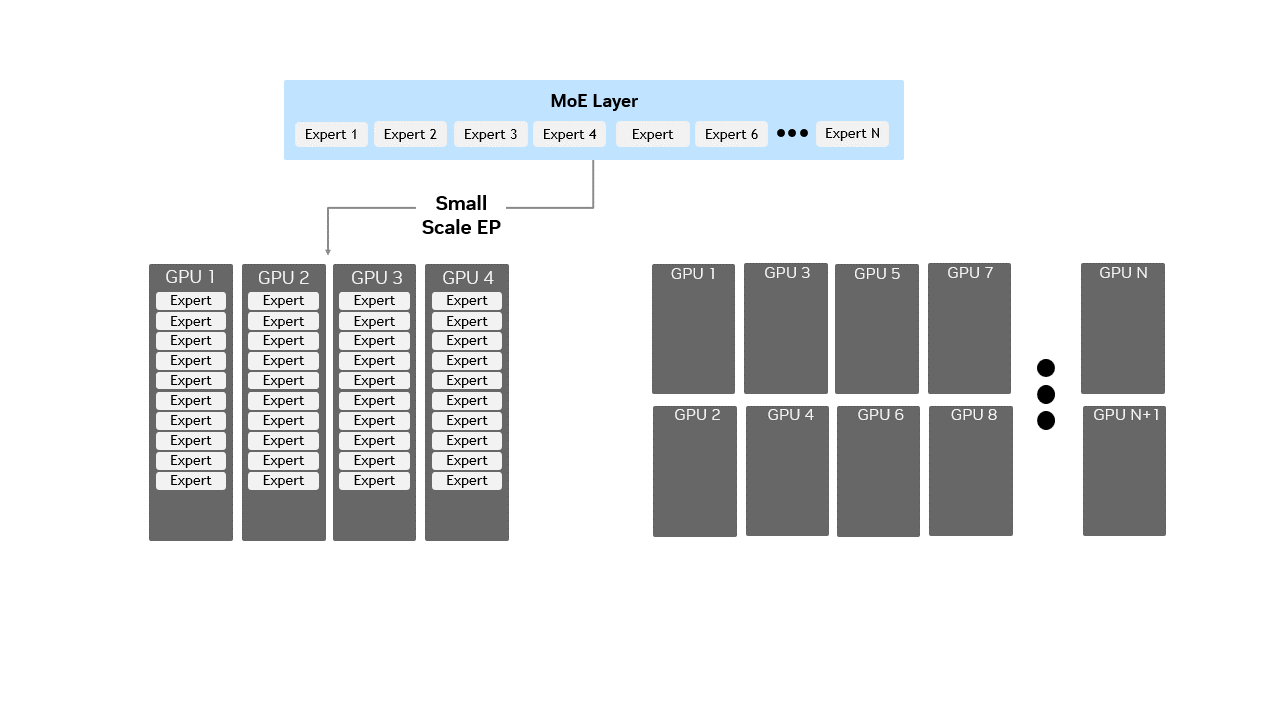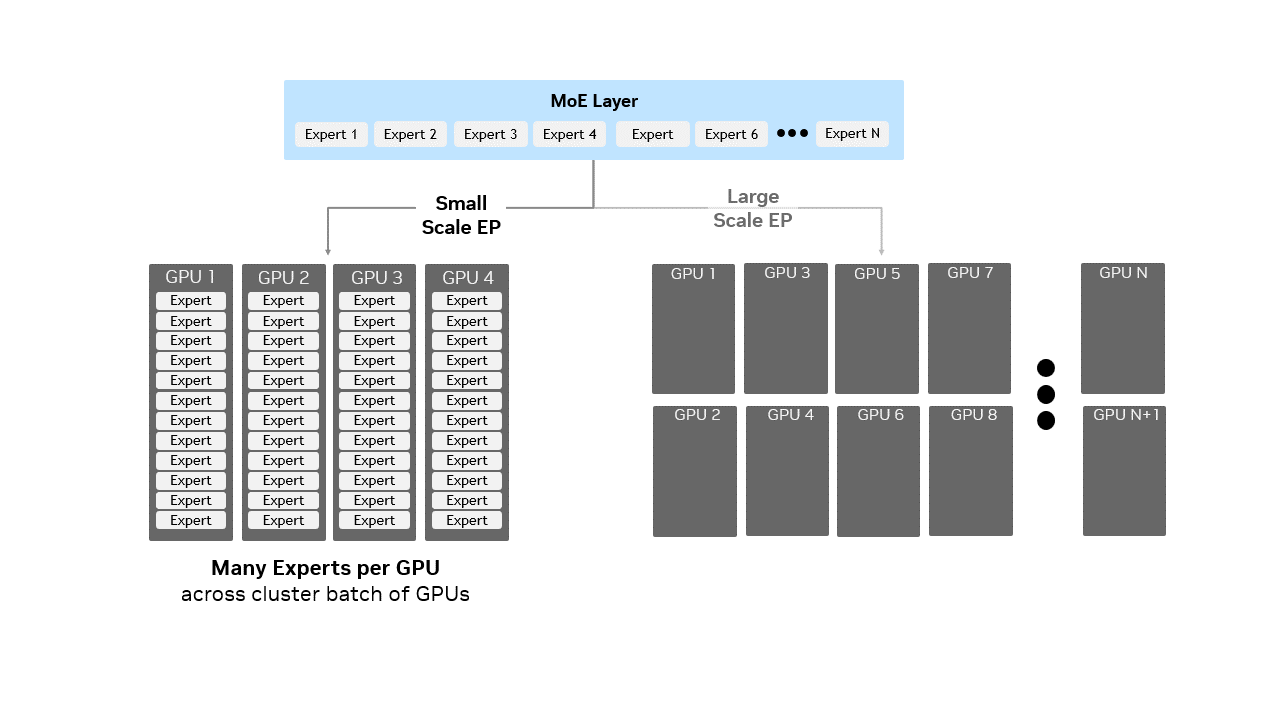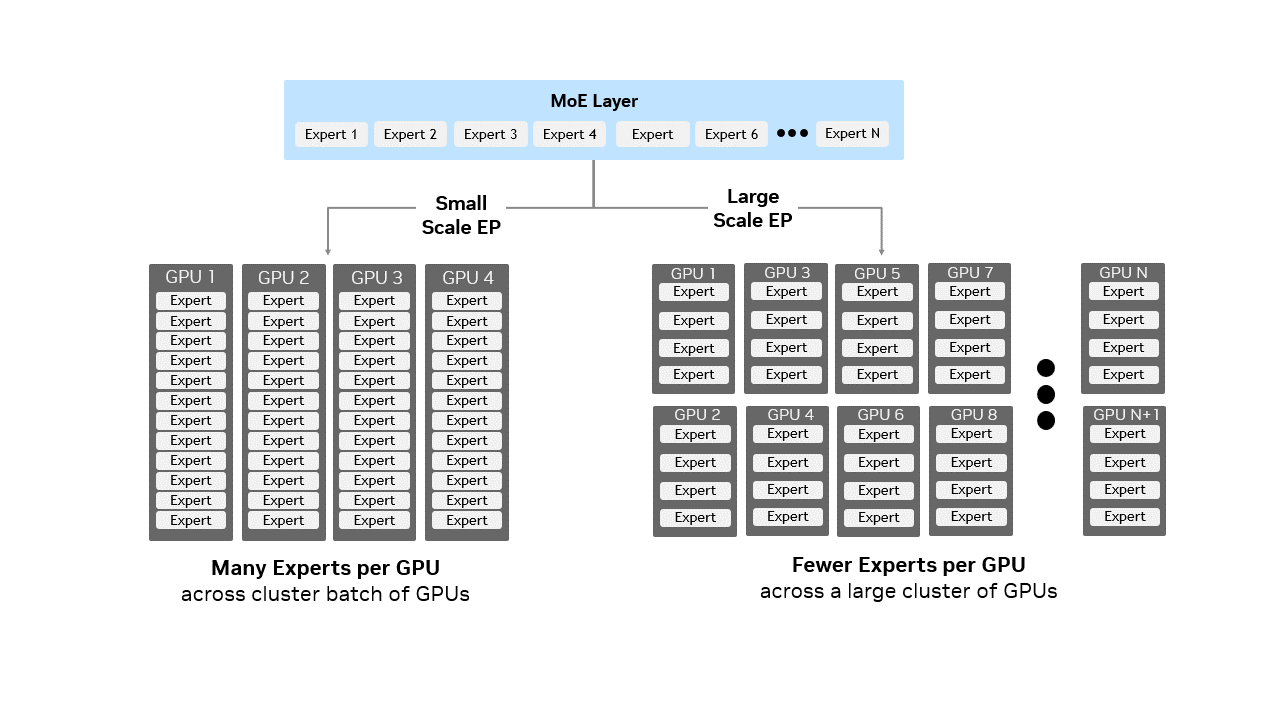
左:小规模 EP,每块 GPU 部署多个专家。右:Wide EP,专家分散到更多 GPU 上,每块 GPU 只持有少量专家
EPLB:4 个 rank 各持有 2 个专家,MoE 层通过 All2All 通信协作。当某个专家成为热门专家时,EPLB 将其 clone 到多个 rank 上分担负载,避免单个 GPU 过载
2.4 开源 MoE 模型一览
- A Visual Guide to Mixture of Experts — 50+ 可视化图解 MoE 的工作原理
- Mixture of Experts Explained — Hugging Face 博客,MoE 的训练技巧和推理优化
- Mixture of Experts (MoEs) in Transformers — Hugging Face 2026 年更新版,MoE 在 transformers 库中的工程实践
- Scaling Large MoE Models with Wide EP on NVL72 — NVIDIA 技术博客,Wide EP + EPLB + GroupGEMM
- vLLM Large Scale Serving: DeepSeek @ 2.2k tok/s/H200 — vLLM 博客,Wide EP + DBO + EPLB 的完整实践
- Dual Batch Overlap 设计文档 — vLLM DBO 的实现细节
- Efficient and Portable MoE Communication — Perplexity 博客,pplx-kernels 的设计与基准测试
- 7 分钟速通开源 MoE — 中文视频,从省算力到负载均衡到推理优化的完整概览
3. 机架式 AI 超级计算机
NVIDIA 正在将 AI 基础设施从单块 GPU、单台服务器演进为机架级系统和 POD 级超级计算机。3.1 GB200 NVL72 (2024)
GB200 NVL72 是基于 Blackwell 架构的机架级 AI 超级计算系统,在单机架内提供 exaFLOP 级算力。它将 36 颗 Grace CPU 和 72 块 Blackwell GPU 整合在一个液冷机柜中,72 GPU 组成一个 NVLink 域,如同一块巨型 GPU。其核心构建单元是 GB200 Grace Blackwell Superchip——通过 NVLink-C2C 将两块 Blackwell Tensor Core GPU 与一颗 Grace CPU 互连。
GB200 NVL72 机柜。左:正面(18 个计算托盘 + 9 个 NVLink switch 托盘)和背面。右:背面特写,NVLink 铜缆脊柱连接所有 72 块 GPU
统一内存
统一内存
- HBM3e(GPU 显存):72 块 GPU × 192 GB = 13.5 TB,直接供 GPU 计算使用
- LPDDR5X(CPU 内存):36 颗 Grace CPU 提供最高 17 TB
cudaMemPrefetchAsync 显式预取数据到本地,避免运行时因数据不在本地而触发缺页异常(page fault),导致 GPU 阻塞等待远端数据搬运。3.2 GB300 NVL72 (2025)
GB300 NVL72(Blackwell Ultra)在同一机柜架构上升级:显存从 192 GB 增至 288 GB HBM3e,FP4 Tensor Core 密度提升 1.5 倍,Attention 性能提升 2 倍。3.3 Vera Rubin NVL72 (2026)
Vera Rubin NVL72 整合了 72 块 Rubin GPU、36 颗 Vera CPU、ConnectX-9 SuperNIC 和 BlueField-4 DPU。通过 NVLink 6 实现机架内 scale-up,通过 Quantum-X800 InfiniBand 或 Spectrum-X Ethernet 实现跨机架 scale-out。 Vera Rubin NVL72 基于第三代 MGX 机架设计,可从上一代 Blackwell 平滑过渡。相比 Blackwell,训练仅需 1/4 的 GPU 数量,推理每百万 token 成本降至 1/10。MGX 机架架构
MGX 机架架构
3.4 Vera Rubin POD (2026)
现代 Agentic AI 系统需要规划任务、调用工具、执行代码、检索数据,并在多个 AI Agent 之间协调连续的多步工作流。这些交互会产生大量推理 token、扩展 KV cache,并需要基于 CPU 的沙箱环境来测试和验证加速计算系统生成的结果,对 GPU、CPU、scale-up 域、scale-out 网络和存储都提出了低延迟、高吞吐的要求。 Vera Rubin POD 通过横跨计算、网络和存储的 7 种芯片极致协同设计,构建了最先进的 POD 级 AI 平台:40 个机柜、1.2 × 10¹⁵ 个晶体管、近 20,000 块 NVIDIA 芯片、1,152 块 Rubin GPU、60 exaFLOPS、10 PB/s 总 scale-up 带宽。
Vera Rubin POD:40 个机柜组成一台 AI 超级计算机,包含 5 种专用机柜(NVL72、LPX、Vera CPU、BlueField-4 STX、Spectrum-6 SPX)

NVIDIA Vera Rubin POD:5 种机架级系统、1 台 AI 超级计算机、1 套 MGX 机架架构和生态系统
Spectrum‑X Ethernet 与 Quantum‑X800 InfiniBand 对比
Spectrum‑X Ethernet 与 Quantum‑X800 InfiniBand 对比
3.5 Vera Rubin Ultra (2027)
Vera Rubin Ultra 引入了一种全新的两层全互连 NVLink 拓扑,使开发者能够将 scale-up 扩展到 576 块 GPU。Vera Rubin Ultra NVL576 将由 8 个独立的 MGX NVL 机柜组成,每个机柜配备 72 块 Rubin Ultra GPU,并通过铜缆和直连光互连构成一个统一的 576-GPU NVLink 域。它将基于同一套 MGX 机架级生态系统构建,以实现最快的产品落地速度。 作为这一大规模多机柜 NVLink 拓扑的演示系统,Polyphe 是 NVIDIA 内部一个基于 GB200 的全功能原型,用于验证多机柜 NVL576 scale-up 架构。
NVIDIA Polyphe 原型:一个基于 GB200 的全功能多机柜 NVL576 scale-up 系统
3.6 Feynman (2028)
为了扩展到 NVL576 之上,NVIDIA 将引入一款新的 MGX 机柜:NVIDIA Kyber。NVIDIA Kyber 是下一代 MGX NVL 机柜设计,可将每个机柜内的 NVLink 域规模翻倍,容纳 144 块 GPU。
NVIDIA Kyber NVL1152
- NVIDIA Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer
- Inside the NVIDIA Vera Rubin Platform: Six New Chips, One AI Supercomputer
- Inside NVIDIA Groq 3 LPX: The Low-Latency Inference Accelerator for the NVIDIA Vera Rubin Platform
- NVIDIA Unveils Rubin CPX: A New Class of GPU Designed for Massive-Context Inference
- NVIDIA Rubin CPX Accelerates Inference Performance and Efficiency for 1M+ Token Context Workloads
- 英伟达将 Rubin CPX 从路线图移除,或以 Groq LPU 及 LPX 机架取代
- Inside NVIDIA Blackwell Ultra: The Chip Powering the AI Factory Era
4. 协同设计(Co-design)
在计算领域,协同设计指的是编写对底层硬件特性有深刻认知的软件。在 AI 背景下,它更具体地意味着让算法、软件与硬件能力协同设计,以最大化性能;FlashAttention、MLA 和低精度量化正是三个典型例子。4.1 FlashAttention
真实系统里的经验反复说明,哪怕只是 GPU kernel 或内存访问模式上的小改动,也可能带来远超直觉的收益。FlashAttention 就是一个经典例子:它没有改变 Transformer 注意力的数学定义,而是以一种更贴近硬件的方式重写 attention 计算。它的核心做法是把 GPU 上的计算切成 tile,尽量减少对显存的读写次数,从而显著降低数据搬运开销并加快 attention 计算。 FlashAttention-1(2022) 首次把 attention 明确地当成一个 I/O 问题来处理。 要理解 FlashAttention 在优化什么,先看 GPU 内部的数据流动方式。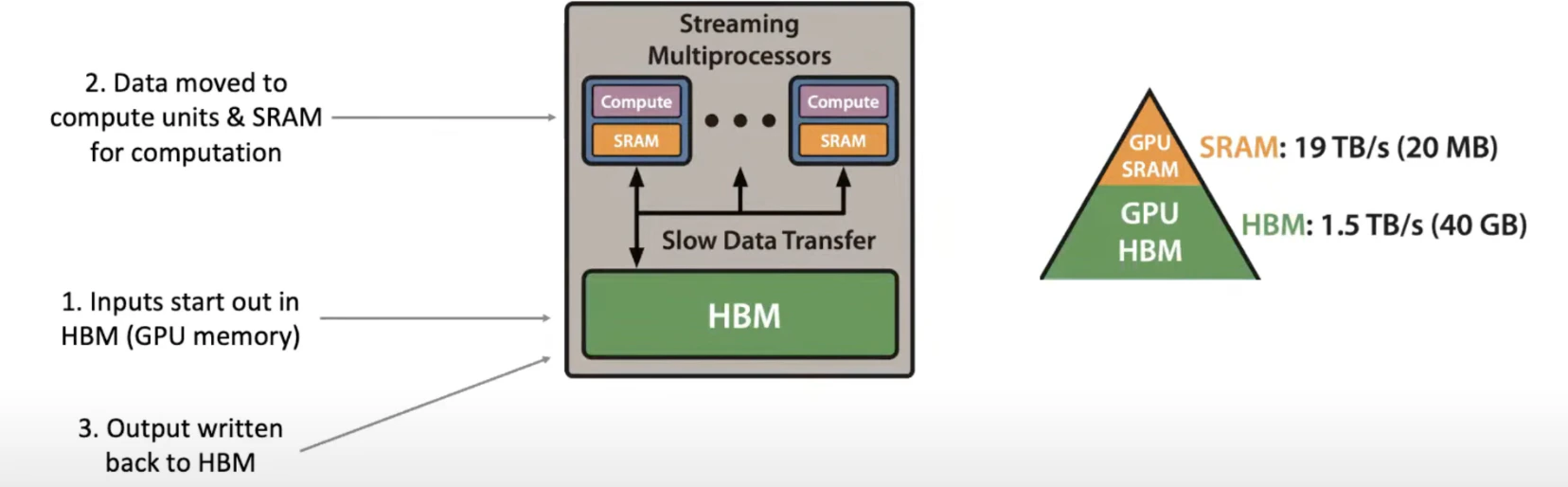
GPU 内存层级与数据流:输入从 HBM 出发,搬入 SM 的 SRAM 进行计算,结果写回 HBM(A100 数据)
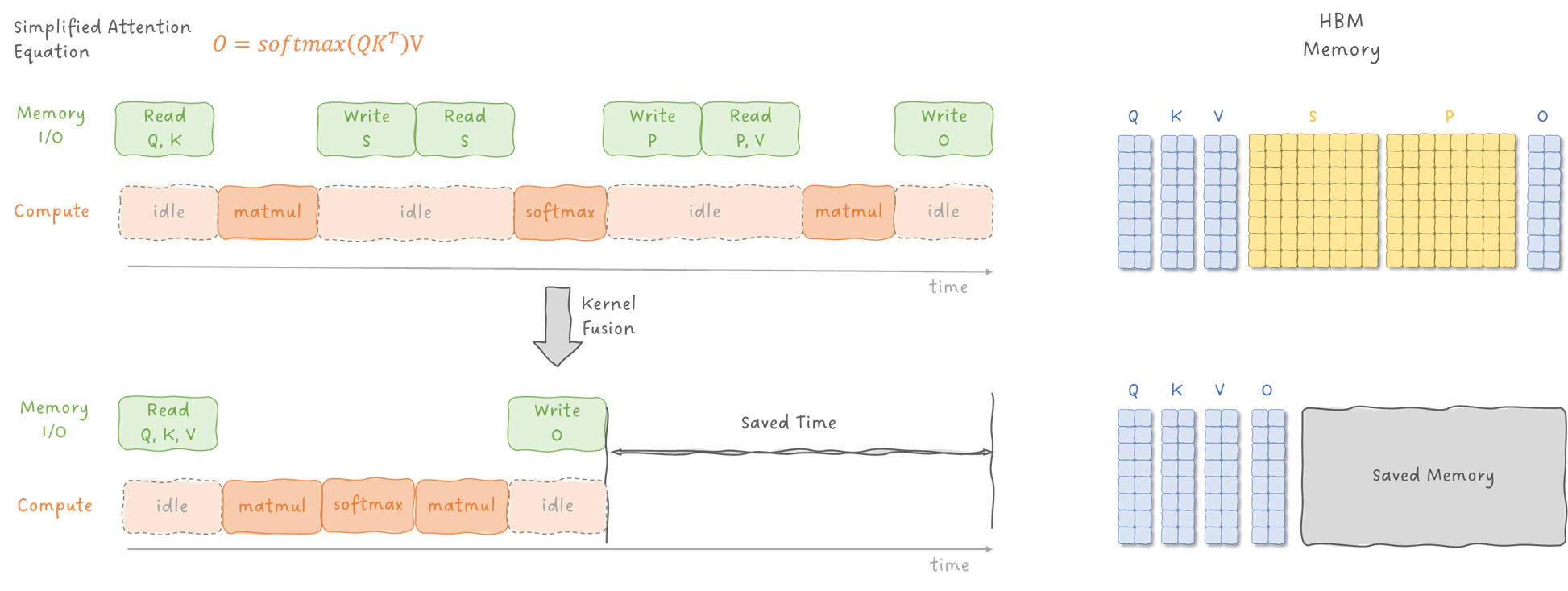
Kernel fusion 前后对比:上方是标准实现,每步 kernel 之间 GPU 都在等 HBM 读写;下方融合后,计算连续执行,省掉了中间的 I/O 等待和 N×N 中间矩阵的 HBM 存储
- 第 1 步:从 HBM 读入 Q 和 K。
- 第 2 步:在 SRAM 中做一次矩阵乘法,计算 。
- 第 3 步:把中间矩阵 写回 HBM。
- 第 4 步:再把 从 HBM 读回。
- 第 5 步:在 SRAM 中计算 。
- 第 6 步:把中间矩阵 写回 HBM。
- 第 7 步:再把 和 V 从 HBM 读回。
- 第 8 步:在 SRAM 中做第二次矩阵乘法,计算 。
- 第 9 步:把输出矩阵 写回 HBM。
N×N 中间矩阵的 I/O 开销
N×N 中间矩阵的 I/O 开销
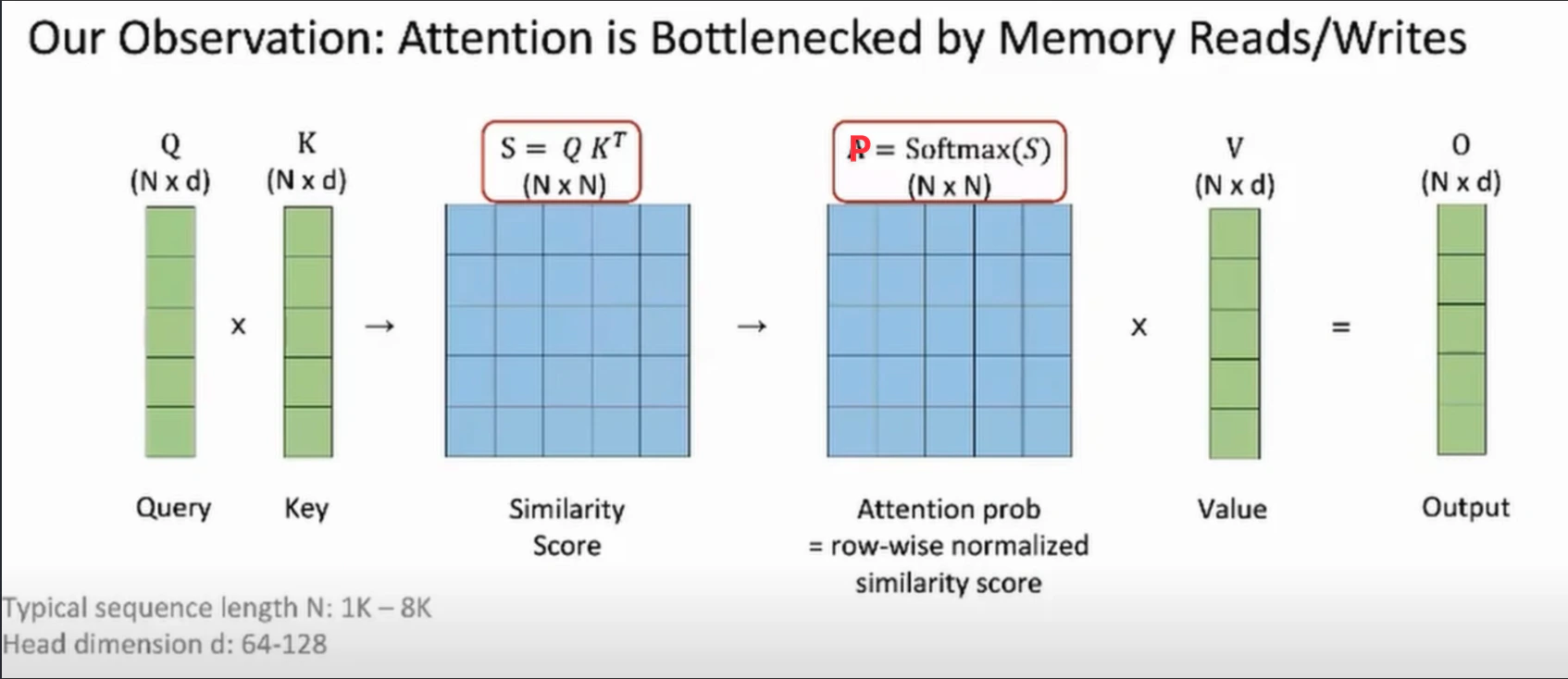
矩阵形状一目了然:Q、K、V、O 都是 N×d,而中间的分数矩阵 S 和概率矩阵 P 都是 N×N。当 N 远大于 d 时,S 和 P 会比输入输出大得多。
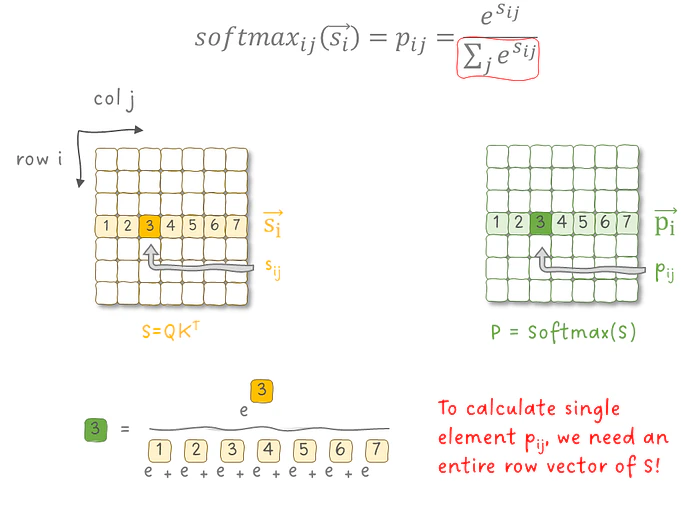
计算 softmax 矩阵 P 的单个元素 p_ij,需要读取 S 矩阵中的整行向量 s_i 来算分母
Softmax 的作用与计算过程
Softmax 的作用与计算过程
Rescaling 具体在做什么?
Rescaling 具体在做什么?
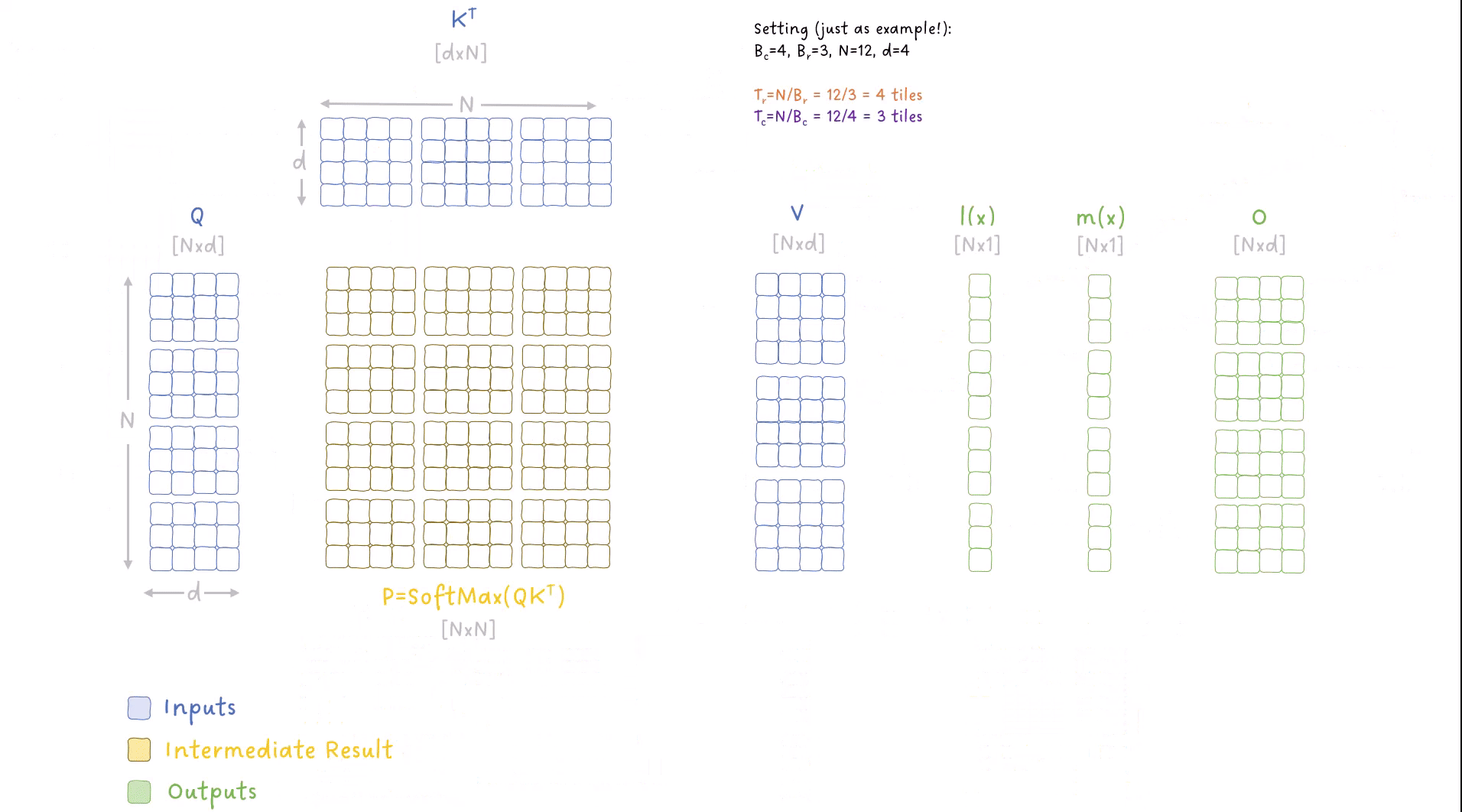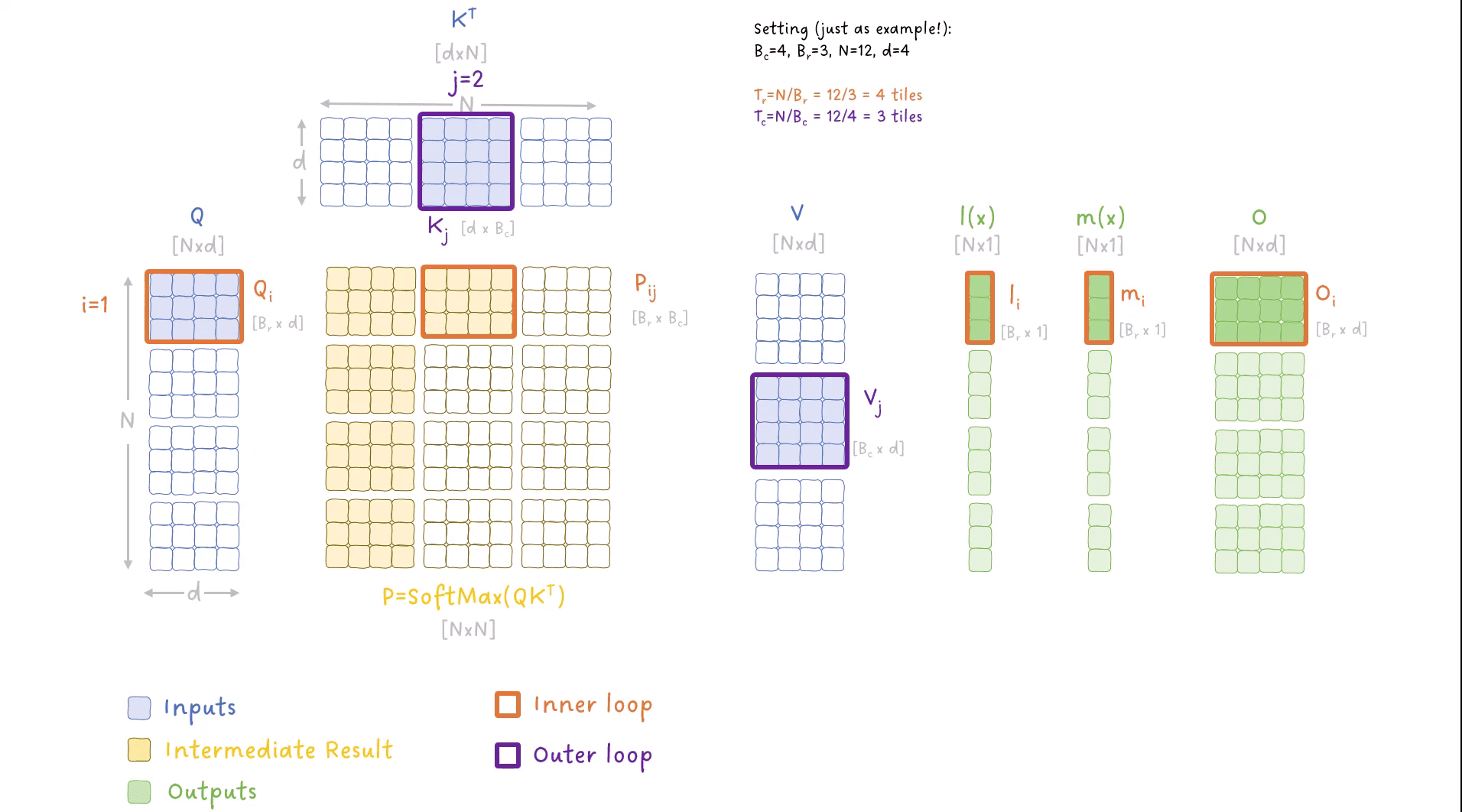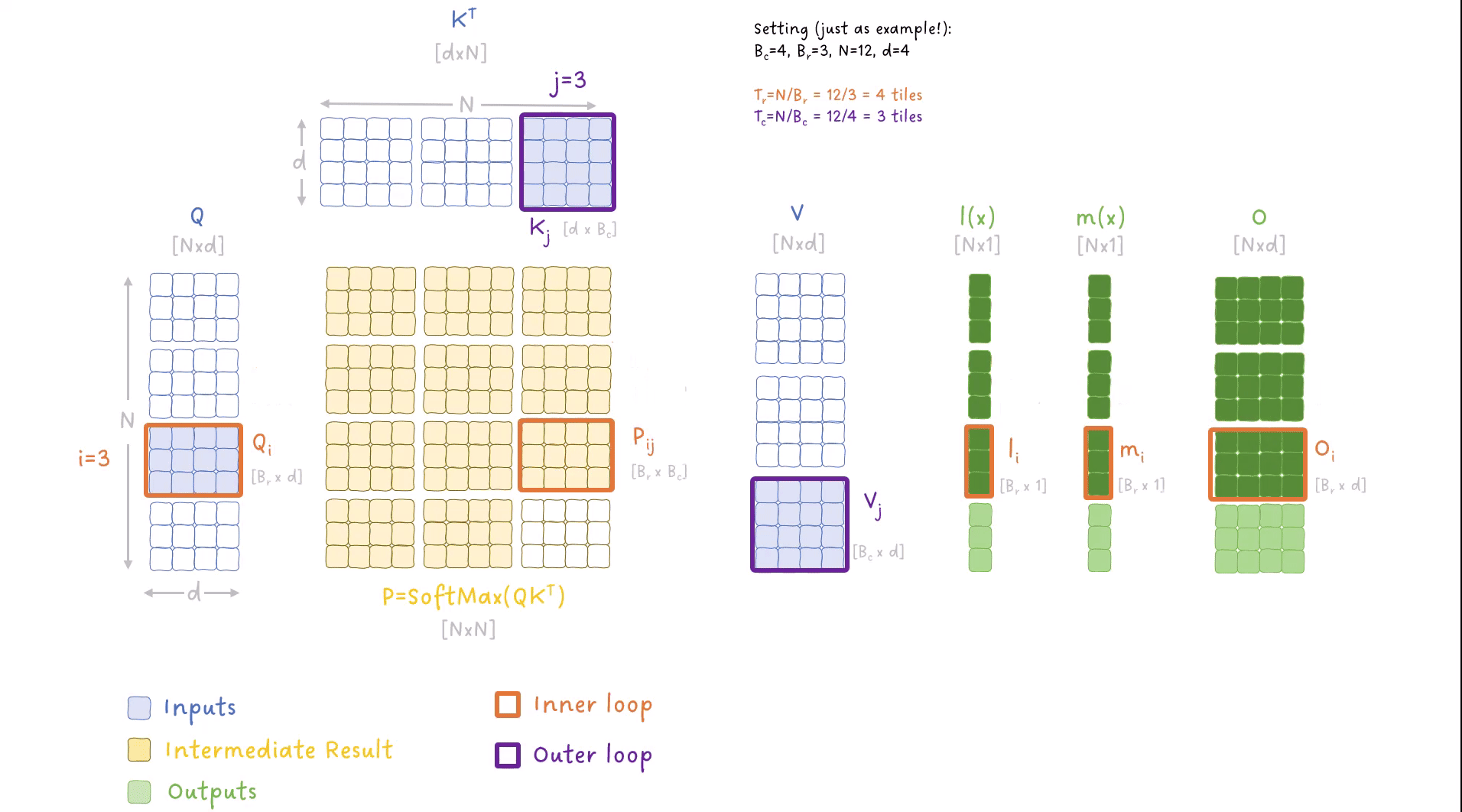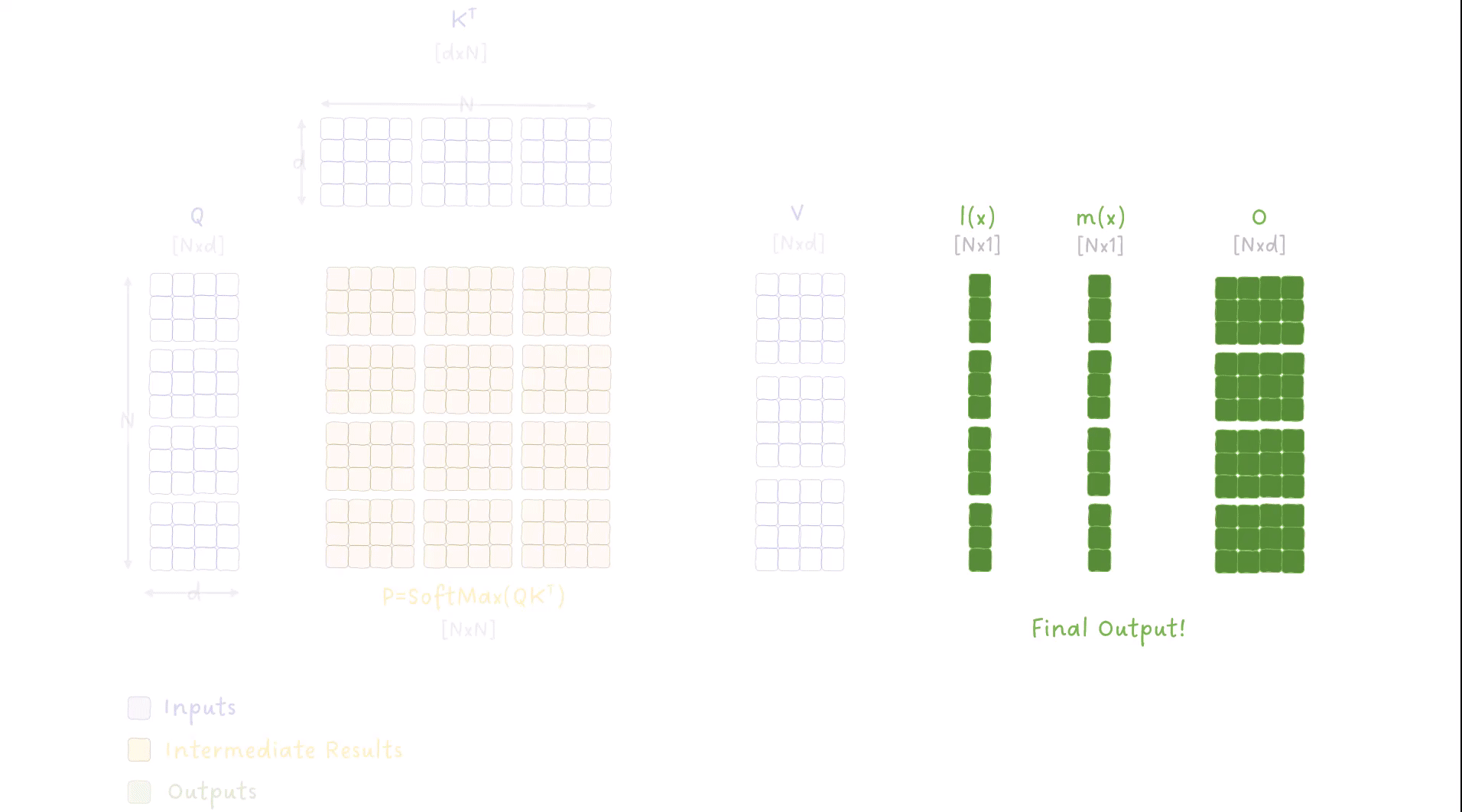
FlashAttention forward pass 的 tiling 动画:外层循环遍历 K、V 的分块(列方向),内层循环遍历 Q 的分块(行方向),每次迭代在 SRAM 内完成局部计算并滚动更新 O、m(x)、l(x)。蓝色 = 输入,黄色 = 中间结果(仅在 SRAM 中),绿色 = 输出
为什么需要两层嵌套循环?
为什么需要两层嵌套循环?
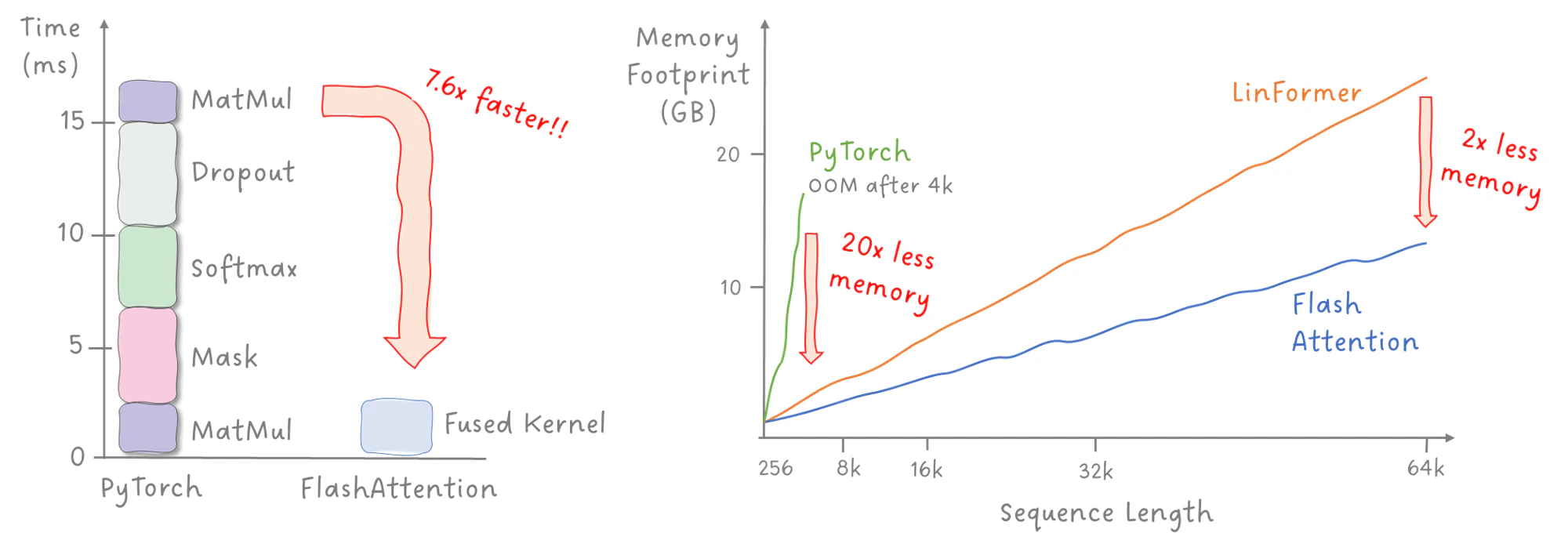
左:FlashAttention 将 5 个 kernel 融合为 1 个 fused kernel,速度提升 7.6 倍。右:显存占用对比,标准 PyTorch 在 4K 序列长度即 OOM,FlashAttention 在 64K 时仍比近似方法 LinFormer 省一半显存
- 同样的模型训练更快
- 同样的模型可以用更大的 batch size
- 同样的预算可以训练更大(通常也更好)的模型
- 可以训练更长上下文窗口的模型
- 可以在更小的 GPU 上训练模型
FlashAttention-1 到 FlashAttention-4 的概览如下:
- FlashAttention from First Principles
- FlashAttention — Visually and Exhaustively Explained
- Flash Attention 2.0 with Tri Dao (author)!
- Flash Attention学习过程【详】解
- ELI5: FlashAttention
- Designing Hardware-Aware Algorithms: FlashAttention
- FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness
4.2 DeepSeek MLA
DeepSeek 的 MLA 算法以 NVIDIA GPU kernel 的形式实现,并于 2025 年开源,是软硬件协同设计的另一个例子。与 FlashAttention 类似,MLA 重新组织了 attention 计算,以更好地利用 NVIDIA 的内存层级和专用的 GPU Tensor Cores。这些优化使 MLA 能够更充分地利用受限的 H800 GPU 架构,以更低的成本实现更高的吞吐量,甚至在同样的 H800 系统上超过了 FlashAttention 的性能。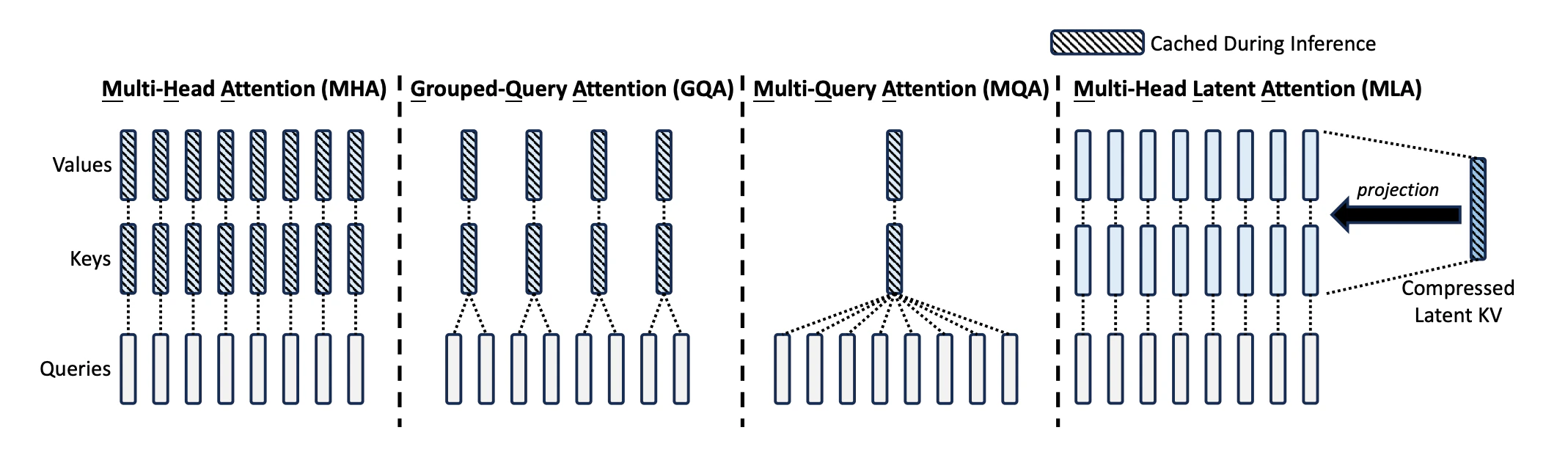
MHA、GQA、MQA 和 MLA 的 KV cache 组织方式对比:MHA 每个 head 独立缓存 K/V,GQA 按组共享 K/V,MQA 所有 heads 共享一组 K/V,MLA 则缓存压缩后的 latent KV,并在使用时投影回各个 head。
W_Q^(i)、W_K^(i)、W_V^(i),每个头各自计算注意力,最后把所有头的输出拼接再投影回去。它的表达能力最完整,但 decode 阶段也必须为每个 head 缓存完整 K/V,因此 KV cache 最大。
MQA (Multi-Query Attention) 保留多个 query heads,但所有 heads 共享同一组 K/V。这样 KV cache 从 h 份降到 1 份,显著减轻显存占用和 HBM 读流量,推理速度通常更高;代价是不同 heads 看到的是同一套 K/V,表达能力往往弱于 MHA。
GQA (Grouped-Query Attention) 是 MHA 和 MQA 之间的折中。它把 h 个 query heads 分成 g 组,每组共享一套 K/V,因此总共有 g 份 K/V。它保留了更多头间差异,因此表达能力通常强于 MQA,但仍弱于每个 head 都独立持有 K/V 的 MHA。
MLA(Multi‑Head Latent Attention) 先把所有头的 K/V 合在一起做一次低维压缩,只把这个共享的 latent 表示写进 KV cache,然后在算注意力时,各个头再用自己的变换从同一个 latent 里解码出各自的 K/V。这样既大幅缩小了 KV cache 的体积,又保留了不同注意力头之间的差异,不像 MQA/GQA 那样只是简单地共用同一套 K/V。
4.3 低精度量化
低精度量化 也是协同设计的典型体现。Transformer 的普及和 FP8、FP4 这类低精度格式的兴起,推动 NVIDIA 增加了 Transformer Engine、面向低精度计算的 Tensor Core、FP4 支持和 microscaling;而这些硬件能力又反过来让研究者可以探索新的数值优化器和神经网络结构,形成持续迭代的正反馈。FAQ
MoE 的核心价值是什么?
MoE 的核心价值是什么?
FlashAttention 优化的到底是什么?
FlashAttention 优化的到底是什么?