录屏回看
本章概要
本章内容沿 “单芯片→芯片间→机架内→机架外→数据中心” 的物理尺度逐层推进。
NVIDIA DGX GB200 NVL72
- 单 GPU 芯片内,采用 NV-HBI 以 10 TB/s 带宽将双裸片拼接,突破制造工艺、成本限制;
- 主要 Grace CPU 与 Blackwell GPU 经 NVLink-C2C 融合为 Superchip,统一内存架构消解了 CPU-GPU 间的数据拷贝壁垒;
- 机架内,72 颗 GPU 借 NVLink/NVSwitch 构建起 NVL72 全互联高速域,采用 SHARP 将梯度聚合卸载到交换芯片执行;
- 机架外,把多柜拼为 SuperPod,使用 InfiniBand 再扩展为万卡级 AI 数据中心。
From Die to AI Factory
章节详解
1. Superchip
1.1 芯片内:NV-HBI
NVIDIA Blackwell-architecture GPUs pack 208 billion transistors and are manufactured using a custom-built TSMC 4NP process. All NVIDIA Blackwell products feature two reticle-limited dies connected by a 10 terabytes per second (TB/s) chip-to-chip interconnect in a unified single GPU. — NVIDIA Blackwell ArchitectureNVIDIA 在 Blackwell 架构中首次公开使用 “two reticle-limited dies” 描述 B200 GPU。但过去几十年的经验是”更大 die = 更强 GPU”,那为什么芯片不能继续做大,反而要学 Apple/AMD 玩”胶水”? 结论:不是不想继续做超大单芯片(monolithic GPU),而是光刻、良率、成本、功耗、互连已经快把它逼到物理极限了。

NVIDIA B200
极限 1:光刻的极限 当前 ASML EUV 的单次曝光场约为: 考虑 seal ring、overlay margin 与 test structure 后,实际可用面积通常低于 850 mm²。GH100(814 mm²)与 GB202(750 mm²)已经逼近这一物理边界。更值得注意的是,High-NA EUV 的有效曝光面积未来可能进一步缩小至约 429 mm²,使超大 monolithic GPU 更不可持续。 极限 2:Yield 良率问题 依据经典缺陷模型,die 面积增加会导致良率指数级下降: 其中 为 yield, 为 die area, 为 defect density。
Silicon Bridge 随着 Tensor Core、片上 SRAM、HBM PHY 与 NVLink PHY 持续扩张,单 Die GPU 已接近光罩面积与制造良率极限,多 Die/MCM(Multi-Chip Module)成为继续扩展 AI 算力的必然路径。因此,B200 采用 dual-reticle + NV-HBI + CoWoS-L,通过 advanced packaging 横向扩展逻辑面积,从而进一步提升算力。
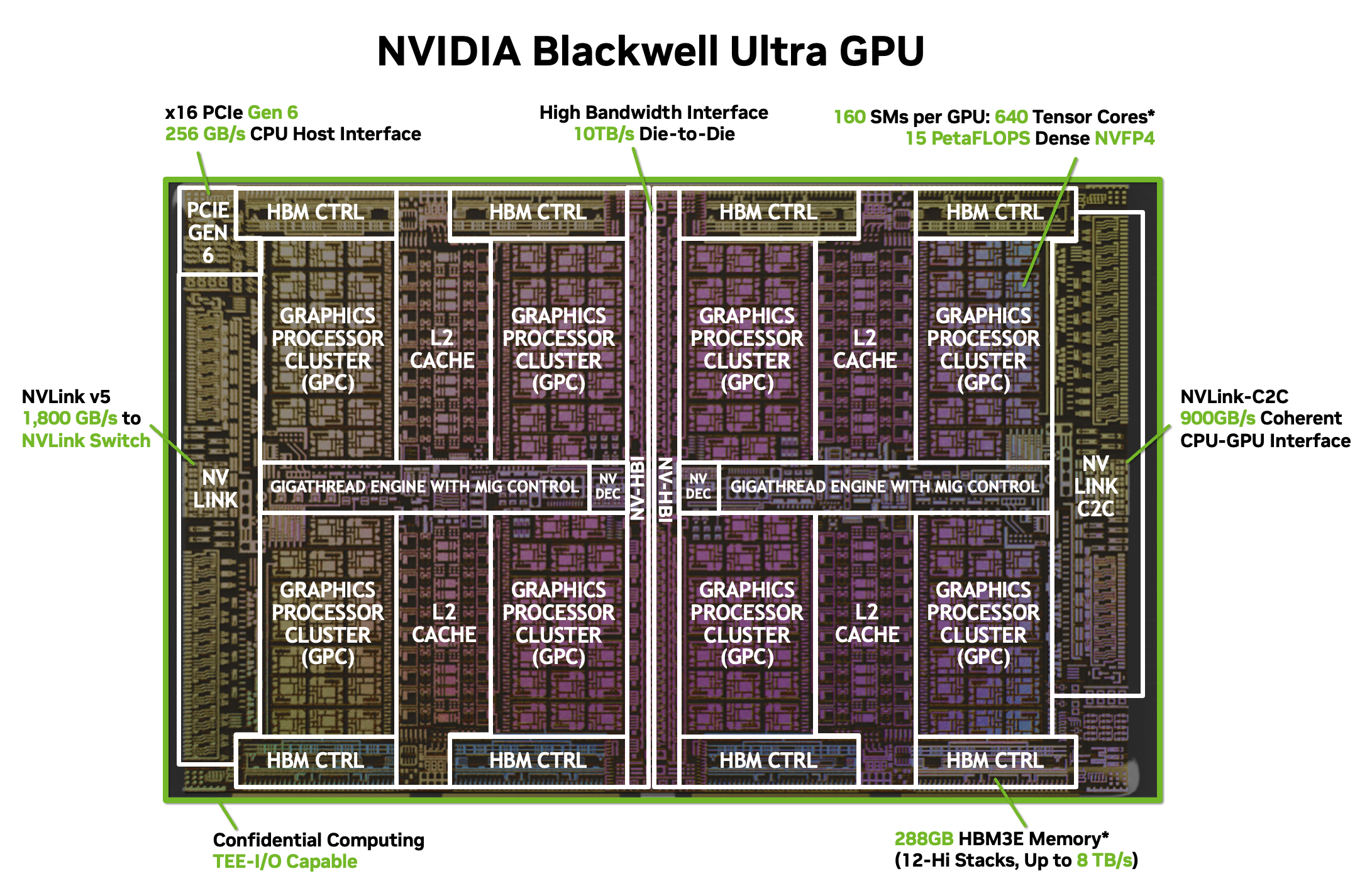
NVIDIA Blackwell Ultra GPU Blackwell Ultra GPU 最多包含 160 个 SM 单元和 288GB HBM3E 显存。SM 单元数量和 HBM 显存容量因 SKU 而异。
与 Apple M1 Ultra 的对比 Mac Studio 中 Apple M1 Ultra 通过 UltraFusion 封装架构将两颗 M1 Max Die 互联,die-to-die 聚合带宽达到 2.4 TB/s,同样属于高带宽 MCM 架构。
值得注意的是,NVIDIA 早在 2017 年 ISCA 上就曾发表过关于 MCM-GPU 的探索性研究。结果显示,优化后的 MCM-GPU 相比单 die 方案最高可提升约 45.5% 性能,相比多 GPU SLI 方案也有约 26.8% 的优势。 但论文同时指出了一个关键瓶颈:数据局部性问题——必须尽可能将高频访问的数据保持在同一 die 的本地缓存中,否则跨 die 访问带来的带宽与延迟开销会迅速抵消并行带来的收益。
APPLE M1 Ultra
Blackwell 在本质上更接近一种 NUMA-aware 的统一 GPU 架构,而不是严格意义上的“完全对称单芯片设计”。
这种架构在 HPC(高性能计算)场景中是可以通过精细调度来发挥优势的:例如矩阵乘法这类计算任务,天然适合被均匀拆分到不同 die 上执行,从而获得良好的并行效率。然而在通用游戏渲染场景中,不仅需要频繁访问几何数据和纹理资源,而且这些资源通常分布在不同 die 上,使得跨 die 的数据依赖无处不在。因此,这种架构在游戏负载下的调度复杂度和通信开销会显著上升。
先进封装:CoWoS-L
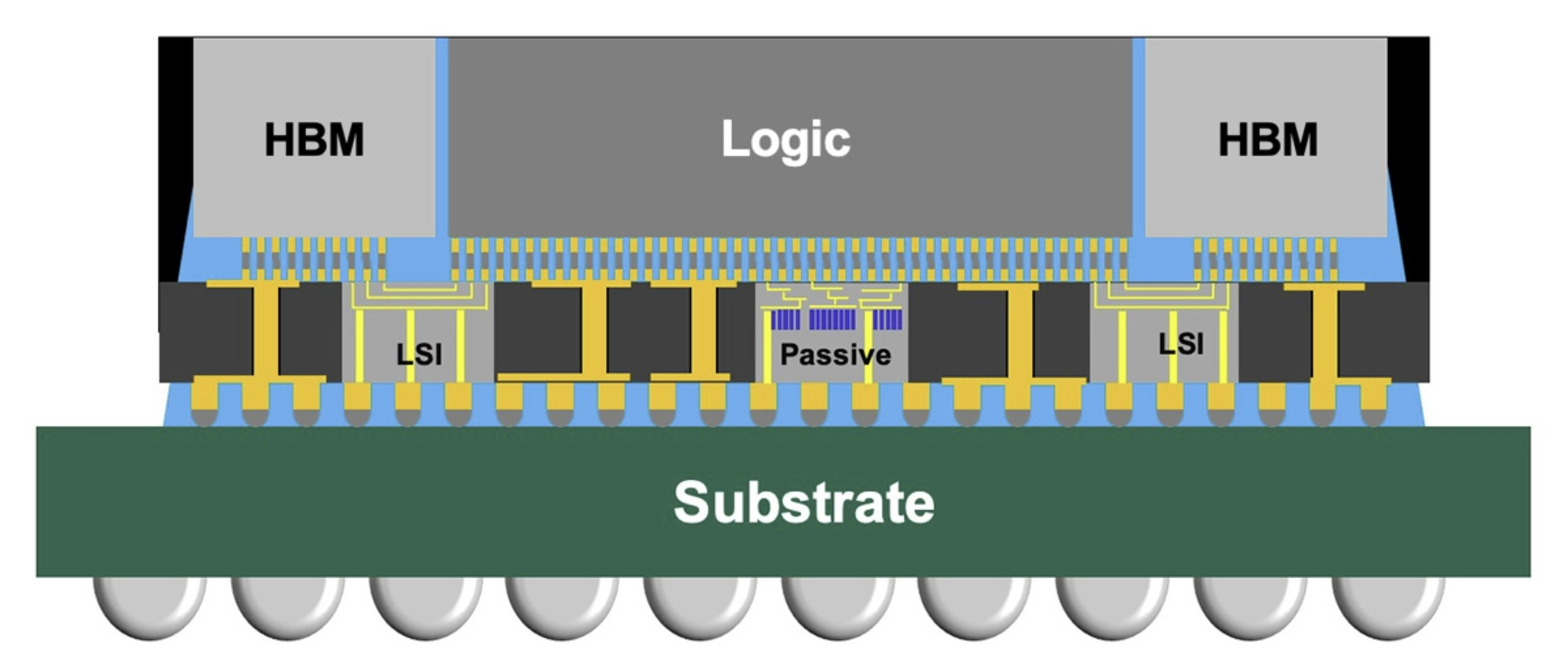
CoWoS-L
1.2 芯片间:NVLink-C2C
如果说 NV-HBI 解决的是 GPU 内部多 Die 间的高带宽互联问题,那么 NVLink-C2C(Chip-to-Chip)解决的则是 CPU–GPU 之间长期存在的互联与内存一致性瓶颈,其核心目标是突破 PCIe 所带来的带宽、延迟与软件模型限制,演进到真正的统一内存架构(Unified Memory Architecture)。 NVLink-C2C 通过超高速、一致性的 die-to-die 互联,将多个逻辑处理芯片封装为一个统一计算节点(Unified Compute Node)。典型产品包括:- Grace CPU Superchip:由两颗 Grace CPU 通过 NVLink-C2C 互联组成;
- Grace Hopper Superchip(GH200):由 1 颗 Grace CPU 与 1 颗 Hopper GPU 组成;
- Grace Blackwell Superchip(GB200/GB300):由 1 颗 Grace CPU 与 2 颗 Blackwell GPU 组成。
NVLink-C2C 提供 CPU 与 GPU 之间的硬件级 cache coherency(一致性内存语义),使 CPU 可通过 load/store 直接访问 GPU HBM,GPU kernel 亦可直接访问 CPU LPDDR5X 内存,从而避免传统 PCIe + DMA 的显式 memcpy 数据搬运路径。
基于该一致性内存模型,可进一步支持细粒度的内存层级管理策略。
-
- 在大模型训练中,将 Adam optimizer 的一阶/二阶状态(m/v states)offload 至 CPU 内存以降低 GPU HBM 占用;
-
- 在推理场景中,可将低频访问数据(如 MoE 未激活 expert 参数或冷 KV cache)放置于 CPU 内存,通过按需访问与缓存机制实现容量扩展,但会引入额外延迟与带宽开销。
1.3 Grace CPU:为什么是 ARM/LPDDR5X?
Grace CPU Superchip 将两颗 Grace CPU C1 die 封装在一个 CoWoS 基板上,通过 NVLink-C2C 互联,构成 144 颗 ARM Neoverse V2 核心的逻辑 CPU。
Grace CPU C1
- 每瓦性能:Grace CPU C1 单颗芯片 CPU+内存功耗仅 250W(Superchip 整模块 500W),而与之对标的双路 x86 服务器功耗接近 900W,差距 1.8×;
- SVE2 向量指令集:Neoverse V2 支持 4×128b SVE2,每条指令可处理 512 位数据,对 CPU 侧 Transformer 算子(softmax、layer norm)有显著本地加速;
- IPC 与 x86 持平:ARM Neoverse V2 每核性能约追平 Ice Lake,但 TDP 约为 x86 同等配置的 50%。
- 带宽优先:DDR5 DIMM 受限于每通道 64 位标准,要实现同等带宽需要极多通道,占用大量 PCB 面积;
- 功耗敏感:LPDDR5X 的 I/O 电压仅 0.5V,功耗约为 DDR5 同带宽下的 12.5%;
- 无 DIMM 插槽:内存直接焊接在基板上,节省插槽带来的功耗和面积开销,但牺牲了可扩展性和维修便利性。

Grace CPU Superchip
1.4 Tensor Core
NVIDIA Tensor Core 的演进始终在解决两个核心问题:- 如何让矩阵乘法更快
- 如何让数据搬运更少

NVIDIA Blackwell Streaming Multiprocessors Architecture
- 128 个 CUDA 核心,用于 FP32 和 INT32 操作,以及 FP16/BF16 和其他精度。
- 4 个第五代 Tensor Core,配备 NVIDIA 第二代 Transformer Engine,针对 FP8、FP6 和 NVFP4 进行了优化。
- 256 KB 张量内存 (TMEM)用于线程束同步存储中间结果,从而实现更高的重用率和减少片外内存流量。
- 用于人工智能内核的超越数学和特殊运算的特殊功能单元 (SFU) 。
1.5 SM、Warp 与线程层次
- warp scheduler
- register file slice
- execution pipeline
- 多个 warp → 一个 CTA/thread block
- 多个 CTA → 一个 grid
2. Memory
2.1 HBM 技术演进与物理实现
传统 GDDR5/6 架构已难以继续通过提升频率与扩展 PCB 位宽获得线性带宽增长,主要受限于信号完整性、功耗以及布线复杂度。2015 年,AMD Radeon R9 Fury X 推动 HBM1 首次在商用 GPU 中落地,将 HBM DRAM 与 GPU die 通过 silicon interposer 进行 2.5D 集成。随后 NVIDIA Tesla P100(2016)引入 HBM2,并在 TSMC CoWoS 封装工艺上实现 GPU 与 HBM stack 的高带宽互连。 HBM 的关键制造技术是 TSV(Through-Silicon Via),在 DRAM die 内部形成垂直导电通道,使多层 DRAM die 能够垂直堆叠并实现高密度互连。深宽比从早期约 1:5–1:10 提升至 HBM3/3E 时代约 1:10–1:20。
SK Hynix HBM
HBM 三重性能瓶颈
- CA Bus 仲裁争用:每个 HBM channel 的 CA(Command/Address)总线是共享资源,多流并发访问时仲裁冲突会降低有效带宽。
- Row Buffer Locality:DRAM 访问遵循 open-page 策略,对于 MoE expert routing 等随机稀疏访问模式,row miss 率高。
- 温度敏感性:HBM3e 在 junction temperature 上升一定数值,PHY 会自动降低数据速率(通常触发 2× 降速)。NVIDIA IMC(Intelligent Memory Controller)实现了温度感知的带宽调度。
近存计算(Processing-In-Memory)
HBM-PIM(如 Samsung Aquabolt、SK Hynix AiMX)在 Base Die 集成了向量 MAC 单元,可在 DRAM 内部执行简单的矩阵-向量乘。HBM4 时代将在 base die 上集成更丰富的定制 IP 逻辑,允许用户在内存中直接执行部分计算。当前主要障碍在于编程模型(需要专用 intrinsic)尚未融入主流框架。
2.2 HBF
随着 AI 模型参数量走向数十万亿级别,现有的 HBM 容量已经快装不下完整的模型权重了,频繁从外部搬运数据会导致严重的“存储墙”瓶颈。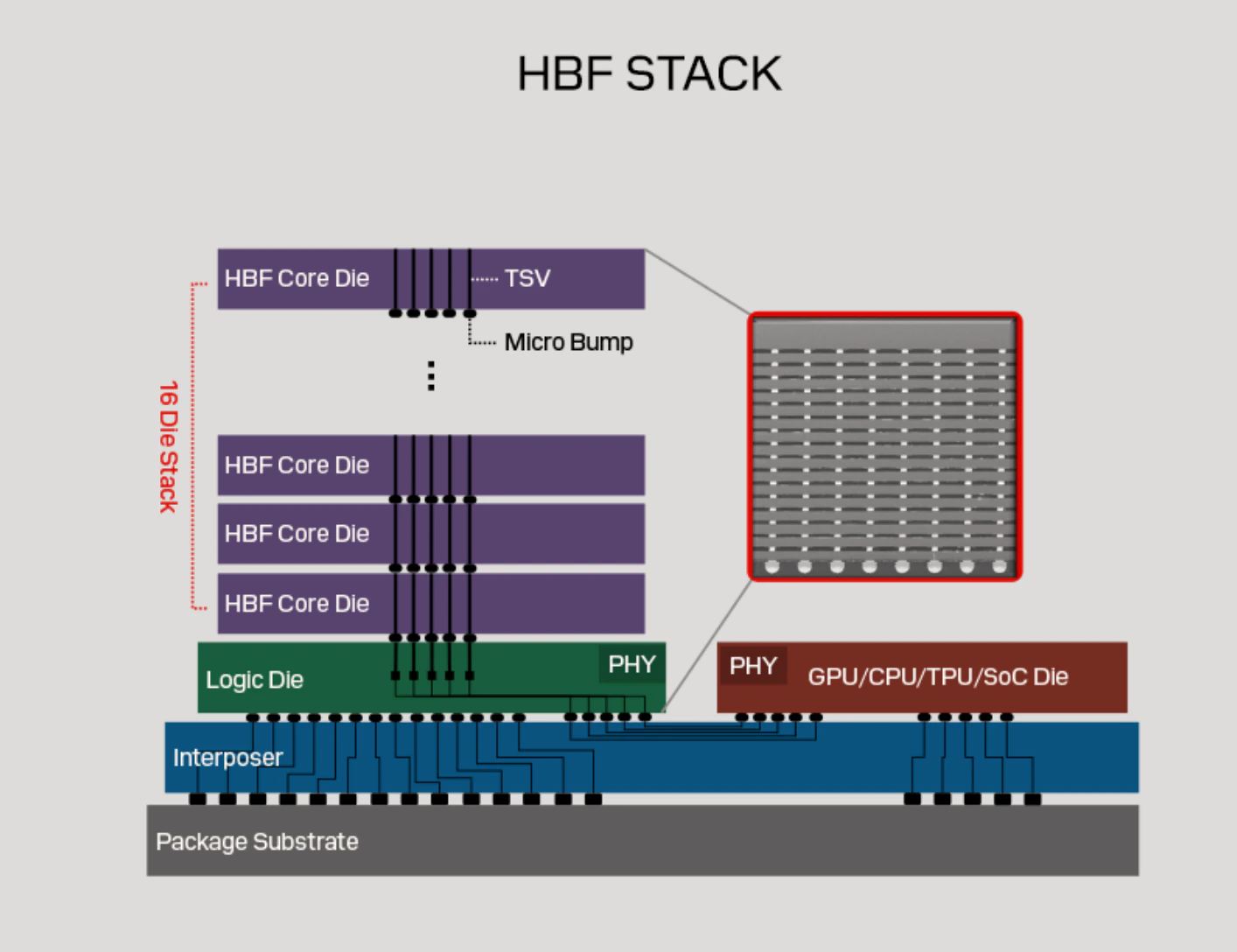
HBF

HBM vs HBF
2.3 SRAM(NVIDIA Groq 3 LPX)
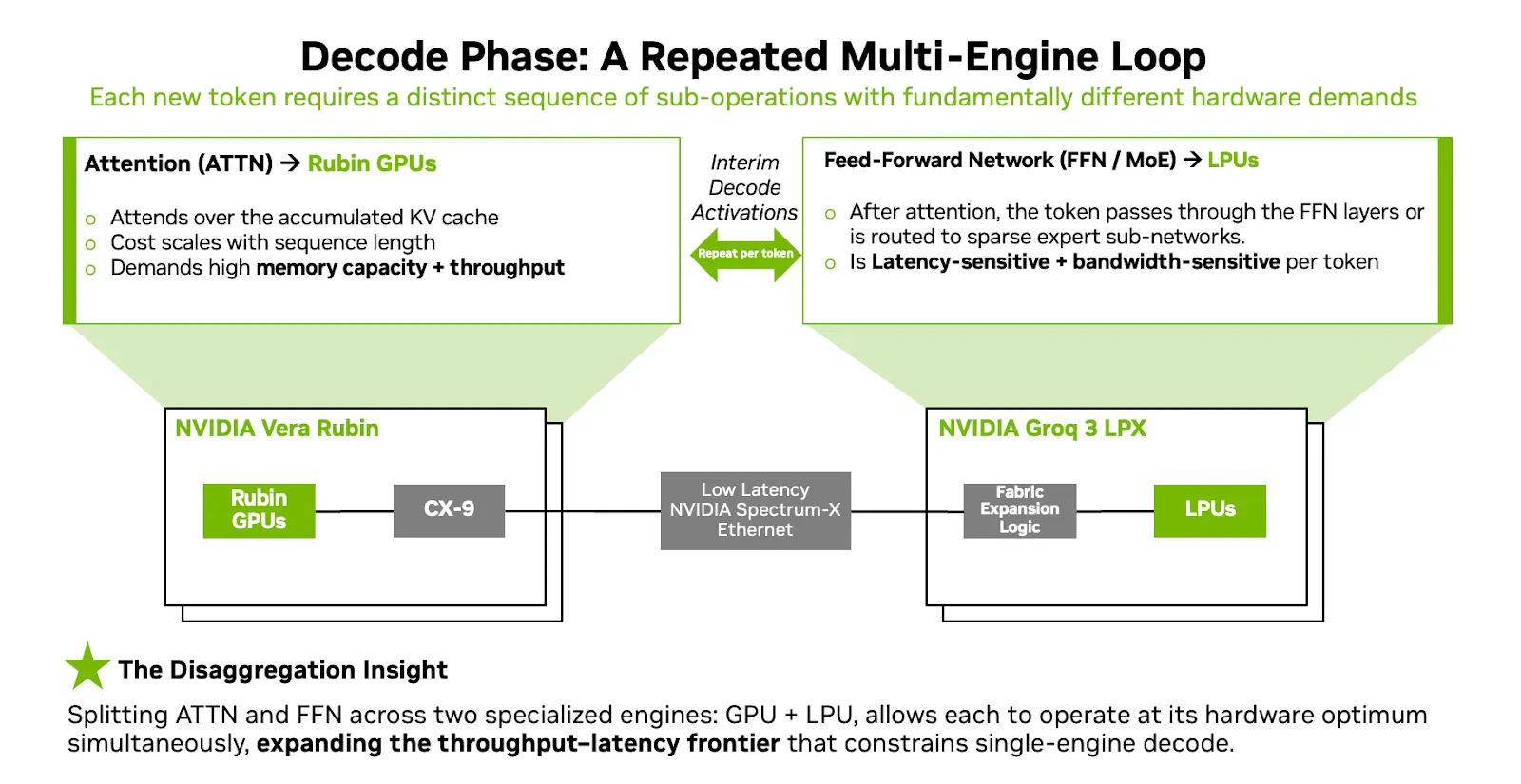
LPX Decode Phase
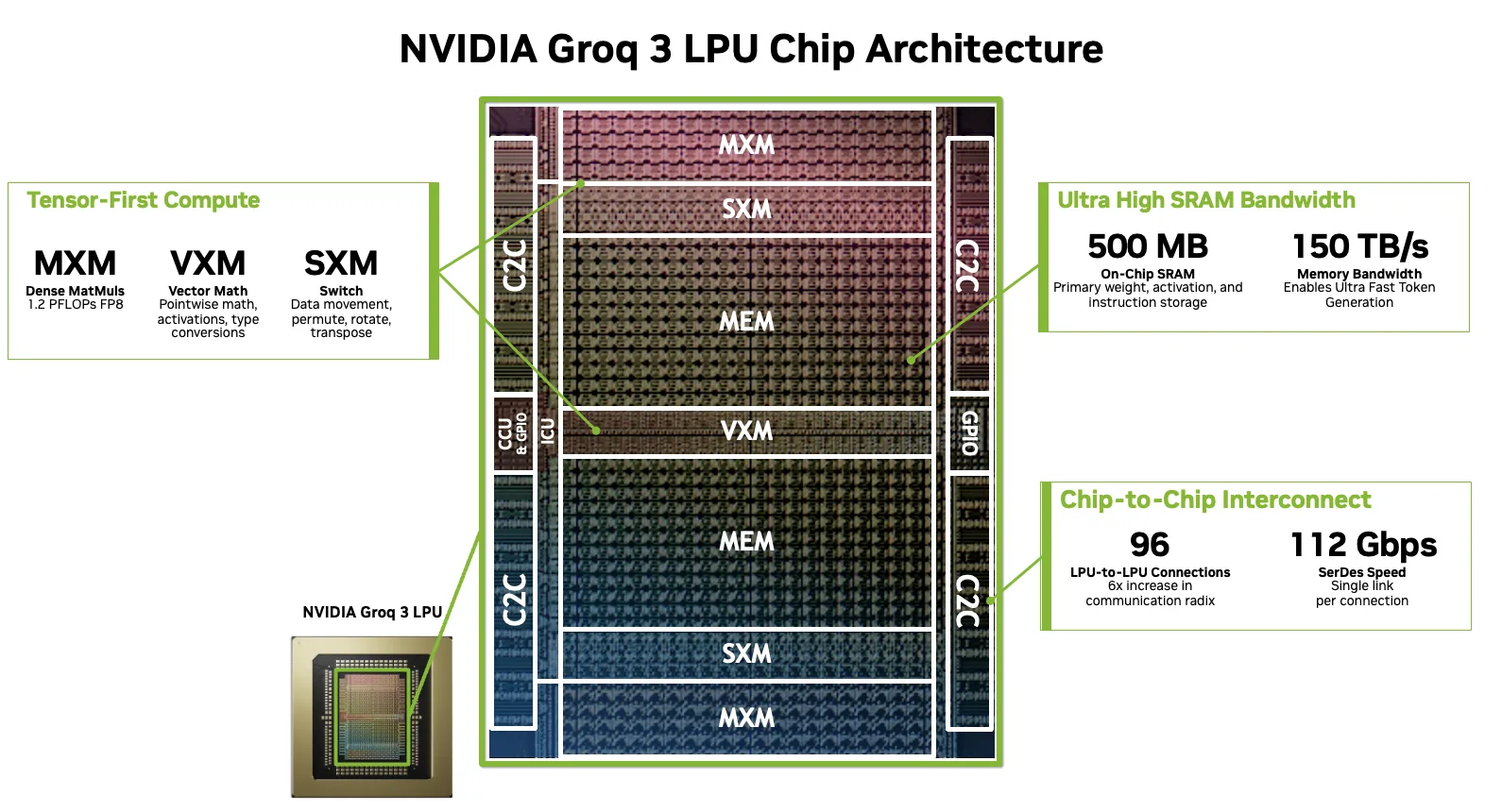
NVIDIA Groq 3 LPU Chip Architecture
- 确定性(Deterministic):通过编译期静态调度替代运行时动态调度,使每个 token 的执行路径固定,从而消除延迟抖动。
- 近存计算(SRAM-based compute):将关键计算与数据直接放在片上 SRAM 中执行,避免 HBM/缓存层级访问带来的高延迟与不确定性。
- 任务拆分(GPU + LPU disaggregation):把推理流程拆成不同硬件专责执行(GPU负责attention,LPU负责FFN/解码),减少单芯片资源竞争并提升整体流水线效率。

NVIDIA Groq 3 LPX

NVIDIA Groq 3 LPX
3. Networking
3.1 NVL72 物理架构与机架内全互联
GPU-as-memory:任何 GPU 都可以直接访问其他 GPU 的 HBM,就好像访问本地内存一样,NVLink 5.0 每 GPU 双向带宽 1.8 TB/s。
无 Retimer 设计:机架内物理距离 < 3m,采用无源铜缆 + 无 Retimer 方案。Retimer 引入 ~5–10 ns 额外延迟,对于 ~1 μs 级 All-Reduce 不可忽略;无 Retimer 同时降低每端口约 2W 功耗。PAM4 信号对走线长度匹配极为敏感:1 mm 的长度差异在 112 Gbps PAM4 下引入约 10 ps 的 UI 偏移,超过 PAM4 接收机的 timing margin,NVL72 背板需要精确蛇形走线等长。
3.2 SHARP 网内计算
All-Reduce 通信模式演进 传统 Ring All-Reduce(Baidu/Horovod,2017):N 个节点排成逻辑环,2 轮通信(Scatter-Reduce + All-Gather),每节点通信量 ,带宽效率接近 1,但延迟正比于 N。 SHARP v3(Scalable Hierarchical Aggregation and Reduction Protocol)将 reduction 操作卸载到 NVSwitch 的 ALU 中执行:- 数据从各 GPU 发送至 NVSwitch,在交换芯片内聚合后一次性广播,单次 pass 完成 All-Reduce;
- 带宽效率接近理论极限 1×(每条链路只流通数据一次);
- 大 tensor(>1 MB)场景下 All-Reduce 加速 30–50%。
- 最多同时支持 256 个 reduce group;
- 仅支持 FP8/FP16/FP32 的 element-wise 加减,不支持 max/min 等复杂 reduce;
- 小 tensor 因 header overhead 收益递减。
NCCL_ALGO=NVLS_TREE 环境变量启用。NCCL 2.27 将支持范围扩展到 InfiniBand 结构,并新增 AllGather 和 ReduceScatter 的网内卸载支持。
3.3 并行策略的物理映射
NVLink vs InfiniBand 带宽鸿沟3.4 机架外 InfiniBand 与 RDMA
InfiniBand 规格演进- Fat-Tree 拓扑:AI 数据中心中广泛采用的标准拓扑之一(3-stage Clos / Fat-tree / Leaf-Spine-Leaf / Edge-Aggregation-Core)。对于基于 K 端口交换机的 3-stage 无阻塞 Fat-Tree,网络支持的服务器总数为 K³/4(K 需为偶数)。例如,K = 48 时可支撑 27,648 台服务器,远超万卡规模需求。
- GPUDirect RDMA:一种直接内存访问技术:NIC 通过 PCIe 基址寄存器(BAR)直接对 GPU HBM 执行 DMA 读写,完整绕过 CPU 和系统内存。
3.5 Scale-Up vs Scale-Out 与业界万卡实践
两个通信域的根本差异
TP 必须在 NVLink 域内,PP 和 EP 可容忍 Scale-Out 带宽。这是训练并行策略设计的第一约束。
业界万卡实践
传统云计算(VPC 网络)与 LLM 训练网络的流量模型完全不同。VPC 网络通常存在数万到数十万条并发连接(C10K、C100K甚至C1000K),每个 flow 都是连续的小流,带宽利用率较低(一般低于 NIC 容量的 20%),整体流量模式平稳,通常以小时级缓慢变化;
而 LLM Training 则只有几十到几百条 flow,但这些 flow 会周期性同步爆发,在 AllReduce 等阶段瞬间打满 400Gbps NIC 带宽,呈现典型的“低熵(low entropy)+ 高突发(bursty elephant flow)”特征。
这种模式会导致传统数据中心广泛使用的 ECMP 出现 hash polarization,产生严重负载不均,因此传统 Clos/FatTree 网络已经无法直接适配 AI 训练场景。
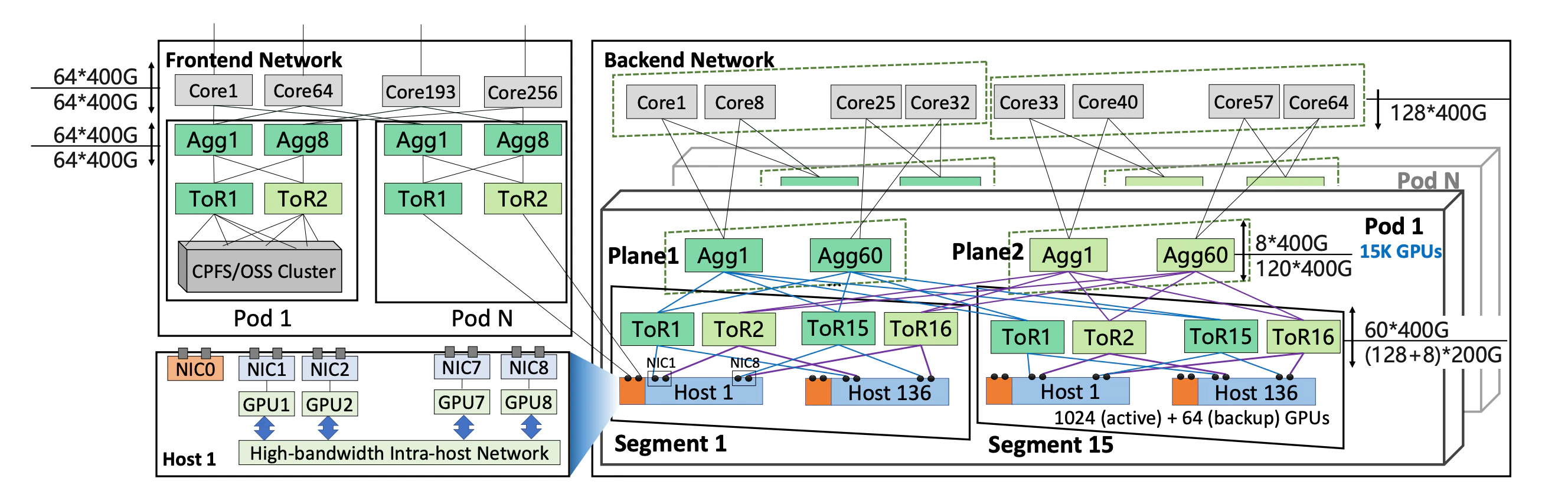
Ali HPN
4. Others
4.1 Power & Cooling
GB200 NVL72 Rack Power Breakdown
液冷系统:冷板(cold plate)贴合 GPU 和 CPU die,去离子水(加添加剂防腐蚀)通过 manifold 分配到各节点,CDU(Cooling Distribution Unit)负责循环和热交换。进水温度 45°C,出水温度约 60°C,流量 ~10–20 L/min。
下一代 NVL576(Vera Rubin 平台,~600 kW/rack)超出传统液冷极限,需采用双相浸没液冷。
PUE 对比:高密度 AI 数据中心中,传统风冷 PUE 通常约为 1.4–1.6,而 direct-to-chip 液冷可降至 1.1–1.3。
PUE: 是一个比率(计算机数据中心设施使用的能源总量与输送给计算设备的能源之比)。通俗理解是指计算设备使用了多少能源。一个理想的PUE是1.0,可以理解成照明、制冷等完全不需要用电,只有计算设备需要用电。
NVIDIA 官方没有直接公开“整柜额定功耗”,但行业里现在普遍按 GB200 NVL72 ≈ 120–140 kW / rack,规划设计一般按 130kW 规划。PUE = 1.2(现在 AI DC 很常见),1GW(PUE 1.2)≈ 6400 个 GB200 NVL72 rack, 对应 6400×72≈460,000 张 GPU 显卡。
电源演进:未来 800V DC 数据中心将进一步减少 AC/DC 转换级数,PDU 效率从 ~94% 提升至 ~98%。
4.2 GPU 虚拟化与共享机制
NVIDIA GPU 提供三种硬件/软件共享机制: MIG(Multi-Instance GPU):硬件级物理隔离 MIG 在硬件层面将一个 GPU 分割为最多 7 个独立实例,每个实例拥有独占的 SM 分区、L2 cache 分区、HBM 地址空间(SMMU 隔离)和 NVLink/PCIe 带宽配额。B200 支持 2×7 = 14 个 MIG 实例(通过双 die 物理分割)。 适合多租户推理平台,从根本上消除 GPU L2 cache 侧信道攻击面(USENIX Security 2021 已证明可行)。 MPS(Multi-Process Service):上下文合并 将多个进程的 CUDA Context 合并到单一硬件 Context 执行,多进程 kernel 可真正并发运行(SM 级别交织),消除 context switch 开销(传统切换 ~数十 μs)。代价:一个进程的 CUDA error 会导致整个 MPS 服务崩溃,隔离性差。适合推理服务场景(进程间信任,对隔离性要求低)。 理论上 MIG 和 MPS 可在同一 GPU 上组合使用(MPS 部署在 MIG 实例内),实现多层次资源池化。 Time-Slicing:软件级时间片 在同一 GPU 上虚拟出 N 个设备,通过 CUDA SM 时间片轮转调度。本质是软件模拟的多 GPU,无性能隔离:一个进程的 kernel 超出时间片会延迟其他进程,P99 延迟抖动大。仅适合开发测试,不适合 SLA 敏感的生产推理。4.3 Co-Packaged Optics(CPO)与光学互联

光模块
- 传输距离受限
- 高频损耗快速增加
- PCB 与连接器设计复杂度激增
- SerDes 功耗持续上升
CPO
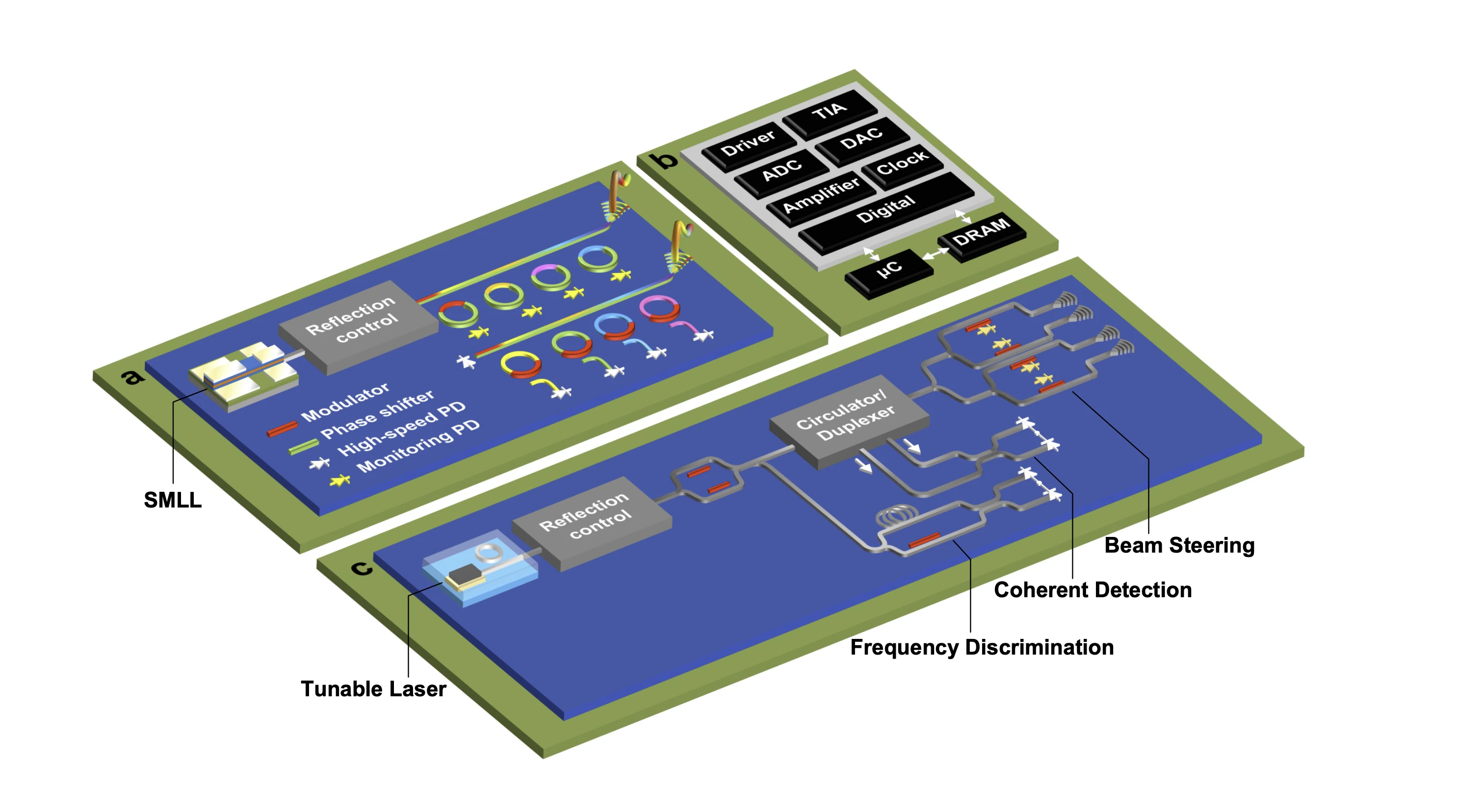
Silicon Photonics Roadmap
总结:从单芯片到数据中心的系统思维
理解这条物理约束链,是设计高效 AI 系统的根本认知基础。带宽层次与延迟层次的物理决定论,最终驱动了 MoE 稀疏架构、FP4 量化、SHARP 网内计算、以及层次化并行策略的兴起。
FAQ
这个光电转换是跨NVL72用的么?
这个光电转换是跨NVL72用的么?
是的。NVL72 机柜内部的 NVLink/NVSwitch 互连主要使用铜互连(copper backplane/ACC),而跨 NVL72 机柜进行 scale-out 时,则通过 NIC / SuperNIC 搭配光模块和光纤进行网络互联。
参考文档:https://docs.nvidia.com/enterprise-reference-architectures/nvl72-ai-factory/latest/components.html
LPU的加入会增加软件吗?比如之前tensor core引入了cublas和cutlass
LPU的加入会增加软件吗?比如之前tensor core引入了cublas和cutlass
是的。像 Groq 这类采用 compiler-driven architecture 的 LPU(Language Processing Unit)通常不仅会引入新的硬件执行单元,还会配套出现新的 compiler/runtime software stack。
从软件栈形态上看,架构与 TPU/XLA、TVM、MLIR backend 这一类 compiler ecosystem 更接近。
为什么 HBM 延迟比 GDDR 高?
为什么 HBM 延迟比 GDDR 高?
HBM 物理上通过 TSV 堆叠 DRAM die,虽然物理距离短,但每层 die 之间的信号需要通过 micro-bump 和 TSV 传输,每 pass 都有额外延迟。更关键的是,HBM 的 bank 结构和 row buffer 访问模式决定了随机访问时的平均延迟(约 400 周期)高于 GDDR(约 250 周期)。但 HBM 的优势在于 1024 位接口带来的超高聚合带宽,因此被优先用于吞吐优先而非延迟优先的 AI 训练场景。
为什么 Grace 使用 LPDDR5X 而非 DDR5?
为什么 Grace 使用 LPDDR5X 而非 DDR5?
带宽、功耗、容量的三角权衡。LPDDR5X 以焊接方式实现了 16 通道宽内存总线,同样带宽下功耗仅为 DDR5 的八分之一。在 130 kW 的机架功率预算下,节省的数十瓦 CPU 内存功耗可以转化为更多 GPU 的 TDP。代价是内存不可插拔更换,但数据中心场景中固定配置可接受。
NVLink 和 InfiniBand 如何协同工作?
NVLink 和 InfiniBand 如何协同工作?
NVLink 负责 Scale-Up 域内扩展(机架内 72 GPU 全互联,1.8 TB/s 带宽,~1 μs 延迟)。InfiniBand 负责 Scale-Out 域间扩展(跨机架连接,100 GB/s 带宽,~3 μs 延迟)。两者在软件栈(NCCL)中统一抽象,开发者无需手动区分——但理解物理拓扑是设计最优并行策略的前提。