录屏回看
本章概要
即使 GPU kernel 和库已经调到极致,系统层的瓶颈仍会拖累大规模训练与推理。真正决定 GPU 利用率的,往往是操作系统、驱动运行时、容器和集群调度的配置。本章逐层来看这些配置:- CPU / 操作系统:保证 CPU 持续为 GPU 供给数据和任务——NUMA 绑定、pinned memory、透明大页、调度与中断亲和性、虚拟内存与 swap、文件系统缓存、CPU 频率与内存分配器;
- GPU 驱动与运行时:提升单卡的性能与利用率——持久化模式、MPS / MIG 共享与切分、GPU 时钟与 ECC;
- 容器运行时:让容器以接近裸机的性能访问 GPU——NVIDIA Container Toolkit、overlay FS 与网络开销;
- Kubernetes:在集群层面分配 GPU——GPU Operator、Device Plugin、DRA、资源隔离与 QoS,以及从节点内 NUMA 到跨节点网络的拓扑感知调度。
1. CPU 与操作系统调优
GPU 利用率不足的一个常见根源在 CPU 端:CPU 没能及时、持续地为 GPU 供给数据和任务,GPU 于是被迫空等。训练和推理的具体形态不同,但影响 GPU 计算的 CPU 侧任务主要集中在几类:- 准备输入:训练时读取样本、tokenize、图像解码、数据增强和 batch 组装;推理时处理请求解析、tokenize、padding 和动态 batching。输入准备跟不上时,GPU 只能等待下一批数据或请求。
- 提交 GPU 任务:CPU 调用 CUDA API 完成 kernel launch、memory copy 和 stream synchronization,并把这些任务排进 CUDA stream。只有 CPU 完成提交后,GPU 才能开始执行对应 kernel。大量小 kernel 或频繁同步会放大 CPU 开销,导致 GPU 间歇性空闲。
- 搬运输入数据:输入通常先在 CPU memory 中生成,再通过 CPU → GPU copy 放入 GPU memory。
- 分布式通信:多 GPU 训练或分布式推理中,CPU 侧会发起 collective 或点对点通信,并依赖专门的通信辅助线程维护通信进度。这些线程被调度打断或阻塞时,GPU 可能因为等待其他 rank 或 device 而闲置。
- 处理设备中断:NIC/GPU 相关 interrupt 也需要 CPU 响应。如果中断落在远离设备或关键输入/通信线程的 NUMA node 上,或者频繁打断这些关键线程,都会增加访问延迟和调度开销,进而拉长 GPU 等待时间。
1.1 NUMA 感知与 CPU 绑定
1.1.1 什么是 NUMA
数据中心服务器通常是多路的 NUMA(Non-Uniform Memory Access,非统一内存访问)系统:每颗物理 CPU 拥有自己的内存控制器,直接连接一部分本地内存。每个 CPU 可以通过自己的内存控制器快速访问本地内存,也可以通过节点间链路访问另一个 CPU 的远程内存,但本地和远程内存的访问延迟和带宽不同,这就是”非统一”的含义。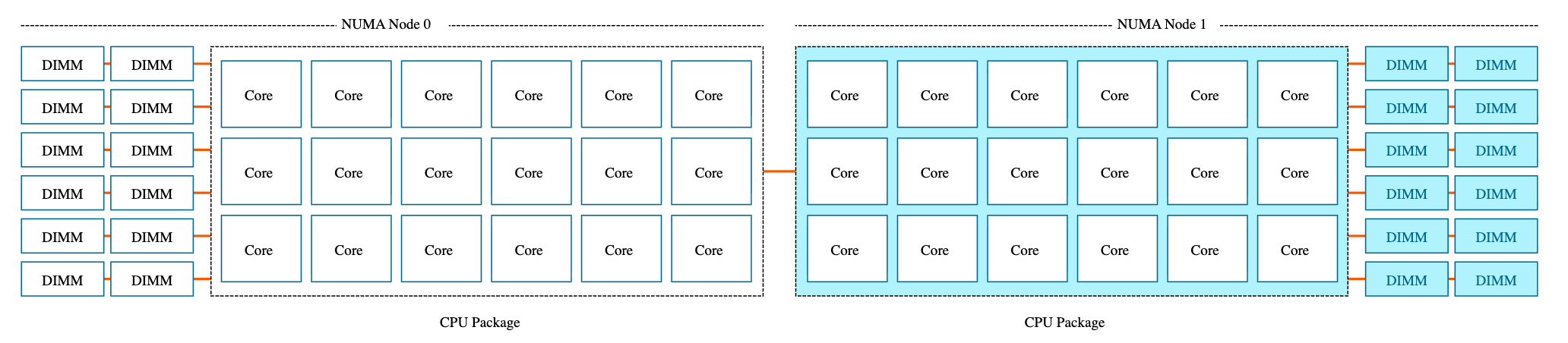
1.1.2 查看系统 NUMA 拓扑
你可以用以下两个命令结合查看系统的完整 NUMA 拓扑:numactl -H 的输出示例(4 个 NUMA 节点的服务器):
nvidia-smi topo -m 的输出示例(5 个 GPU 的服务器):
- 矩阵区域(GPU 之间的交叉格)— GPU 间的互连类型,与 Legend 对应:
X= 自己跟自己SYS= 经过 PCIe + 跨 NUMA 节点的 CPU 互连,如 QPI/UPI(最慢)NODE= 经过 PCIe + 同一 NUMA 节点内的 Host Bridge 互连PHB= 经过 PCIe Host Bridge,即经过 CPU(同一 NUMA 节点内)PXB= 经过多个 PCIe bridge,但不经过 Host BridgePIX= 经过最多一个 PCIe bridge(同一 PCIe switch 下)NV#= 通过 # 条 NVLink 直连(最快,如NV4= 4 条 NVLink)
- CPU Affinity 列 — 该 GPU 关联的 CPU 核心编号,如 GPU0 对应核心 48-63 和 112-127
- NUMA Affinity 列 — 该 GPU 属于哪个 NUMA 节点,这就是你做
numactl绑定时需要的值
1.1.3 使用 numactl 进行 CPU pinning
确认了 GPU 所在的 NUMA 节点后,需要显式指定 NUMA 亲和性(NUMA affinity)——将进程或线程分配到与 GPU 相同 NUMA 节点上的 CPU 核心。这种做法称为 CPU pinning。可以使用numactl 实现,两个关键参数:
--cpunodebind=<node>— 将进程的 CPU 线程限制在指定 NUMA 节点的核心上运行,防止 OS 调度器把线程迁移到其他节点。--membind=<node>— 将进程的内存分配限制在指定 NUMA 节点的本地 RAM 上,防止内存被分配到远程节点。
1.1.4 验证 NUMA 绑定的性能影响
可以使用下面的脚本对比 NUMA 绑定对 CPU→GPU 数据拷贝带宽的影响,保存为numa_bench.sh 后运行:
numa_bench.sh:NUMA 绑定性能对比脚本
numa_bench.sh:NUMA 绑定性能对比脚本
1.1.5 在 PyTorch DataLoader 中绑定 NUMA
书中给出了一个完整的 Python 示例(约 100 行),配套代码ch03/bind_numa_affinity.py 是其完整实现。整个流程分三步:
第一步:查询 GPU 所在的 NUMA 节点
启动时,进程需要知道当前 GPU 连接在哪个 NUMA 节点上。get_gpu_numa_node() 按优先级依次尝试四种方式:
- NVML 直接查询 — 调用
nvmlDeviceGetNumaNodeId(),直接获取 GPU 的 NUMA 节点编号。仅适用于 GPU 本身是 NUMA 节点的平台(如 Grace Hopper/Grace Blackwell 超级芯片)
验证:用 pynvml 调用 nvmlDeviceGetNumaNodeId
验证:用 pynvml 调用 nvmlDeviceGetNumaNodeId
numactl -H 看到的只有 CPU 和 CPU 内存的 NUMA 节点,看不到 GPU:numactl -H 会多出一个节点,那个节点的”内存”就是 GPU 的 HBM:- NVML CPU 亲和性推断 — 如果上一步不可用,调用
nvmlDeviceGetCpuAffinity()获取该 GPU 关联的 CPU 掩码(bitmask),然后与 sysfs 中的 CPU→NUMA 映射表对照,取出现次数最多的 NUMA 节点
验证:用 nvidia-smi topo -m 查看 CPU Affinity 列
验证:用 nvidia-smi topo -m 查看 CPU Affinity 列
- sysfs 内核接口 — 如果 NVML 完全不可用,直接读
/sys/bus/pci/devices/<PCI_ID>/numa_node,这是 Linux 内核为每个 PCI 设备维护的 NUMA 节点信息
验证:从 sysfs 读取每个 GPU 的 NUMA 节点
验证:从 sysfs 读取每个 GPU 的 NUMA 节点
nvidia-smi topo -m 输出的 NUMA Affinity 列一致。- 当前进程策略兜底 — 如果以上都失败,运行
numactl --show读取当前进程的 preferred node。例如如果外部已经用numactl命令启动了脚本(如numactl --cpunodebind=0),进程会继承这些策略,preferred node就是正确的值
验证:对比有无 numactl 指定 NUMA 策略时的 preferred node
验证:对比有无 numactl 指定 NUMA 策略时的 preferred node
bind_process_to_node() 做两件事——限制 CPU 核心 + 限制内存分配节点。其中 _libnuma 是 Linux 系统库 libnuma.so 的 Python 绑定(通过 ctypes.CDLL("libnuma.so") 加载),numactl 命令行工具底层也是调用它。在 Python 进程内部需要用它来动态设置 NUMA 内存策略,因为 numactl 只能在启动进程时从外部指定策略,无法在已运行的子进程内部重新绑定:
spawn 模式下)。通过 worker_init_fn 在每个 worker 启动时显式重新绑定:
单 GPU 模式输出示例
单 GPU 模式输出示例
多 GPU DDP 模式输出示例
多 GPU DDP 模式输出示例
Worker 是每个 rank 的 DataLoader worker 进程,由所属 rank 绑定,因此跟随该 rank 落到同一个节点。这样每个 rank 连同它的 worker 都和自己的 GPU 就近对齐。1.2 页锁定内存(Pinned memory)
创建 CPU tensor 时,tensor 内容会被放入内存。这里的内存指的是由 MMU(内存管理单元,Memory Management Unit)管理的一套虚拟内存(virtual memory)抽象:- RAM 与交换空间(swap space) 共同组成虚拟内存。它让程序看到的可用空间大于单独的物理 RAM。
- 普通 CPU tensor 默认是 pageable 的。Tensor 内容会被切成 page,这些 page 可以位于 RAM,也可以位于交换空间。
- Page fault:通常,当程序试图访问不在 RAM 中的 page 时,就会发生 page fault。此时,OS 会将该 page 调入 RAM。相应地,为了给新 page 腾出空间,OS 可能不得不将另一个 page 调出 RAM。
- Pinned memory 也叫 page-locked 或 non-pageable memory。它不能被换出到磁盘,因此访问时间更快、更可预测。
- 代价是容量更受限制。Pinned memory 会减少系统可自由分页的内存,不能无限制使用。
- 如果源数据在 page-locked memory 中,device 可以直接访问 RAM 中地址稳定的数据。
- 如果源数据在 pageable memory 中,相关 page 必须先回到 RAM,然后才能发送到 GPU。更准确地说,CUDA 会先为 pageable data 创建一份 page-locked copy,再执行 CPU → GPU transfer。
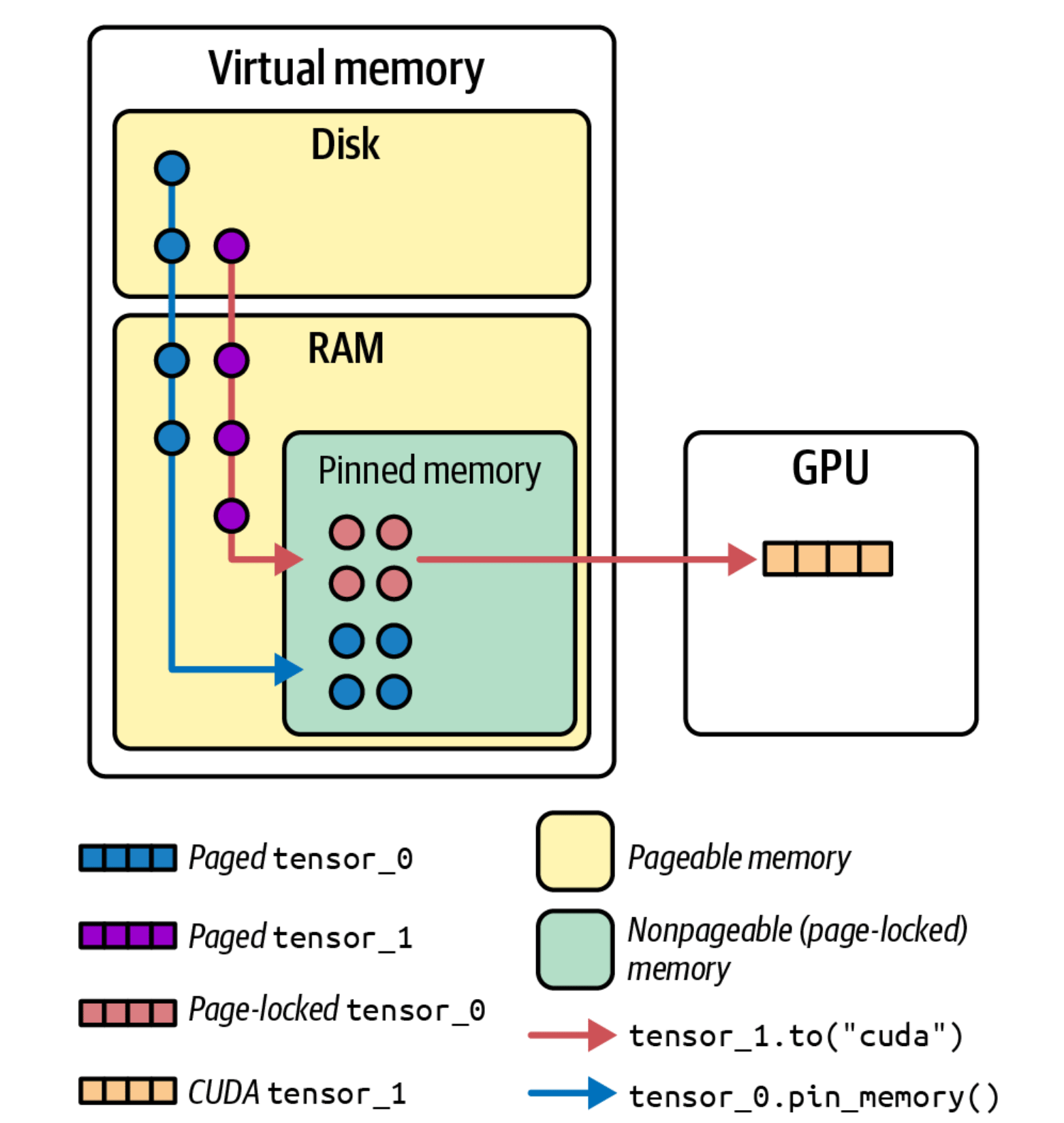
Pinned memory(也称 page-locked 或 nonpageable memory)是一类不能被换出到磁盘的内存。
内存区域、Tensor 位置与数据流
内存区域、Tensor 位置与数据流
- 浅黄色区域:Pageable memory。普通 CPU 内存,属于虚拟内存体系。它的页可能在 RAM,也可能被换出到 Disk,操作系统也可能移动这些页。
- 浅绿色区域:Pinned memory / page-locked memory。仍然是 CPU RAM,但这些页被锁住,不能被 swap,也不能被随意迁移。
- 图右侧区域:GPU memory。CUDA tensor 真正所在的显存。
- 蓝色和紫色小块:还在 pageable memory 里的 paged tensor。
- 红色小块:已经 pin 住的 page-locked tensor。
- 橙色小块:GPU 上的 CUDA tensor。
- 蓝色箭头:
pin_memory()把 pageable tensor 锁进 pinned memory。 - 红色箭头:
.to("cuda")把 pinned tensor 拷贝到 GPU。
DataLoader 传入 pin_memory=True 会自动把取回的 tensor 放到 pinned memory 中,从而让它们更快地传输到支持 CUDA 的 GPU。
此外,一旦 tensor 位于 pinned memory 中,就可以使用异步 GPU copy。只需要在 .to() 或 .cuda() 调用中额外传入 non_blocking=True。这可以用来让数据传输与计算重叠。
- PyTorch tutorial: A guide on good usage of
non_blockingandpin_memory() - PyTorch DataLoader: Memory Pinning
- PyTorch CUDA semantics: Use pinned memory buffers
1.3 透明大页(Transparent Hugepages)
Linux 内存管理通常使用 4 KB 的页;但当进程使用数十或数百 GB 内存时,例如深度学习数据集、预取批次、模型参数等,管理数以百万计的小页会非常低效。 透明大页(Transparent Hugepages,THP)是一种自动使用大页的机制。大页——2 MB 甚至 1 GB 的页——可以通过增大内存块来减少虚拟内存管理的开销。主要好处是减少缺页中断,并减轻 TLB(translation lookaside buffer)的压力。1.3.1 TLB 地址转换
TLB 是 CPU 用来把虚拟地址映射到物理地址的缓存。页更少、更大时,同样数量的 TLB 条目可以覆盖更多内存,从而减少 TLB miss。TLB 的地址转换过程
TLB 的地址转换过程
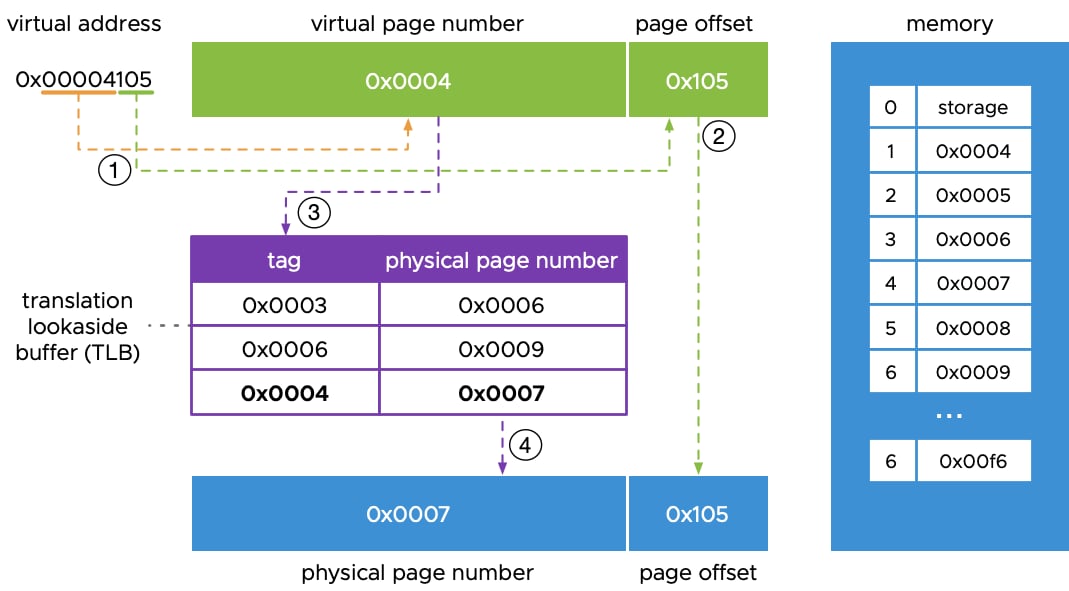
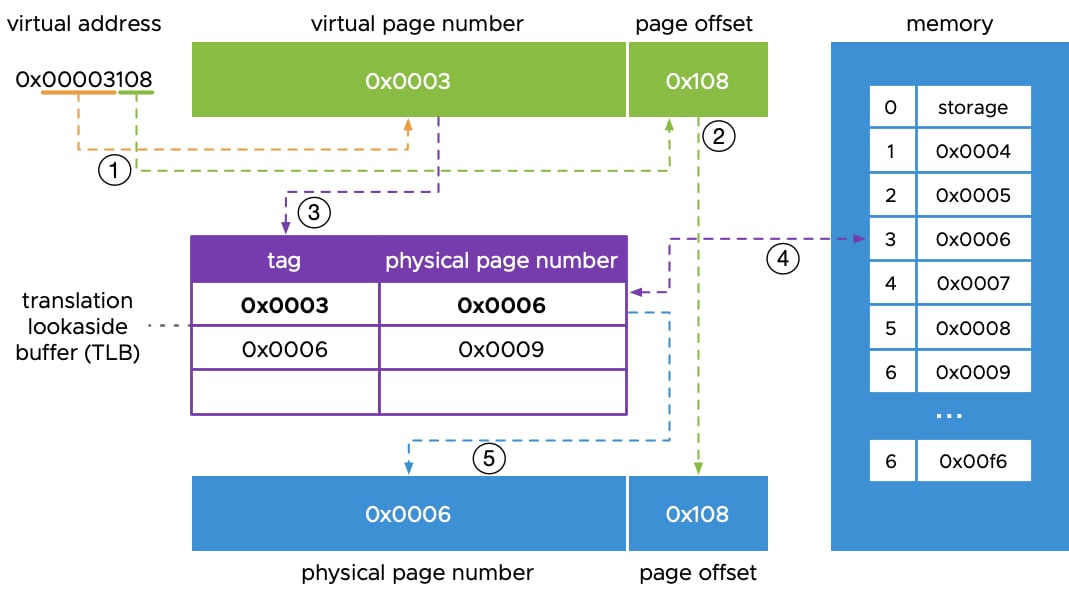
1.3.2 THP 配置
- 收益幅度:Hugepages 通常带来的是中等幅度收益,吞吐提升常见在 3%–5% 左右。
- Pinned memory 限制:使用大块 pinned memory 时,需要把
ulimit -l调高或设为 unlimited;如果这个限制过低,pin memory 可能失败,进而回退到可交换内存,或者触发 OOM。 - 推理延迟风险:THP 的后台 compaction 可能引入不可预测的暂停,这对延迟敏感的 LLM 推理是高风险。
- Defrag 策略:
defrag控制内核是否为了分配 THP 做内存整理。THP 需要连续的物理内存,如果当前内存碎片较多,内核可能触发 compaction 来凑出连续空间,这个过程会增加延迟抖动。 - 训练与推理取舍:Linux 默认会尽可能自动分配 2 MB 的 THP。吞吐优先的训练 workload 通常启用 THP;延迟优先的推理 workload 通常完全禁用。
vm.nr_hugepages 或 hugetlbfs,以获得更可预测的性能。它和 THP 不同:THP 由内核自动尝试分配大页;显式 hugepages 需要提前预留,并由应用或 runtime 明确使用。
1.4 调度器与中断亲和性
CPU 侧抖动通常来自三个方面:- 线程调度:关键数据管道线程或通信辅助线程如果长时间排队、频繁被抢占,就会形成 CPU 侧调度抖动,进而让 GPU 因等待输入或通信而空闲。
- CPU 隔离:这些线程如果和其他 workload 混跑在同一组 CPU 上,容易争抢 CPU core、cache 和内存带宽,响应时间会变得不稳定。
- 中断亲和性:GPU/NIC 中断请求(Interrupt Request,IRQ)如果由远离设备的 CPU 处理,或者频繁打断关键线程,会增加额外延迟。
1.4.1 线程调度
在繁忙的系统上,需要确保数据管道线程等重要线程不会被频繁中断。Linux 默认使用完全公平调度器(Completely Fair Scheduler,CFS),对大多数情况都有效。 但如果有一个对延迟非常敏感、例如需要为 GPU 提供数据的线程,可以考虑对该线程使用实时的先进先出(FIFO)或轮转(RR) 优先级调度。这样可以确保高优先级线程在不被普通优先级线程抢占的情况下运行。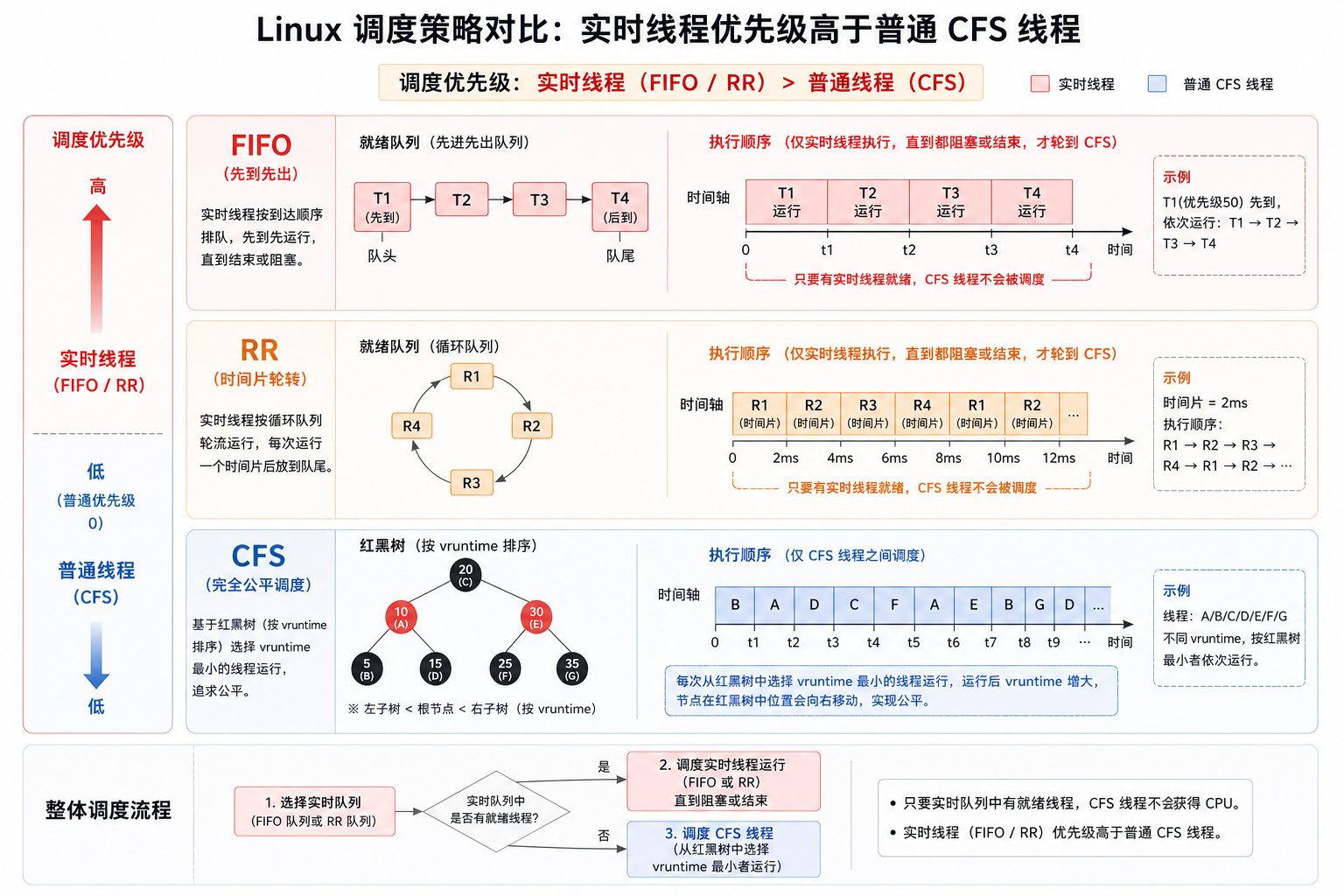
CFS 中 vruntime 的计算方式
CFS 中 vruntime 的计算方式
vruntime);运行得越少的 task,vruntime 越小,越容易被选中。任务进入 runnable 状态后,会被放入红黑树(red-black tree)。nice 值通常范围是 -20 到 19,数值越小,普通线程的调度优先级越高。每个 nice 值对应一个权重,nice=0 的权重是 1024。Linux 使用预定义的 nice 权重表,相邻 nice 级别大约相差 1.25 倍:nice 每降 1,权重约增加 25%;nice 每升 1,权重约减少 20%。nice 权重如下:10 ms:10 ms,vruntime 增加更少,因此更容易保持在红黑树左侧,也更早再次被 CFS 选中运行。设置调度策略
设置调度策略
PSR:线程当前运行过的 CPU 编号。POL:调度策略。TS是普通 CFS 时间共享策略,FF对应SCHED_FIFO,RR对应SCHED_RR。RTPRIO:实时优先级。普通 CFS 线程通常显示为-。NI:nice 值,只影响普通 CFS 线程的权重。
chrt 设置实时 FIFO 或 RR 策略:chrt -p <tid> 的输出示例:1.4.2 CPU 隔离
CPU 隔离的目标,是将关键输入线程、通信辅助线程与其他工作负载尽量分开运行,减少它们受到调度器负载均衡、内核工作队列、定时器和中断请求等系统噪声的干扰。- 临时绑定:
taskset适合排查和实验,可以把进程或线程绑定到指定 CPU。 - 生产隔离:cgroup
cpuset更适合生产环境。cpuset.cpus约束任务可运行的 CPU,cpuset.mems约束可使用的 NUMA memory node。 - 容器约束:容器环境中可以用
docker run --cpuset-cpus固定 CPU 范围,用--cpuset-mems固定 memory node。 - 启动参数:
isolcpus、nohz_full、irqaffinity可以做更强的启动期隔离,但运行期调整不如 cgroup 灵活,适合非常明确的低延迟节点。
CPU 隔离配置示例
CPU 隔离配置示例
isolcpus、nohz_full、rcu_nocbs 和 irqaffinity。这些参数需要写入 /etc/default/grub 中的 GRUB_CMDLINE_LINUX,更新 GRUB 并重启后生效。isolcpus=8-15:让普通调度器尽量不要把普通任务放到 CPU8-15上。nohz_full=8-15:减少这些 CPU 上的周期性调度时钟中断。rcu_nocbs=8-15:把 RCU callback 从这些 CPU 上移走,减少内核后台干扰。irqaffinity=0-7:默认把 IRQ 放到 CPU0-7,让 CPU8-15更干净。
isolcpus=8-15 不会自动把训练/推理进程放到 CPU 8-15。它只是减少普通系统任务对这些 CPU 的占用。真正把 workload 放进去,还是要配合 taskset、cgroup cpuset 或容器的 --cpuset-cpus。1.4.3 中断亲和性
IRQ(Interrupt Request)是硬件或内核子系统通知 CPU 处理事件的一种机制。CPU 收到中断后,会暂停当前正在执行的普通任务,转去执行对应的中断处理逻辑。 常见 IRQ 类型包括:- 设备中断:来自 NIC、GPU、NVMe 等硬件设备。例如网卡收到数据、发送完成、RDMA 操作完成事件,或者 GPU 任务完成、错误和事件通知。
- 定时器中断:来自系统 timer,用于调度器计时、时间片管理和周期性内核任务。
- 核间中断(Inter-Processor Interrupt,IPI):一个 CPU core 向另一个 CPU core 发送的中断,常见于 TLB shootdown、调度唤醒等场景。
- IRQ affinity:控制某个 IRQ 由哪些 CPU core 处理。
中断亲和性配置示例
中断亲和性配置示例
1.5 虚拟内存与 Swap
不言而喻,应尽量避免发生内存交换。一旦进程的部分内存被换出到磁盘,性能往往会出现灾难性的、跨数量级的下降。GPU 程序通常会分配大量主机内存用于数据缓存;如果操作系统将其中一部分换出到磁盘,那么当 GPU 相关流程再次需要访问这些数据时,就会遭遇巨大的延迟。swappiness 的含义
swappiness 的含义
vm.swappiness 控制 Linux 在内存压力下使用 swap 的倾向,取值通常是 0 到 100。数值越高,内核越倾向于把匿名页换出到 swap;数值越低,内核越倾向于把数据留在 RAM 中。建议设置 vm.swappiness=0,它告诉 Linux 除非遇到极端内存压力,否则应尽量避免 swap。需要强调的是,vm.swappiness=0 不等于完全禁用 swap;它只是降低内核使用 swap 的倾向,在极端内存压力下仍然可能发生 swap。 如果需要完全关闭 swap,需要使用 swapoff -a,或者在 cgroup v2 中设置 memory.swap.max=0。Swap 配置示例
Swap 配置示例
1.6 文件系统缓存
对于大型训练任务,最佳实践是频繁将 checkpoint 写入磁盘,以便在需要时能从已知的良好 checkpoint 重新启动失败任务。然而,在进行 checkpoint 写入时,大量数据的突发写入可能会填满操作系统 page cache 并导致停顿。 常见解决方案包括: 继续使用 page cache,但降低冲击:- 调整写回阈值:调整 dirty page 阈值,控制内核什么时候开始后台写回,以及什么时候阻塞写入进程。
- 异步写 checkpoint:使用 PyTorch Distributed Checkpoint(DCP)async_save,把 checkpoint 写入从训练主 loop 中移出去。
async_save()会返回 future,需要控制并发 checkpoint 数量,避免 CPU memory 压力叠加。 - 分片写 checkpoint:使用 PyTorch Distributed Checkpoint(DCP),让多个 rank 写各自的 checkpoint 分片,避免单 rank 或单文件形成过大的突发写入。
- 丢弃 checkpoint cache:写完后调用
posix_fadvise(fd, 0, 0, POSIX_FADV_DONTNEED),提示内核尽快丢弃 checkpoint 对应的 page cache。
PyTorch DCP 异步 checkpoint 示例
PyTorch DCP 异步 checkpoint 示例
AppState 是对 model 和 optimizer 的 Stateful 包装,用来让 DCP 保存和恢复分布式 state dict。checkpoint_size_per_rank × rank 数量 增加。如果模型很大,普通 async_save() 的 GPU → CPU staging 仍可能阻塞训练 loop。PyTorch 2.9 引入了 DefaultStager,可以把 state dict 创建和 GPU → CPU copy 也放到后台线程中:DefaultStager 会引入后台线程,占用额外 CPU 资源。训练节点需要预留足够 CPU core,否则异步 checkpoint 本身也可能影响输入管道或通信辅助线程。后台写回的含义
后台写回的含义
- Direct I/O:延迟敏感的训练 workflow 可以评估
O_DIRECT、io_uring和 GPUDirect Storage。 - 适用条件:这类方式需要文件系统、存储设备和 I/O 栈支持 direct I/O,适合已经验证过 I/O 路径的场景。
1.7 CPU 频率与 C-states
许多计算节点默认会让 CPU 运行在省电模式下:CPU 空闲时可能被降频,或者进入低功耗睡眠状态。这可以节省能耗、降低发热和成本。训练过程中,GPU 在处理当前 batch 时,CPU 不一定始终处于 100% 利用率;但当新的数据准备、kernel launch 或通信任务到来时,CPU 从低频或睡眠状态恢复会引入额外延迟。 为了获得更高且更稳定的性能,AI 系统通常会把 CPU frequency governor 配置为performance。 该模式会让 CPU 尽量保持在较高频率,减少频率切换带来的延迟抖动。这个配置可以通过 cpupower frequency-set -g performance 完成,也可以在 BIOS 中设置。
CPU 空闲状态(C-states)同样会影响延迟稳定性。C-states 是 ACPI 规范定义的 CPU 省电模式:CPU core 空闲时可以进入 C-state 来节省能耗。C0 表示 active 状态,C0 以上表示更深的睡眠状态。C-state 越深,省电越多,但新的工作到来时,core 唤醒所需时间也越长。限制或禁用深层 C-states 可以减少额外的延迟尖峰。
CPU 频率的查看与设置
CPU 频率的查看与设置
driver表示 Linux 当前用来管理 CPU 频率的驱动,并执行升频、降频、切换 governor 这些操作,这里是acpi-cpufreq。hardware limits表示硬件支持的频率范围。available cpufreq governors表示可选 governor。current policy表示当前频率策略;示例中 governor 是performance。current CPU frequency表示当前 CPU 频率。boost state support表示 CPU 是否具备动态加速频率(boost)能力。动态加速频率是 CPU 官方支持的自动加速机制;在温度、功耗、电流等条件允许时,CPU 可以自动运行到更高频率。Supported: yes表示硬件和驱动支持动态加速频率。Active: yes表示动态加速频率已启用,CPU 在满足温度和功耗条件时可以临时把频率拉到更高档位。Pstate-Px列出了 CPU 可用的性能状态档位,频率从高到低;当前 governor 会根据自己的策略选择使用哪个频率档位。
cpupower 后支持配置文件,可以把 governor 持久化到服务配置中:C-states 的查看与设置
C-states 的查看与设置
CPUidle driver表示 CPU idle 驱动,这里是acpi_idle。CPUidle governor表示 idle state 选择策略,这里是menu。menu是常见的默认策略,会根据下一次 timer 事件、历史 idle 时长、延迟需求等信息,预测该进入哪个 idle state。Available idle states表示当前 CPU 可进入的 idle states:POLL表示轮询状态。有任务执行时 CPU 处于C0;没有任务执行时,CPU 可以进入POLL这种 idle state 轮询等待新任务。它的Latency: 0,唤醒延迟最低,但更耗电。C1、C2表示更深的空闲状态;示例中C2的Latency: 400,唤醒延迟明显高于C1。
Usage表示进入该 idle state 的次数,Duration表示累计停留时间。
processor.max_cstate=1 intel_idle.max_cstate=0,限制 CPU 进入深层睡眠状态。1.8 Host 内存分配器调优
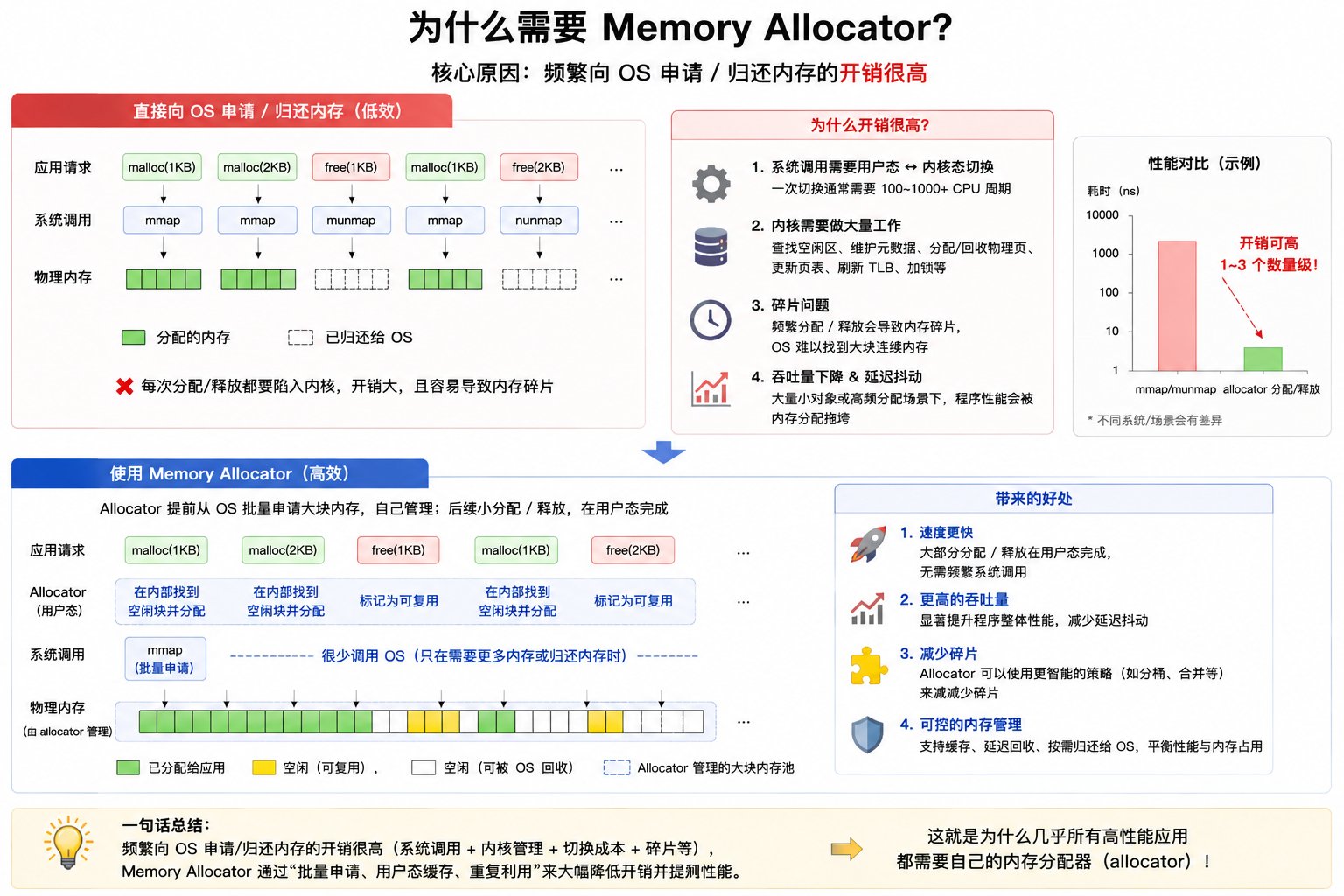
在 GPU 计算中,CPU 需要持续准备 batch 并及时送给 GPU。优化 memory allocator 可以减少内存分配带来的卡顿和抖动,避免 GPU 等待数据,从而维持高 GPU 利用率和整体吞吐。memory allocator 的作用
memory allocator 的作用
ptmalloc、jemalloc 与 tcmalloc 对比
ptmalloc、jemalloc 与 tcmalloc 对比
malloc,其底层实现通常称为 ptmalloc。它兼容性好,但在高并发数据管道中可能出现 arena 膨胀、碎片和 RSS(Resident Set Size,常驻集大小)不回收。jemalloc 和 tcmalloc 是常见替代 allocator,优势主要体现在降低多线程锁竞争、改善碎片控制,以及更灵活地管理释放后的内存。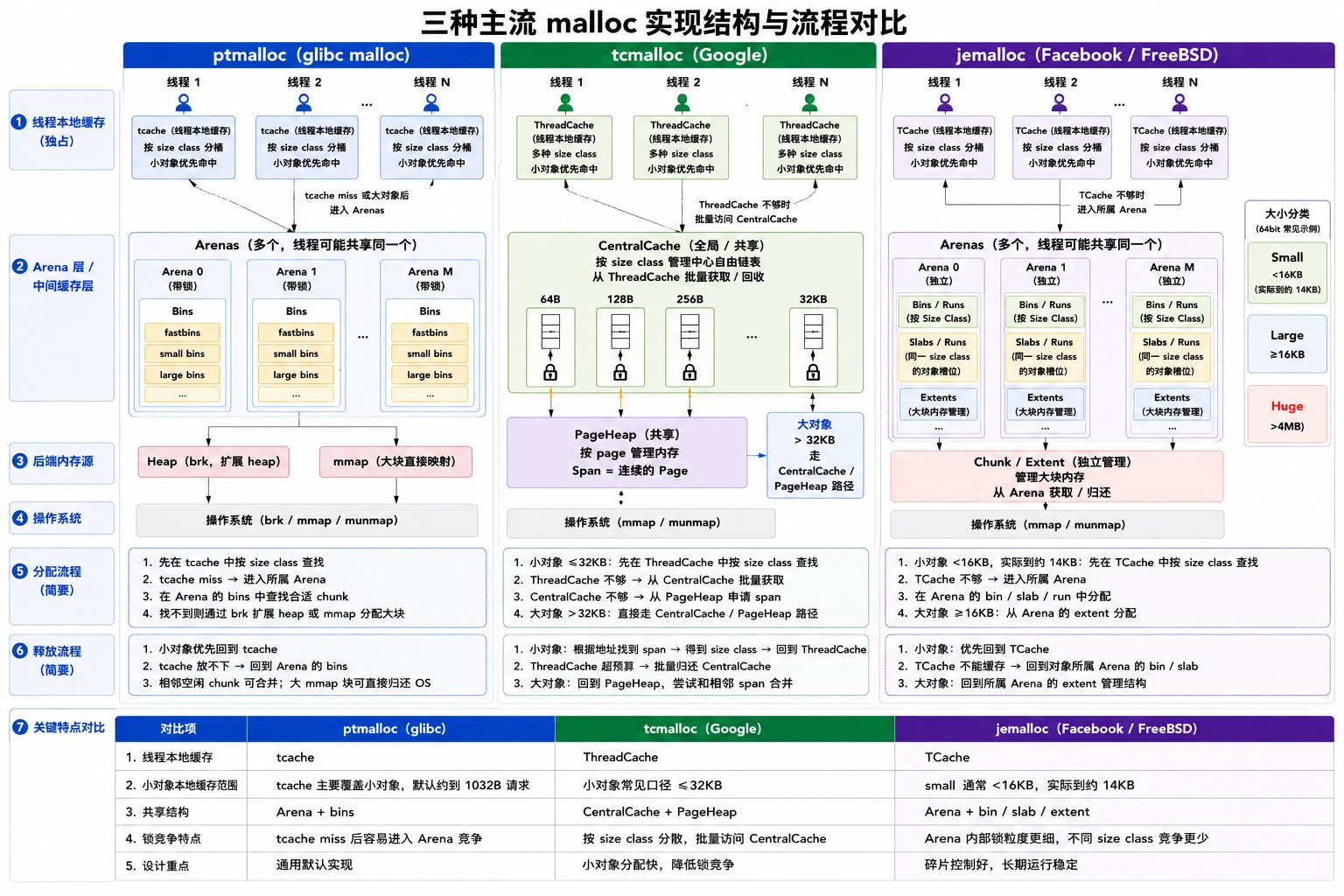
tcache 命中。tcache 是线程本地缓存,主要缓存小对象;在 64-bit glibc 默认配置下,tcache 可服务的请求大小最大约为 1032B。如果 tcache 没命中,请求会进入对应的 arena,在 arena 的 bins 中查找合适的空闲 chunk。较小的 chunk 通常从 fastbins / small bins 复用,较大的 chunk 会从 large bins 查找。如果 bins 中没有合适空间,则通过 brk 扩展 heap,或通过 mmap 向操作系统申请新内存。大块分配通常更可能走 mmap,默认阈值从约 128KB 开始,并可能动态调整。释放流程:释放时,如果 chunk 大小适合且当前线程的 tcache 还有空间,会优先放回 tcache;否则回到对应 arena 的 bins。相邻空闲 chunk 在合适情况下会合并,较大的 mmap 内存块也可能直接归还给操作系统。锁竞争特点:tcache 命中时很快,但 tcache miss、tcache flush、较大对象分配、跨线程释放等情况仍可能进入 arena。多个线程共享同一个 arena 时,即使操作不同 size class,也可能竞争 arena 相关锁,因此高并发下更容易出现性能抖动。tcmalloc(Google)分配流程:tcmalloc 的核心是让小对象优先走线程本地缓存。小对象常见口径是 ≤32KB,会优先从当前线程的 ThreadCache 按 size class 获取。如果 ThreadCache 不够,会从共享的 CentralCache 批量补充;如果 CentralCache 也不够,再从 PageHeap 获取 span。span 是一段连续 page,可以被切成小对象,也可以承载大对象。大对象通常指 >32KB 的请求,一般绕过 ThreadCache,直接走 CentralCache / PageHeap 路径。释放流程:小对象释放时,会根据地址找到所属 span 和 size class,然后优先放回当前线程的 ThreadCache。如果 ThreadCache 超过预算,会批量归还一部分对象给 CentralCache。大对象释放时,会回到 PageHeap,并尝试和相邻空闲 span 合并。锁竞争特点:tcmalloc 的优势是大量小对象分配可以在线程本地完成;缓存不够时,也是批量访问 CentralCache,不是每次 malloc / free 都访问共享结构。同时,CentralCache 按 size class 分散管理,不同 size class 通常不会竞争同一把锁,因此锁竞争通常比 ptmalloc 更低。jemalloc(FreeBSD / Facebook)分配流程:jemalloc 也有线程本地缓存,叫 TCache。小对象优先从 TCache 按 size class 获取;如果没有命中,再进入线程关联的 arena。jemalloc 不是每个线程一个 arena,多个线程可能共享同一个 arena。large object 不走 slab,而是由 arena 通过 extent 管理。释放流程:小对象通常先回到当前线程的 TCache;如果不能缓存,就回到对象所属 arena 的 bin / slab。large object 会回到所属 arena 的 extent 管理结构。释放的内存通常回到对象原本所属的 arena,而不是简单回到当前调用 free 的线程对应的 arena。锁竞争特点:jemalloc 和 ptmalloc 都可能多个线程共享 arena,但 jemalloc 的 arena 内部拆得更细:不同 size class 通常对应不同 bin,bin / slab / extent 的锁粒度也更细。因此两个线程即使共享同一个 arena,只要操作不同 size class,通常也不容易竞争同一把 arena 级别的大锁。jemalloc 的 arena、bin、slab、run 与 extent
jemalloc 的 arena、bin、slab、run 与 extent
bin,再从这个 bin 管理的 slab / run 中取一个空闲 object。large object 不走 slab,通常由 extent 管理。- arena:allocator 内部的一个内存管理域,负责维护 bins、large allocation、锁和统计信息。多线程程序可以分散到多个 arena,减少锁竞争,但 arena 过多也可能让 RSS 变高。
- bin:arena 内按 size class 划分的小对象管理结构。比如
64B bin、128B bin,每个 bin 通常管理一批对应尺寸的 slab / run。 - slab:一段被切成固定大小 object 的内存块。一个
64B slab只切 64B object,一个128B slab只切 128B object。一个 slab 里会有多个 object,用来批量服务同一 size class 的小对象分配,减少频繁向 OS 申请内存的开销。 - run:可以理解为 slab 的近似概念,常用于描述一段连续内存被切成多个同尺寸 object 的结构;在不同 allocator 或不同版本文档里,
run和slab的命名可能不同。 - object:slab / run 被切分后得到的固定大小内存槽位,也是最终返回给应用的一次小对象分配结果。
- extent:jemalloc 中按 page 粒度管理的一段连续虚拟内存范围。小对象 slab / run 可以由 extent 支撑,large object 也可能直接由 extent 管理。
jemalloc 和 tcmalloc 配置
jemalloc 和 tcmalloc 配置
jemalloc 或 tcmalloc 前,系统中需要有对应的动态库;随后可以通过 LD_PRELOAD 让目标进程在启动时优先加载对应 allocator。MALLOC_CONF 是 jemalloc 的配置环境变量。jemalloc 可以把分配分散到多个 arena,减少多线程分配时的锁竞争;也可以启用后台线程,在业务线程之外做内存清理。下面是一组常见配置: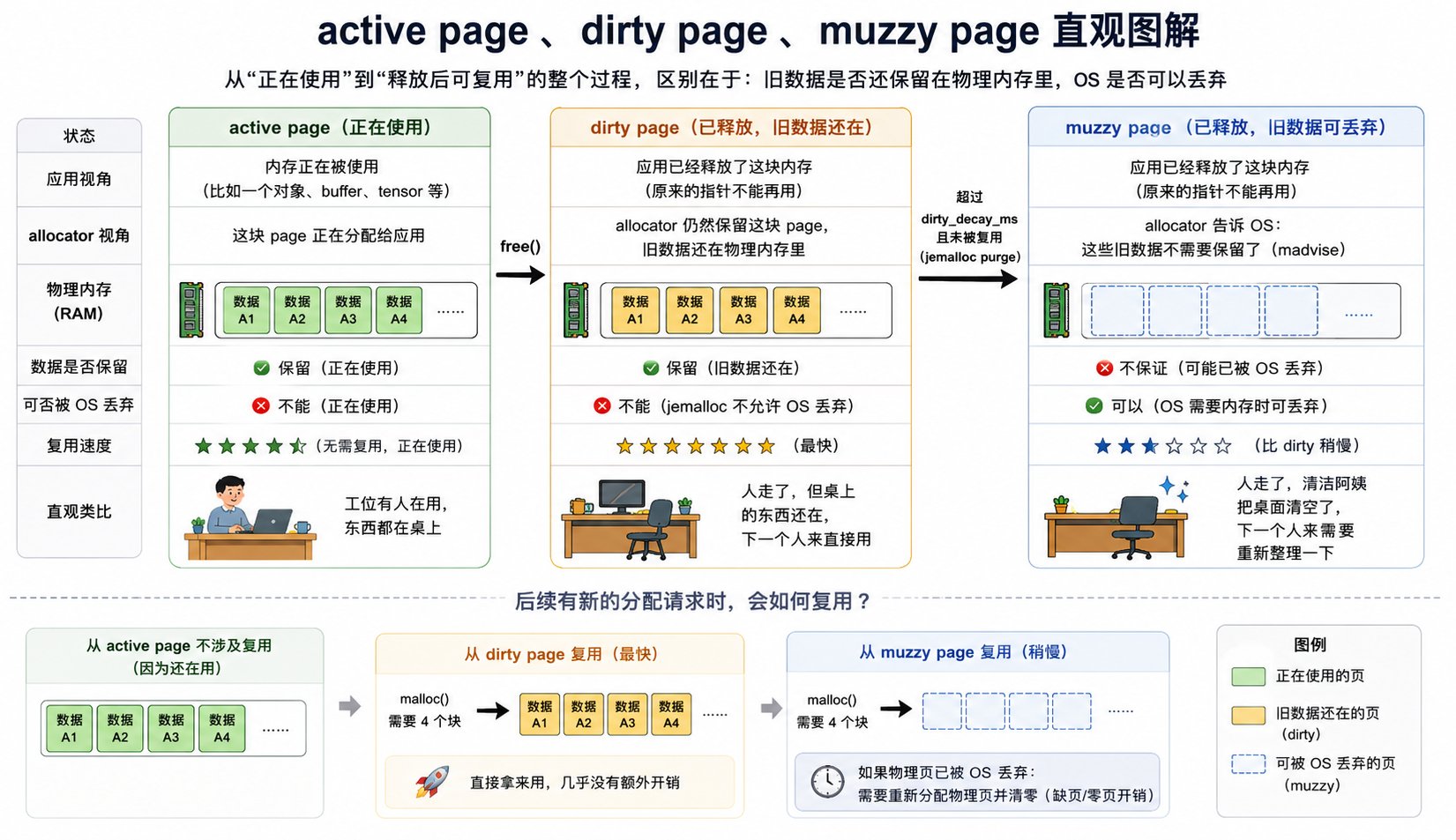
narenas:8设置 arena 数量为 8。arena 多一些可以降低多线程锁竞争,但太多也可能增加内存占用。background_thread:true启用后台线程做内存清理,避免释放后的清理工作直接卡在业务线程上。dirty_decay_ms:10000控制 dirty pages 延迟多久再回收或归还,10000表示 10 秒。dirty page 指应用已经释放、但内容还保留的页面,jemalloc 可以直接复用。muzzy_decay_ms:10000控制 muzzy pages 的回收延迟,也设成 10 秒。muzzy page 指应用已释放、旧数据不需要保留,但虚拟地址范围仍留在进程里的页面。与 dirty pages 相比,muzzy pages 再次被分配时往往需要重新触发 page fault 并补入物理页,因此复用成本通常更高。- 把 dirty / muzzy page 的回收延迟调长,可以减少频繁向 OS 申请/归还内存的开销,但 RSS 可能保持得更高。RSS(Resident Set Size)表示进程当前实际占用的物理内存;应用释放对象后,allocator 可能先把内存留在 arena 或 cache 里复用,不一定马上还给 OS。
tcmalloc 使用自己的 TCMALLOC_* 环境变量。TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES控制所有 thread cache 可占用的总大小。值越大,线程本地分配越容易命中 cache,但 RSS 可能更高。TCMALLOC_RELEASE_RATE控制 tcmalloc 把空闲内存归还给 OS 的积极程度。值越大,释放越积极;值太大可能增加向 OS 申请/归还内存的开销。
/proc/$PID/maps查看某个进程实际映射到地址空间里的动态库。- 这里必须换成目标训练或推理进程的 PID;查
/proc/1/maps只是在看 PID 1 是否加载了 allocator。 - 如果没有输出,说明这个进程启动时没有加载
jemalloc或tcmalloc。
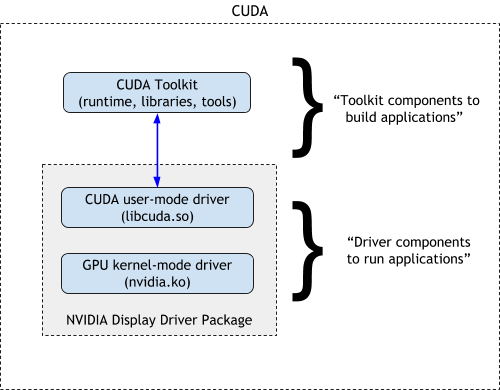
2. GPU 驱动与运行时设置
GPU 驱动与运行时里有一些会影响性能的设置,尤其在多 GPU、多用户场景下。这些设置配置得当,能降低额外开销,也能让多个负载更好地共享同一张 GPU。2.1 持久化模式(Persistence Mode)
默认情况下,如果没有应用正在使用 GPU,driver 可能让 GPU 进入更低功耗状态,并卸载部分驱动上下文。下一次应用重新使用 GPU 时,driver 需要重新初始化 GPU,这个冷启动过程可能带来一两秒级别的延迟。对于频繁启动/停止 job 的训练集群,或者低流量但延迟敏感的推理服务,这类初始化开销会影响整体性能。 在 Linux 上,client 通过打开 GPU device file 来 attach GPU;关闭 device file 时,相当于 detach GPU。只要还有 client 保持 device file 打开,GPU state 就会继续留在 driver 中。nvidia-persistenced 的核心做法,是在后台运行并保持 GPU device file 打开。这样即使没有训练或推理进程正在使用 GPU,driver 也会继续保留 GPU state,从而避免下一个 job 到来时重新初始化。持久化模式不会让 GPU kernel 的数学计算更快,但能减少作业启动延迟和 idle 后首次 CUDA 调用的冷启动停顿;代价是 GPU 空闲时功耗会略高。
Kubernetes 中通过 GPU Operator 启用持久化模式
Kubernetes 中通过 GPU Operator 启用持久化模式
driver.enabled=true,GPU Operator 会部署 nvidia-driver-daemonset 来管理节点侧 NVIDIA driver,并启动 nvidia-persistenced,从而启用持久化模式。2.2 Multi-Process Service (MPS)
通常,当多个进程共享同一张 GPU 时,GPU 调度器会在它们之间做时间片切换。例如,如果两个 Python 进程各自都有一些 kernel 要在同一张 GPU 上运行,GPU 可能先执行一个进程的 kernel,再执行另一个进程的 kernel,如此往复。如果这些 kernel 很短,并且它们之间存在空闲间隔,GPU 就可能因为反复进行上下文切换、而不是把这些任务重叠执行,导致利用率不足。 NVIDIA MPS 提供了一种机制,让多个进程可以在同一张 GPU 上并发运行,而不必严格依赖时间片切换。启用 MPS 后,只要 GPU 资源可用,例如 streaming multiprocessors(SMs)、Tensor Cores 等,GPU 就可以同时执行来自不同进程的 kernel。MPS 本质上是把多个进程的上下文合并到一个调度上下文中。这样一来,就不必为独立进程之间的切换和空闲等待付出完整代价。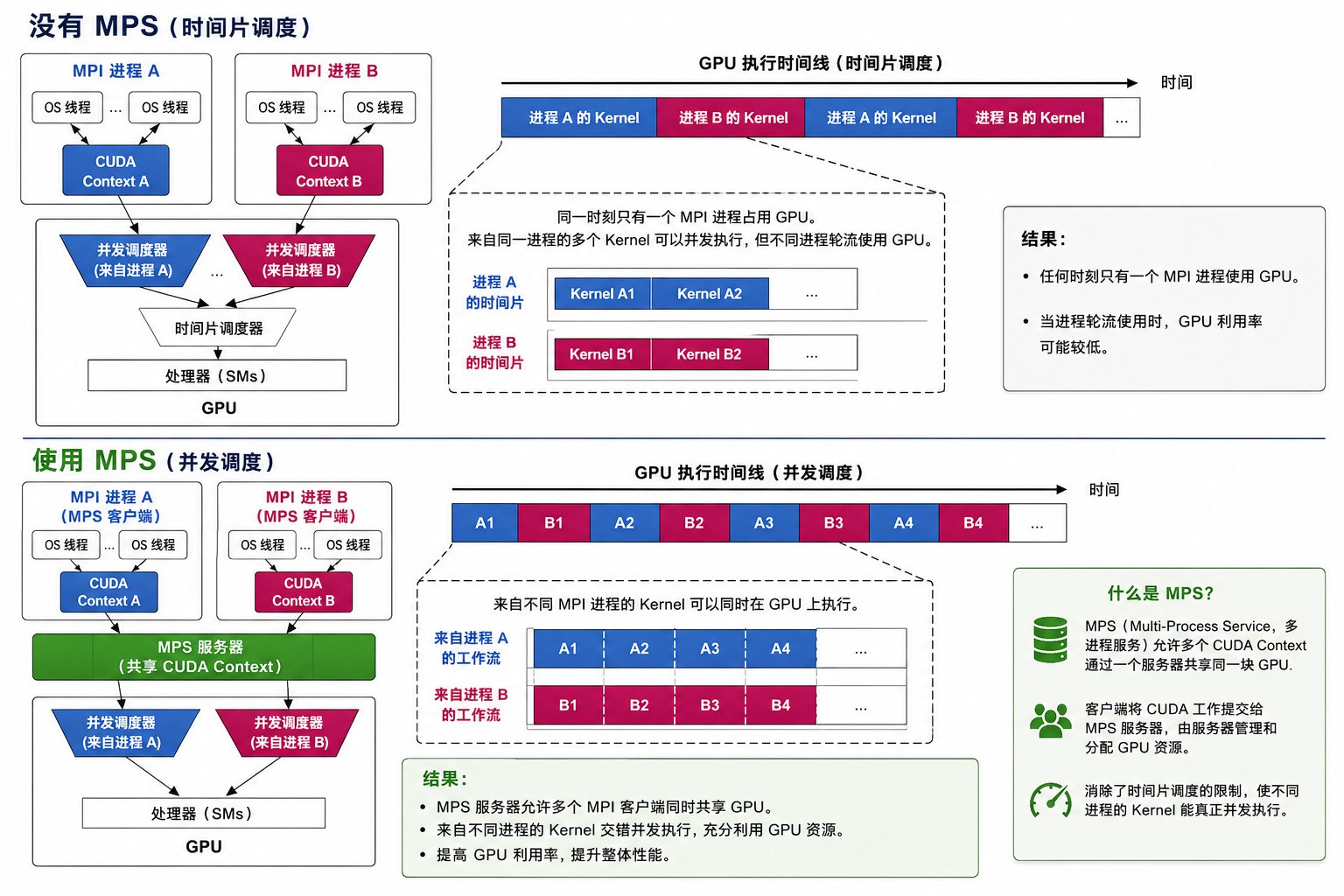
- Control daemon process:control daemon 负责启动和停止 server,并协调 client 与 server 之间的连接。
- Client runtime:MPS client runtime 内置在 CUDA Driver library 中,任何 CUDA 应用都可以透明地使用它。
- Server process:server 是多个 client 共享的 GPU 连接,并负责在 client 之间提供并发执行能力。
MPS 配置示例
MPS 配置示例
- 吞吐提升:两轮实验都使用
4个 worker、N=1024、运行60秒,因此可以用总矩阵乘法次数近似比较吞吐。不开 MPS 时完成394603次,开启 MPS 后完成464780次,对应吞吐约为不开 MPS 的1.18x。 - MPS client:实际运行 CUDA work 的应用进程。这里就是
4个python3worker,它们的SERVER都是3817822,说明它们连接到了同一个 MPS server。 - MPS server:中间代理进程,也就是
nvidia-cuda-mps-server。它代表多个 client 统一持有 GPU context,并把这些 client 的 GPU work 提交给 GPU。
- 确定性的资源分配:可以显式控制每个 client 能访问哪些 SM,不再完全依赖 MPS 的动态调度。
- client 之间的空间隔离:不同 client 可以被放到不同 SM partition,减少彼此干扰。
GPU Operator 中使用 MPS
GPU Operator 中使用 MPS
devicePlugin.config 指定 device plugin 的 ConfigMap;MPS 使用同一个配置入口,但 ConfigMap 里的共享字段是 sharing.mps。NVIDIA device plugin 文档说明,MPS 支持仍是 experimental,并且 MPS 共享当前不支持启用 MIG 的 device。下面示例把每张完整 GPU 切成 4 个 MPS 共享访问入口,并用 renameByDefault: true 暴露为 nvidia.com/gpu.shared:renameByDefault: true 表示共享后的资源会改名暴露。原始资源名是 nvidia.com/gpu,开启后会变成 nvidia.com/gpu.shared;Pod 也需要申请 nvidia.com/gpu.shared。nvidia.com/gpu.shared 即可使用启用 MPS 共享的 GPU:mps-config 这个 ConfigMap,需要手动重启 device plugin DaemonSet 让新配置生效:- NVIDIA MPS Introduction
- NVIDIA MPS Common Tasks
- NVIDIA MPS Tools and Interface Reference
- NVIDIA Kubernetes Device Plugin: With CUDA MPS
2.3 Multi-Instance GPU (MIG)
MIG 会把支持的 GPU 划分为最多 7 个隔离实例,每个实例拥有专用计算和 GPU 内存资源。MIG 从 NVIDIA Ampere 架构开始支持,也就是 compute capability>= 8.0 的部分数据中心 GPU;具体型号以 NVIDIA 的 Supported GPUs 列表为准。
2.3.1 MIG 的资源隔离
MIG 适合多租户场景,不同用户、容器、虚拟机或进程可以运行在不同 GPU 实例上,一个进程不会直接影响另一个进程的调度和资源边界。对云服务和共享集群来说,这种隔离能把一张大 GPU 切成多个可独立分配的小 GPU。 每个 MIG 实例在 GPU 内部访问内存时都有独立路径,包括内部互连、L2 缓存分区、内存控制器和 DRAM 地址总线。这样即使其他实例的任务占满自己的缓存或 DRAM 接口,当前实例仍能获得更稳定的吞吐和延迟。MIG 也可以切分 SM、数据拷贝引擎、解码器等 GPU 引擎,为不同进程提供确定的服务质量(QoS)和故障隔离。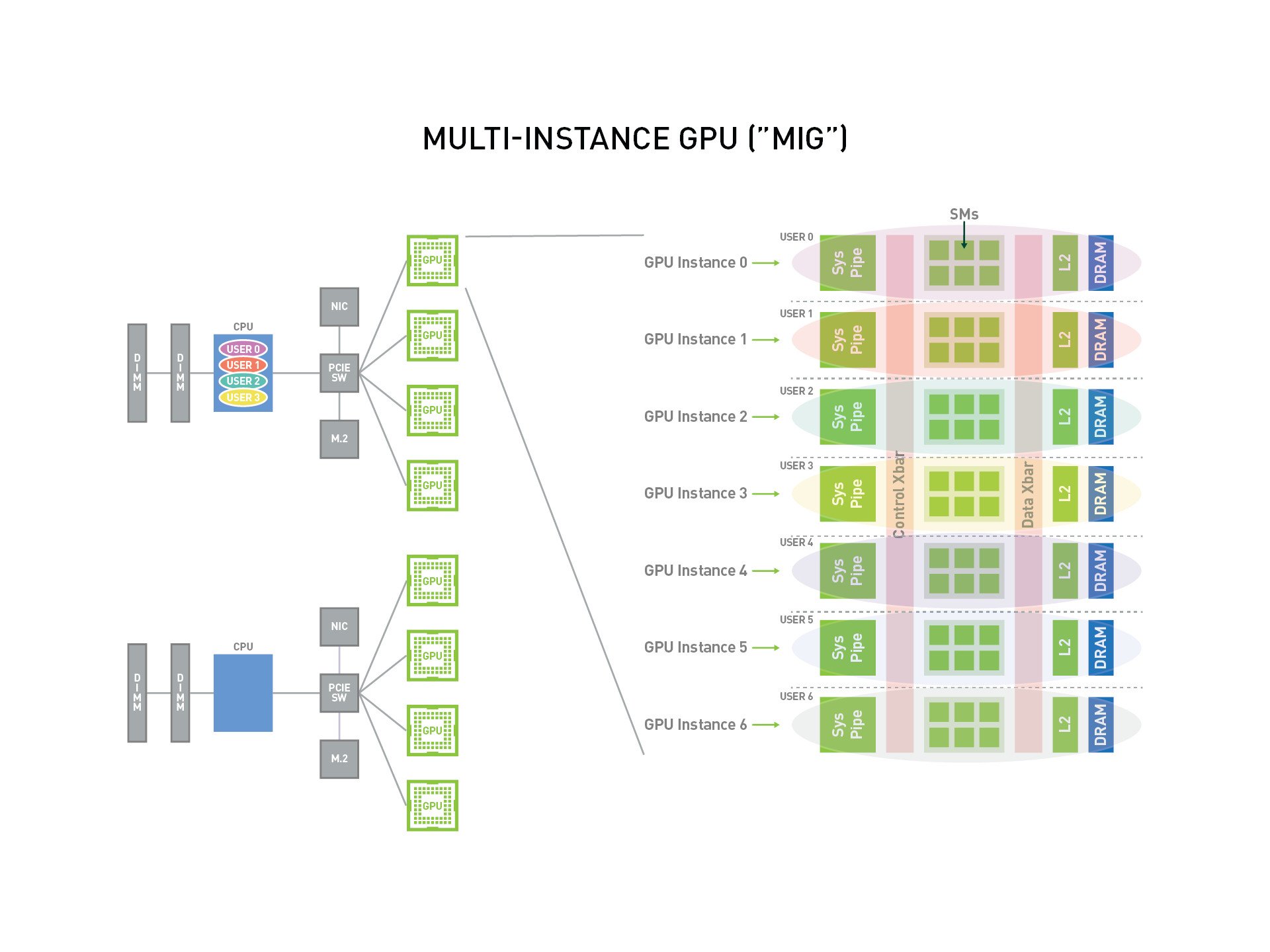
2.3.2 GPU Instance 和 Compute Instance
MIG 配置分两层:先创建 GPU Instance(GI),再创建 Compute Instance(CI)。- GPU Instance(GI):GI 由一组 GPU 切片和 GPU 引擎组成,决定这个 MIG 实例的 GPU 内存容量、带宽和 QoS。
- Compute Instance(CI):CI 是在某个 GI 内继续划分出的计算实例,使用父 GI 的一部分 SM 切片。CI 主要隔离计算资源,也就是 SM;它不提供独立的 GPU 内存隔离。 多个 CI 可以共享同一个 GI 的 GPU 内存切片和 DMA、NVDEC 等引擎,但各自拥有独立的 SM 资源。
-C 参数直接创建覆盖整个 GI 的默认 CI。
2.3.3 MIG 设备命名规则
MIG 设备名称 描述了实例的资源形态。xg.ygb 表示一个 GPU Instance:xg 表示使用 x 份 GPU 计算切片,ygb 表示 GPU 内存容量档位。例如 3g.40gb 表示使用 3 份 GPU 计算切片和 40GB 档位的 GPU 内存。如果一个 GI 继续拆成多个 CI,名称会带上 c,格式为 xc.xg.ygb;例如 1c.3g.40gb 表示在 3g.40gb GI 内使用 1 份计算切片的 CI。
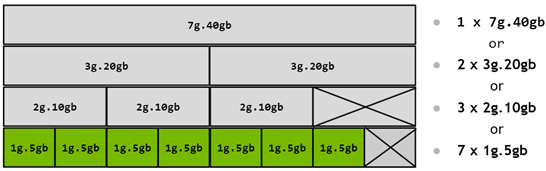
MIG 配置示例
MIG 配置示例
MIG 配置持久化
MIG 配置持久化
mig-parted 重建固定的 MIG 切分形态。下面示例以 A100-SXM4-40GB 为例保存多套候选配置。mig-devices 里的 profile 名称来自 nvidia-smi mig -lgip 输出的 Name 列,例如 MIG 3g.20gb 对应配置里的 "3g.20gb"。mig-configs下面可以保存多套候选配置。每次执行nvidia-mig-parted apply -c <config-name>时,只会应用-c指定的那一套配置all-disabled、all-enabled、2-3g-20gb和all-balanced都是配置名称,后续apply时通过-c引用devices: [0]表示只配置 GPU 0devices: all表示配置节点上的所有 GPUmig-enabled: true表示启用 MIG modemig-devices表示要创建的 GPU Instance profile 和数量,例如"3g.20gb": 2表示创建两个3g.20gb
MIG 与 MPS 结合使用
MIG 与 MPS 结合使用
- 配置目标 MIG 切分形态,例如两个
3g.40gbMIG device - 为每个 MIG device 设置独立的
CUDA_MPS_PIPE_DIRECTORY,并启动一个独立的 MPS control daemon - 启动 CUDA 程序时,用
CUDA_VISIBLE_DEVICES=<MIG_UUID>指定目标 MIG device
EXCLUSIVE_PROCESS,确保一张 GPU 只有一个 MPS server。MIG mode 下不使用这个模式,因为每个 MIG GPU Instance 需要独立的 MPS server。nvidia-smi 看到每个 MIG device 上各有一个 MPS server,以及对应的 CUDA client:在 GPU Operator 中使用 MIG
在 GPU Operator 中使用 MIG
single 和 mixed:single适合节点上使用同一种 MIG profile 的场景,MIG device 通常继续通过nvidia.com/gpu这类资源暴露mixed适合同一节点上混合使用多种 MIG profile 的场景,资源会按 profile 暴露,例如nvidia.com/mig-1g.5gb
mig-parted 配置文件。默认配置来源由 migManager.config 指定:name: default-mig-parted-config表示 MIG Manager 读取这个 ConfigMap 里的config.yamldefault: all-disabled表示默认使用mig-configs里的all-disabled这套配置- 节点上的
nvidia.com/mig.config=<config-name>label 会从这个 ConfigMap 里选择一套配置并应用
nvidia.com/mig.config label,MIG Manager 会监听到 node label 变化,然后调用 mig-parted 应用目标配置。2.4 GPU 时钟频率与 ECC
NVIDIA GPU 的 GPU Boost 会在功耗和温度限制内自动调整核心频率。大多数时候,让 GPU 按默认策略动态调频即可。 需要确定性、可重复的结果时,比如做 benchmark,可以把核心频率锁到固定档位。日常训练和推理建议保持 auto-boost 开启;只有观察到明显的性能波动或 GPU throttling 时,再考虑锁频排查。 锁频前先查看 GPU 支持的频率档位。这里关注Graphics,它对应核心频率:
SUPPORTED_CLOCKS 里列出的值。
3. 系统调优脚本
system_tuning.sh 脚本里包含 CPU 频率策略、swap、透明大页(THP)、网络参数、中断亲和性等调优项。
system_tuning.sh 示例
system_tuning.sh 示例
4. 容器运行时优化
AI 系统常用 Docker、Kubernetes 等容器运行时和编排工具来管理软件环境。容器能把 CUDA、Python package、系统库和推理/训练框架版本固定下来,减少“在我机器上能跑”的环境漂移问题。 容器会引入一点复杂度和少量开销,但配置正确时,GPU workload 可以接近裸机性能。容器不是传统虚拟机(VM)。和 VM 不同,容器共享宿主 OS kernel,CPU 和内存操作通常接近原生速度,没有额外的 hypervisor 虚拟化层。 配合 NVIDIA Container Toolkit,Docker 容器内的 GPU 访问是直接的,不会引入传统虚拟化开销。对于现代 GPU 和较新的 NVIDIA Container Toolkit,只要环境配置正确,容器内运行和直接在裸机宿主上运行的 GPU 性能通常几乎一致,差异通常可以控制在 2% 以内。4.1 NVIDIA Container Toolkit
NVIDIA Container Toolkit 允许用户构建和运行 GPU 加速容器。它包含 container runtime library 和相关工具,可以自动配置容器,让容器使用 NVIDIA GPU。 NVIDIA Container Toolkit 的组件可以分到两条路径里:传统的 OCIprestart hook 路径,以及标准化的 CDI 路径。
Legacy OCI 路径
- NVIDIA Container Runtime(
nvidia-container-runtime):OCI runtime wrapper。legacy mode 下,它会修改容器启动时传入的 OCI runtime spec,插入 NVIDIAprestarthook,再调用底层容器运行时(runc/crun)。 - NVIDIA Container Runtime Hook(
nvidia-container-runtime-hook):OCIprestarthook。在容器创建后、启动前读取config.json,把 GPU device、driver capabilities 和约束转换成nvidia-container-cli参数。 - NVIDIA Container CLI(
nvidia-container-cli):libnvidia-container提供的命令行入口。runtime hook 会调用它完成 GPU device、driver libraries 和权限配置。 - NVIDIA Container Library(
libnvidia-container1):底层库,依赖 Linux kernel primitives,提供自动配置 GNU/Linux 容器以使用 NVIDIA GPU 的能力。
- NVIDIA CDI Hooks(
nvidia-cdi-hook):CDI spec 中可调用的辅助工具,用于调整权限、创建 symlink、更新动态链接器缓存等额外操作。
- NVIDIA Container Toolkit CLI(
nvidia-ctk):通用配置与管理工具。legacy 路径下用nvidia-ctk runtime configure把 NVIDIA runtime 写入 Docker / containerd / CRI-O 配置;CDI 路径下用nvidia-ctk cdi generate生成 CDI spec。
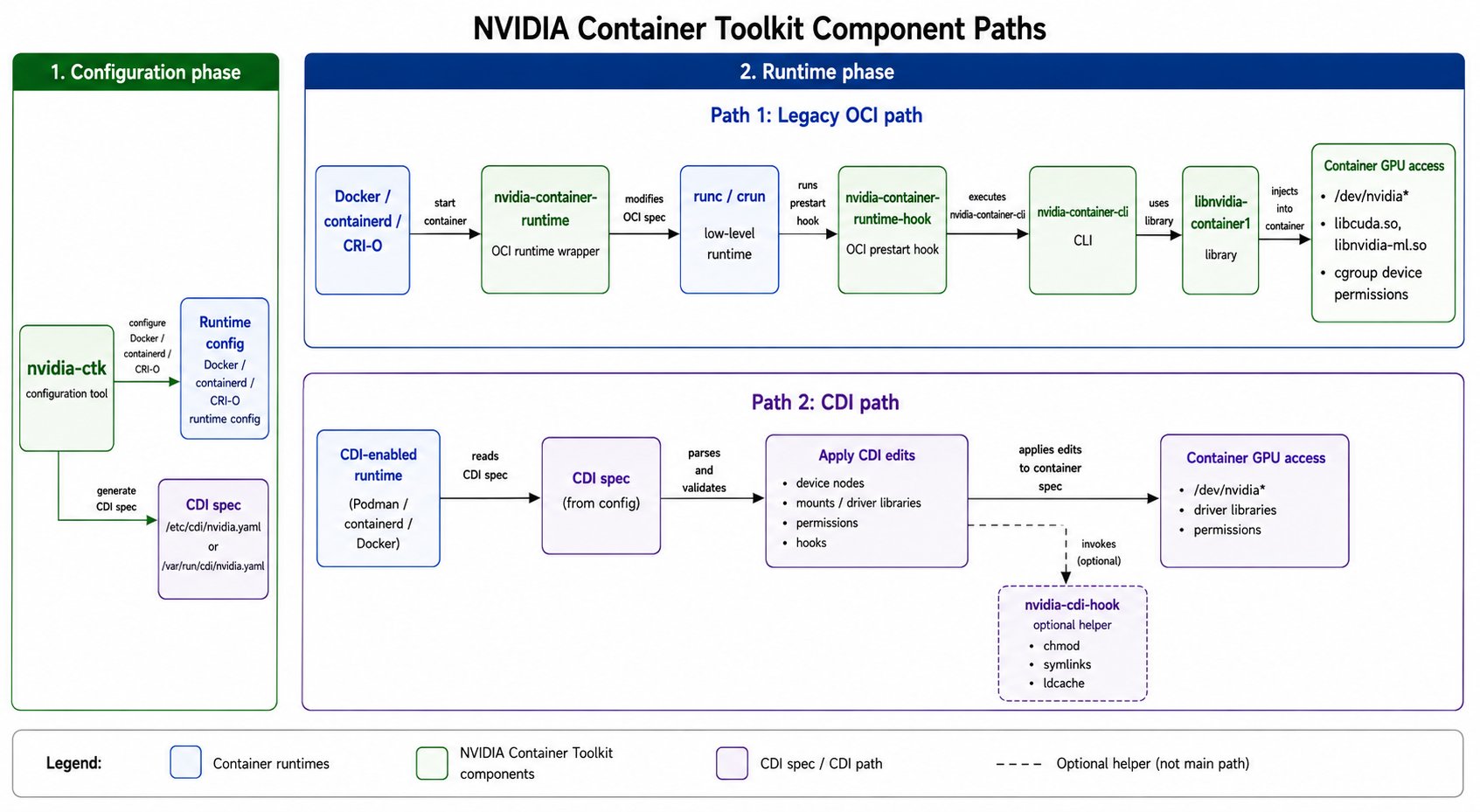
OCI 与 CDI
OCI 与 CDI
rootfs、mounts、env、devices、hooks、namespaces、cgroups 等运行时配置。runc / crun 这类底层运行时会按这个 spec 创建容器。CDI(Container Device Interface) 是设备注入规范。CDI spec 里的 containerEdits 字段描述需要对 OCI spec 做哪些修改,例如 deviceNodes、mounts、env、hooks、permissions 等。支持 CDI 的 runtime 会读取 CDI spec,并把这些 edits 应用到 OCI runtime spec。两者的关系是:OCI 描述容器整体如何启动,CDI 描述设备如何注入容器。支持 CDI 的 runtime 会把 CDI spec 里的设备配置应用到 OCI runtime spec,最后仍由 runc / crun 按 OCI spec 创建容器。NVIDIA Container Runtime 注入了什么
NVIDIA Container Runtime 注入了什么
nvidia.ko)加载后,会在宿主机 /dev/ 下创建一组字符设备:/dev/nvidia0 这类设备文件,并通过 ioctl() 系统调用进入宿主机 kernel driver,由 kernel driver 负责和 GPU 硬件交互。一个裸容器(bare container)本身没有 GPU 访问能力。它的 /dev/ 目录里只有标准设备,比如 null、zero、pts。NVIDIA Container Runtime(nvidia-container-runtime)会在应用启动前向容器注入三类内容:- Device nodes:从宿主机 bind mount
/dev/nvidia0(具体 GPU 设备文件)、/dev/nvidiactl(NVIDIA driver 控制设备)、/dev/nvidia-uvm(Unified Virtual Memory)。 - Driver libraries:bind mount
libcuda.so(CUDA Driver API)、libnvidia-ml.so(NVML,用于nvidia-smi、DCGM 和监控工具查询 GPU 状态)和其他与宿主机 driver 匹配的库。 - Device permissions:配置 cgroup device controller,允许容器访问 NVIDIA 主设备号(device major number)。主设备号是 Linux 用来把设备文件路由到对应内核驱动的编号。
容器到宿主机 GPU 的调用路径
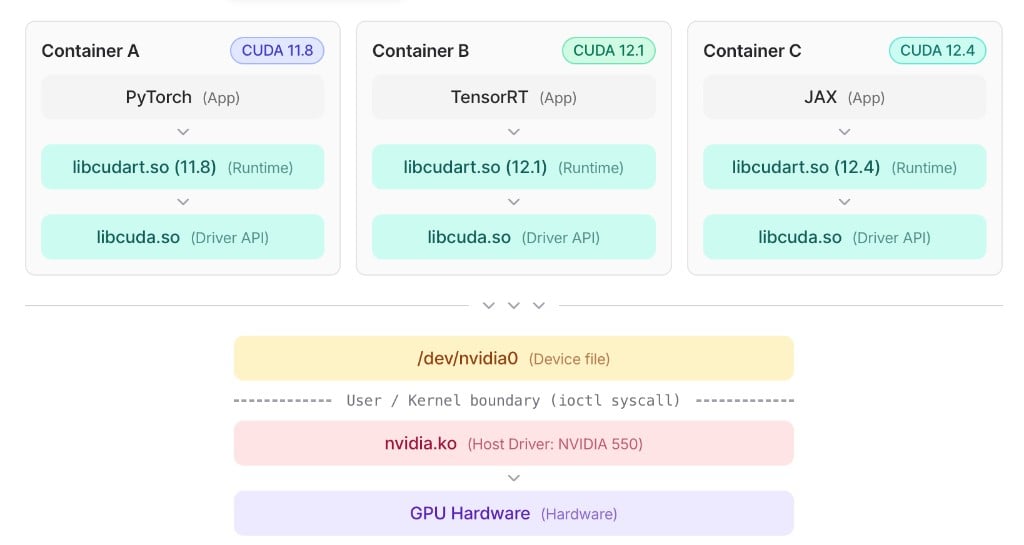
容器到宿主机 GPU 的调用路径
- 应用层:
PyTorch、TensorRT、JAX等框架运行在各自容器里。它们会调用容器内的 CUDA 用户态库(libcudart.so),也可能直接使用 CUDA Driver API(libcuda.so)。 - CUDA 用户态库:
libcudart.so、cuBLAS、cuDNN、NCCL 等通常来自容器镜像。不同容器可以携带不同 CUDA 版本,例如 CUDA 11.8、12.1、12.4。 - CUDA Driver API:
libcuda.so是 driver API 库,通常由宿主机 driver bind mount 进容器。容器内的 CUDA 用户态库和框架代码最终通过它进入宿主机 driver 路径。 - 设备文件:
/dev/nvidia0是 GPU 设备文件,也由宿主机挂进容器。libcuda.so通过它发起ioctl()系统调用,跨过 user / kernel 边界。 - Kernel driver:
nvidia.ko运行在宿主机 kernel 中,负责处理ioctl()请求并和 GPU 硬件通信。所有容器共享同一个宿主机 kernel driver。 - GPU hardware:真正执行计算的物理 GPU。
安装与配置 NVIDIA Container Toolkit
安装与配置 NVIDIA Container Toolkit
nvidia-ctk 命令配置 runtime:nvidia-ctk 命令会修改宿主机上的 /etc/docker/daemon.json 文件,把 nvidia runtime 注册进去,让 Docker 可以使用 NVIDIA Container Runtime,配置类似:使用 CDI 路径
使用 CDI 路径
--device 按名字请求 GPU,不需要 --gpus 或 --runtime=nvidia。1. 生成 CDI spec(扫描本机 GPU / MIG 设备并写出 spec;/etc/cdi 为静态目录、/var/run/cdi 为临时目录):nvidia.com/gpu=all(全部)、nvidia.com/gpu=gpu0(按索引)、nvidia.com/gpu=mig<GPU>:<MIG>(MIG 实例)。用 nvidia-ctk cdi list 查看:nvidia-cdi-refresh systemd 服务会在安装、driver 升级、重启时自动重新生成 spec;但驱动卸载或 MIG 重新配置后需要手动重新生成。2. 运行容器,用 --device 指定 CDI 设备名:nvidia-container-runtime-hook → nvidia-container-cli 这条启动时注入链——设备节点、驱动库、权限都由 CDI spec 声明,再由支持 CDI 的 runtime 直接应用到容器。CUDA 版本与 NVIDIA driver 兼容性
CUDA 版本与 NVIDIA driver 兼容性
- CUDA 13.x 需要 Linux 宿主机 NVIDIA driver R580 驱动分支或更新。
- CUDA 12.x 需要 Linux 宿主机 NVIDIA driver R525 驱动分支或更新。
- CUDA 11.x 需要 Linux 宿主机 NVIDIA driver R450 驱动分支或更新。
nvidia.ko)不变的情况下,通过安装 CUDA Forward Compatibility Package,补上较新的 user-mode driver libraries,例如 libcuda.so,让较新的 CUDA 应用在满足条件的旧 driver 环境上运行。正常升级 NVIDIA driver 会同时更新 user-mode libraries 和 kernel-mode driver。Forward Compatibility Package 只补 user-mode 组件,不替换 nvidia.ko。如果新功能依赖新的 kernel driver 能力,仍然需要升级宿主机 driver。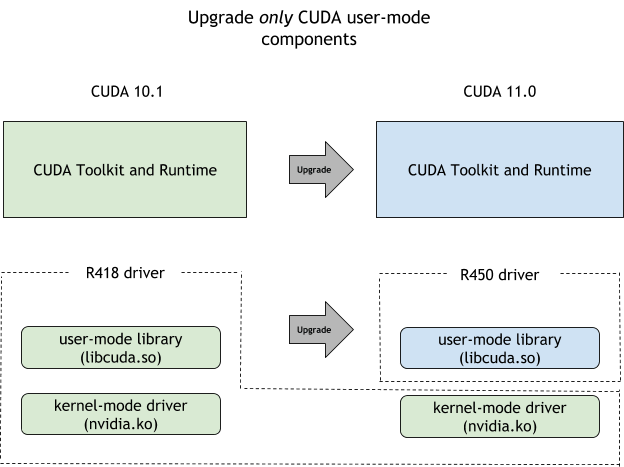
4.2 避免 Overlay FS 开销
和直接在宿主机运行相比,Docker 容器更容易出现差异的地方通常是 I/O。容器常用联合文件系统(union filesystem),它的好处很直接:把只读镜像层和可写容器层透明叠加成一个统一视图,容器看起来像在使用一个完整的文件系统。 OverlayFS 在读写文件时会带来额外开销:- 读取文件时:文件系统需要检查只读层和可写层,判断应该返回哪个版本的文件。额外的 metadata lookup 和层合并逻辑,会比单一文件系统多一点延迟。
- 修改文件时:如果修改的是只读层里的文件,会触发 copy-on-write。文件必须先复制到可写层,写入发生在这份副本上,而不是原始只读文件上。
OverlayFS 与 Copy-on-Write(COW)
OverlayFS 与 Copy-on-Write(COW)
upper directory 可读可写,lower directory 只读。upper directory 一开始通常是空的,只保存挂载之后新增或修改过的文件。OverlayFS 会把它们组合成一个 merged directory,让进程看起来像是在访问一个完整的文件系统。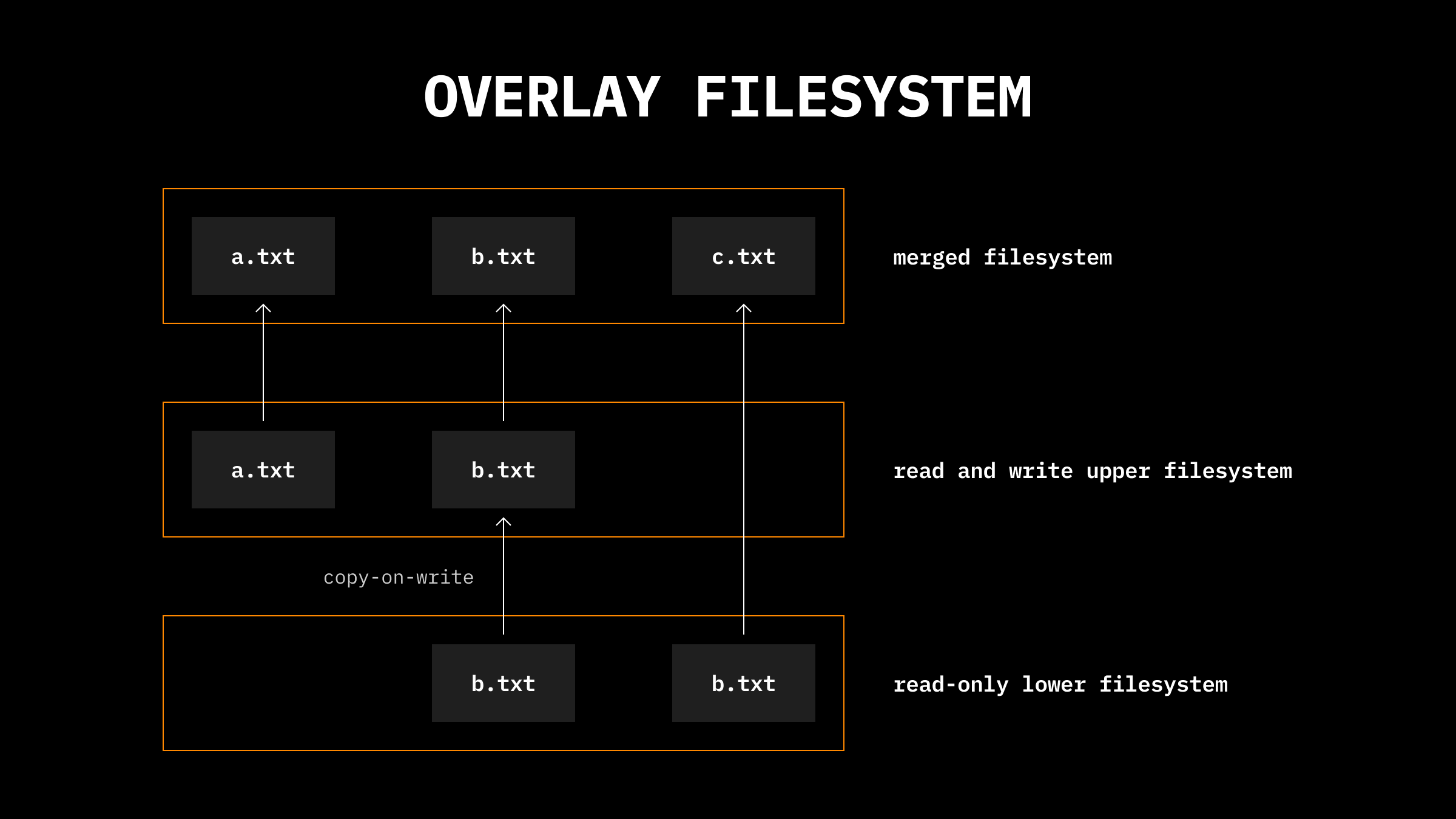
lower directory,容器自己的 writable layer 对应 upper directory。这样启动容器时不需要复制整份镜像,只需要引用底层只读文件。当你想写入或修改来自 lower directory 的文件时,OverlayFS 会使用一种叫写时复制(copy-on-write,COW) 的技术。它不会修改原始文件,而是在 upper directory 中创建该文件的一份副本,并把修改应用到这份副本上。因此,如果修改来自 lower directory 的 b.txt,OverlayFS 会在 upper directory 中创建一份 b.txt 副本,后续修改都发生在这份副本上,原始的 lower 文件保持不变。这样既能保证基础系统的完整性,也能减少需要复制的数据量。参考资料:Scaling Firecracker: Using OverlayFS to Save Disk Space/data/dataset。-v /data/dataset:/mnt/dataset:ro 会把它挂载到容器内的 /mnt/dataset,其中 ro 表示只读挂载。训练脚本从 /mnt/dataset 读取数据,相当于直接从宿主文件系统读取。
4.3 HPC 场景的容器运行时
HPC 集群对容器运行时提出了更高要求。集群通常遵循最小权限原则:用户应以自身身份运行作业,不能提升权限,也不应接触计算节点上由 root 管理的系统守护进程。同时,HPC 容器运行时还需要更便捷地接入 GPU、高速网络和并行文件系统等宿主资源。因此,在 HPC 场景中,有时候会选择 Apptainer 或 Enroot 这类面向 HPC 集群环境设计的容器运行时。 Apptainer 最初是为了在 HPC 集群上以简单、可移植、可复现的方式运行复杂应用而创建的。它最早由劳伦斯伯克利国家实验室(Lawrence Berkeley National Laboratory)开发,很快在其他 HPC 中心、学术机构和更多场景中流行起来。 Apptainer 的设计更贴近 HPC 集群的使用方式:- 可验证的复现性和安全性:支持加密签名、不可变容器镜像格式和内存中解密。
- 默认强调集成而不是隔离:更容易使用集群上的 GPU、高速网络和并行文件系统。
- 计算环境可移动:SIF 单文件镜像便于传输、共享和归档。
- 简单的安全模型:容器内外默认是同一个用户,默认不能因为进入容器而获得宿主机额外权限。
Apptainer GPU 容器使用
Apptainer GPU 容器使用
--nv。这个选项会让容器看到宿主机的 NVIDIA device entries,并把基础 CUDA/NVIDIA driver libraries 绑定进容器。apptainer instance list 查看,用 instance://<name> 进入或执行命令:APPTAINERENV_CUDA_VISIBLE_DEVICES。Apptainer 会把它映射成容器内的 CUDA_VISIBLE_DEVICES,影响遵循该变量的 CUDA 程序:APPTAINERENV_CUDA_VISIBLE_DEVICES 限制的是 CUDA 程序使用哪些 GPU,不一定限制 nvidia-smi 能枚举到的设备。Apptainer 也提供实验性的 --nvccli,通过 NVIDIA 的 nvidia-container-cli 完成 GPU 容器配置。它需要宿主机安装 nvidia-container-cli,并且通常要配合 --writable-tmpfs 或 writable sandbox 使用;在 setuid 安装模式下也有额外安全限制。在 --nvccli 模式下,如果需要更强的设备隔离,可以配合 --contain 和 NVIDIA_VISIBLE_DEVICES 控制实际绑定进容器的 GPU:- 遵循 KISS 原则和 Unix philosophy。
- 独立运行,不需要 daemon。
- 支持完全非特权和多用户使用:不需要 setuid binary,继承 cgroup,并使用每用户配置和容器存储。
- 使用简单:镜像格式简单,便于脚本化,也支持 root remapping。
- 几乎不做额外隔离:减少性能开销,也简化 HPC 部署。
- 可组合、可扩展:支持系统级和用户级配置。
- Docker 镜像导入速度快,官方 README 中提到大镜像导入可获得 3x 到 5x 加速。
- 内置基于
libnvidia-container的 GPU 支持。 - 支持 bundles、in-memory containers 等协作和开发工作流。
Enroot GPU 容器使用
Enroot GPU 容器使用
NVIDIA_VISIBLE_DEVICES 和 ENROOT_RESTRICT_DEV 两个环境变量:5. Kubernetes 编排与调度
GPU 是集群里最贵、最稀缺的资源,调度方式直接影响利用率与训练/推理成本。5.1 GPU Operator
在 Kubernetes 集群中管理 GPU 可能是一项艰巨的任务。传统方法往往需要手工安装和配置 GPU 驱动,既费时又容易出错。此外,要利用高级 GPU 特性、并确保 GPU 与其它系统组件之间的高效数据传输,还需要专门的知识和工具。缺少一套规范化的方法,这些挑战会拖累 AI/ML 工作负载的性能与可扩展性。 NVIDIA GPU Operator 提供了多种特性。它让在 Kubernetes 上设置 GPU 驱动及其配置变得轻而易举。在同一批节点上运行多个 AI 工作负载时,能够使用 vGPU、Multi-Instance GPU(MIG)、GPU Time-Slicing 等高级特性至关重要。此外,GPU 还需要与其它应用/GPU 以及存储之间具备快速通信能力,GPUDirect RDMA、GPUDirect Storage 和 GDR Copy 在其中扮演重要角色。GPU Operator 能帮助你轻松地把这些特性以及更多能力带到 Kubernetes 集群中。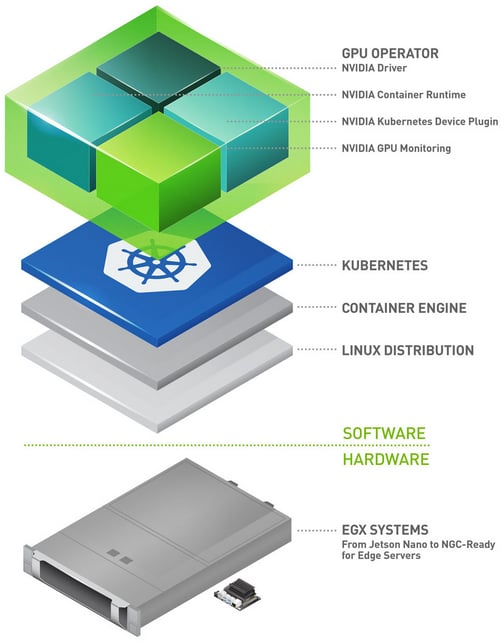
- 自动安装和维护 GPU driver:NVIDIA GPU Operator 自动安装和维护 GPU driver,消除手动干预的需要。自动化可以确保 driver 始终保持最新并正确配置,让 AI/ML workload 平稳、高效地运行。
- 配置高级 GPU 特性:
- vGPU(Virtual GPU) 允许多个虚拟机共享单张 GPU,提升资源利用率和灵活性。
- MIG(Multi-Instance GPU) 允许单张 GPU 被划分成多个彼此独立的实例,每个实例拥有专用资源,从而改善 workload 隔离和效率。
- GPU Time-Slicing 在多个任务之间切分 GPU 时间,保证 GPU 资源在不同 workload 之间公平、高效地分配。
- 配置 GPUDirect RDMA 和 GPUDirect Storage:
- GPUDirect RDMA(Remote Direct Memory Access) 支持不同节点上的 GPU 直接通信,绕过 CPU 并降低延迟,这对高性能计算应用非常重要。
- GPUDirect Storage 支持 GPU 与存储设备之间直接传输数据,显著加速数据密集型应用的数据访问和处理。
- 配置 GDR Copy:GPUDirect RDMA(GDR)Copy 是一个基于 GPUDirect RDMA 技术的低延迟 GPU memory copy library,允许 CPU 直接 map 和访问 GPU memory。它可以提升 memory copy 操作的效率,降低开销,并改善整体性能。
- NVIDIA GPU Operator 官方文档
- Installing the NVIDIA GPU Operator
- InfraCloud:A Guide to NVIDIA GPU Operator in Kubernetes
- NVIDIA Blog:Simplifying GPU Management in Kubernetes
- Time-Slicing GPUs in Kubernetes(GPU Operator)
- GPU Operator with MIG
5.2 Device Plugin
GPU Operator 部署的组件里,真正把 GPU 暴露给 Kubernetes 调度的是 device plugin。NVIDIA 的 k8s-device-plugin 以 DaemonSet 运行,向 kubelet 注册扩展资源nvidia.com/gpu。启用 MIG 时,device plugin 可以按 profile 暴露 nvidia.com/mig-* 资源;启用 GPU sharing 时,则可以把共享后的访问入口暴露为 nvidia.com/gpu.shared 等资源。
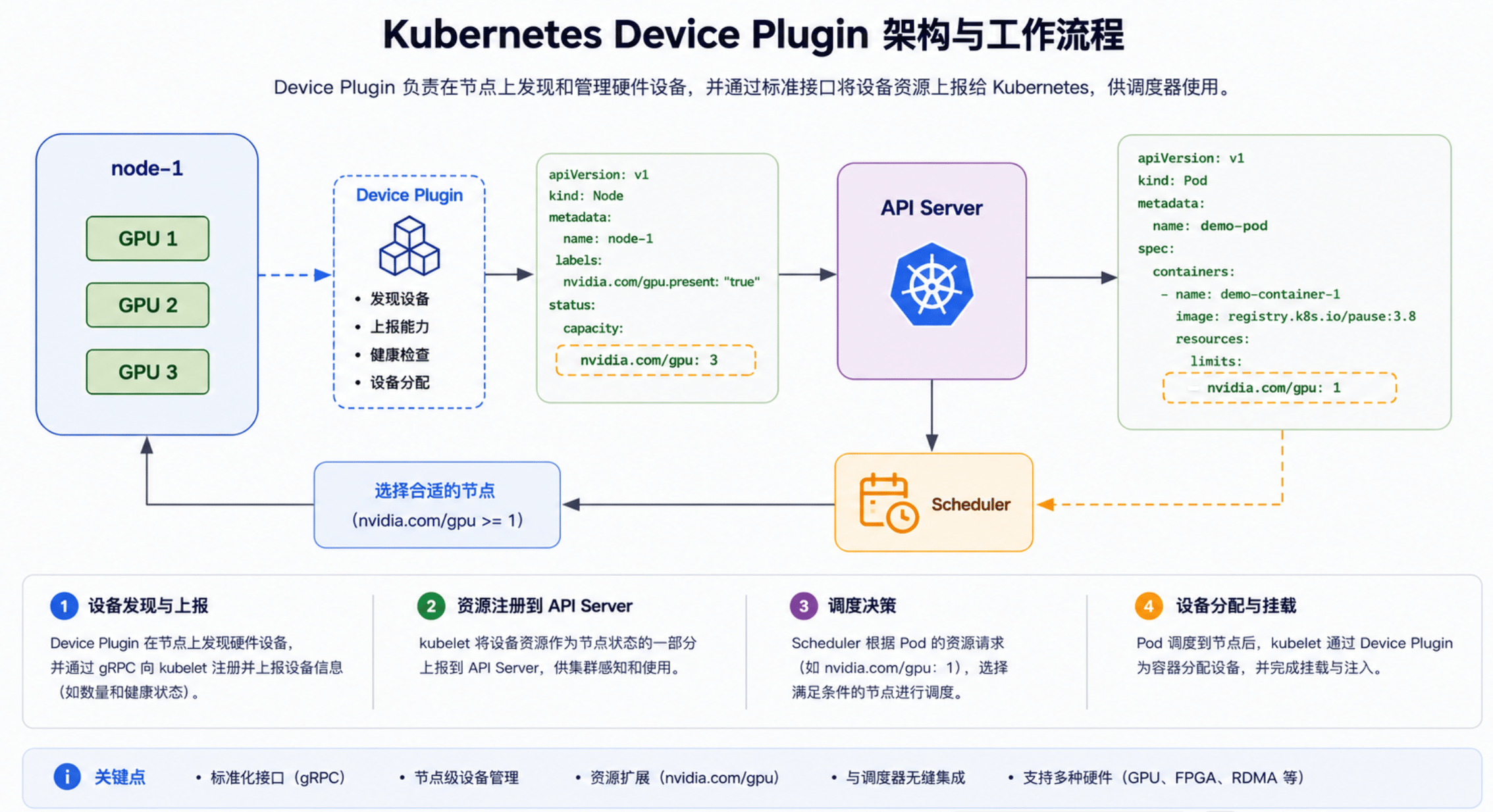
- 仅支持整数计数:资源以不透明整数暴露,无法按显存容量、架构、compute capability 等属性筛选设备。
- 共享只能节点级配置:默认整卡独占;time-slicing / MPS 共享只能按节点 ConfigMap 统一开启(time-slicing 无显存/故障隔离),无法在单个请求中按工作负载表达。
- 缺乏属性级调度:调度器只感知数量,无法指定具体设备,需借助节点 label 与
nodeSelector间接约束放置。 - MIG 布局静态:MIG profile 须在节点侧预先配置,调整布局需重新配置节点,无法按工作负载动态切分。
- 拓扑感知不足:对 NVLink、NUMA 等拓扑距离缺乏感知。
5.3 Dynamic Resource Allocation (DRA)
DRA 是 Kubernetes 的一项功能,用于在 Pod 之间请求和共享资源。这些资源通常是硬件加速器这类附加设备。 DRA 提供了一种灵活的方式,用于对集群中的设备进行分类、请求和使用。使用 DRA 可以带来如下收益:- 灵活的设备过滤:使用 Common Expression Language(CEL)对特定设备属性进行细粒度过滤。
- 设备共享:通过引用对应的
ResourceClaim,让多个容器或 Pod 共享同一个资源。 - 集中式设备分类:设备驱动和集群管理员可以使用
DeviceClass,为应用提供针对不同使用场景优化过的硬件类别。例如,可以为通用 workload 创建成本优化型DeviceClass,为关键任务创建高性能DeviceClass。 - 简化 Pod 请求:使用 DRA 时,应用不需要在 Pod resource request 中指定设备数量。Pod 会引用一个
ResourceClaim,该ResourceClaim中的设备配置会应用到 Pod。
从 CSI 看 DRA:同一套声明式设计
从 CSI 看 DRA:同一套声明式设计
- CSI(存储):
PersistentVolume代表可用存储 →StorageClass分类 →PersistentVolumeClaim申请。 - DRA(设备):
ResourceSlice代表可用设备 →DeviceClass分类 →ResourceClaim申请。
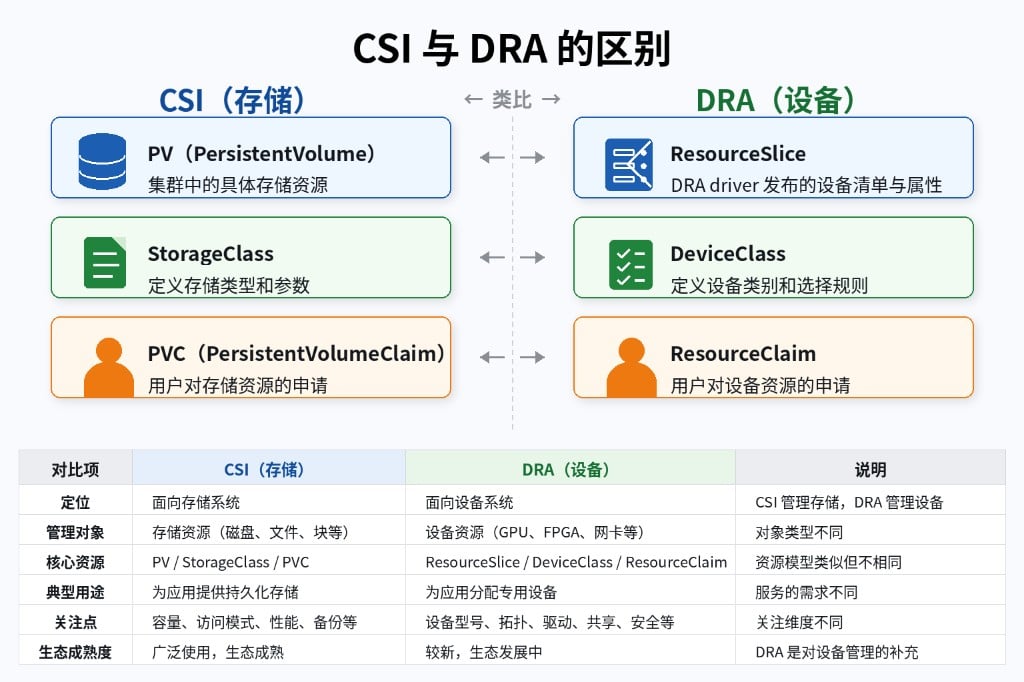
严格说DRA 三者按数据流方向串起来:ResourceSlice和PV不能完全等同:PV是一块具体的存储卷,ResourceSlice更像节点上设备的目录清单。但从供需关系看,模式是一样的。
ResourceSlice(供给):DRA driver 发布节点上的设备信息,包括型号、显存、驱动版本等属性,以及可用容量。DeviceClass(分类):管理员用 CEL 表达式从设备属性里筛出一类设备,形成用户友好的分组,比如「所有 NVIDIA GPU」或「仅 A100」。ResourceClaim(需求):用户通过deviceClassName引用某个DeviceClass,声明需要几个该类设备。- 调度器(决策):综合
ResourceSlice的库存和ResourceClaim的需求,选出满足条件的节点和具体设备,完成分配。
完整流程:一个 Pod 如何用上 DRA 资源
完整流程:一个 Pod 如何用上 DRA 资源
ResourceSlice、DeviceClass、ResourceClaim 与 Pod 之间的配合,看一次分配从设备注册到容器启动经历哪些阶段。阶段一:设备注册(DRA Driver → ResourceSlice)ResourceSlice 并递增 pool.generation。一份真实的 ResourceSlice(A100 节点,保留一个 MIG 实例和一张整卡的完整字段,其余设备省略):DeviceClass 是管理员对 ResourceSlice 中设备的分类标准。driver 把原始设备信息发布到集群后,管理员用 DeviceClass 告诉用户「有哪些设备类别可用」:deviceClassName: gpu.nvidia.com 代表「NVIDIA GPU」——跟 CSI 里选 StorageClass 一个道理:管理员写规则,用户选 class。阶段三:声明需求(用户 → ResourceClaim / ResourceClaimTemplate)用户基于 DeviceClass 声明要什么设备、要多少。有两种写法:直接建一个 ResourceClaim,或用 ResourceClaimTemplate 让 K8s 为每个 Pod 自动生成 claim。直接建 ResourceClaim:ResourceClaimTemplate(同样的 devices 申请,只是被多包了一层 spec):allocationMode 除 ExactCount 外还支持 All:不指定数量,直接占用该节点该 class 下的全部设备,适合需要独占整机 GPU 的分布式训练。阶段四:创建 Pod 并触发调度Pod 在 resourceClaims 里引用上面声明的资源,容器再通过 resources.claims 使用它。引用直接建的 claim 用 resourceClaimName,引用模板则用 resourceClaimTemplateName:Filter 阶段为候选节点计算设备分配结果,Reserve 阶段在调度器内部缓存 pending allocation,PreBind 阶段通过 bindClaim 把 ResourceClaim.status.allocation 和 ResourceClaim.status.reservedFor 写回 API Server;之后 driver 和 kubelet 都以这份结果为准。三个组件分工如下:5.3.1 GPU 分配基本示例
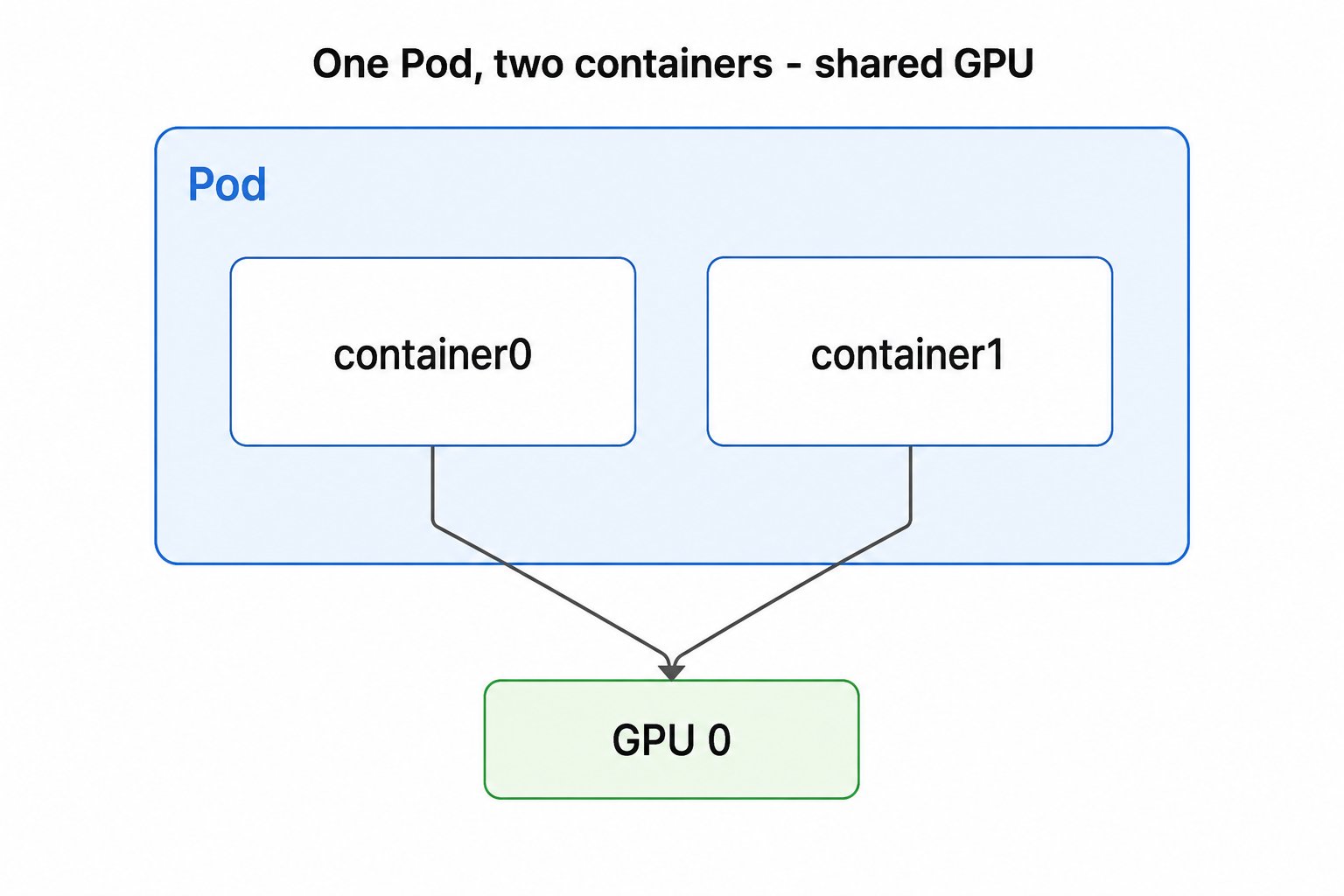
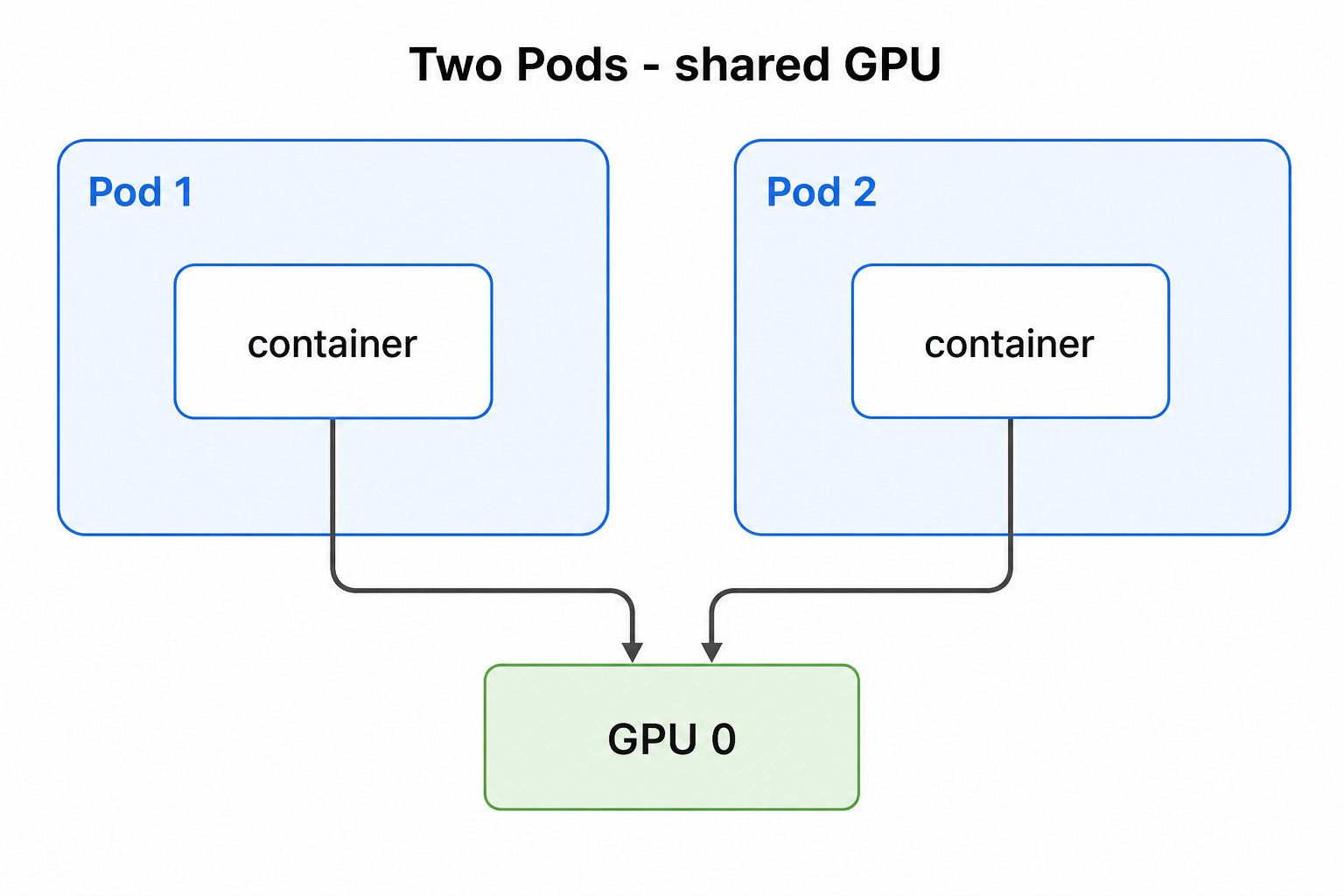
最基础的用法是申请整卡:ResourceClaimTemplate 或 ResourceClaim 通过 deviceClassName 引用 gpu.nvidia.com 这个 DeviceClass,Pod 再引用该 claim 即可拿到一张 GPU。
ResourceClaimTemplate会为每个 Pod 各生成一个独立 claim、拿到不同 GPU;- 共享的
ResourceClaim(Pod 以resourceClaimName引用)则可以让多个 Pod 共享同一张卡。
ResourceClaimTemplate 生成独立 claim,分到不同 GPU。
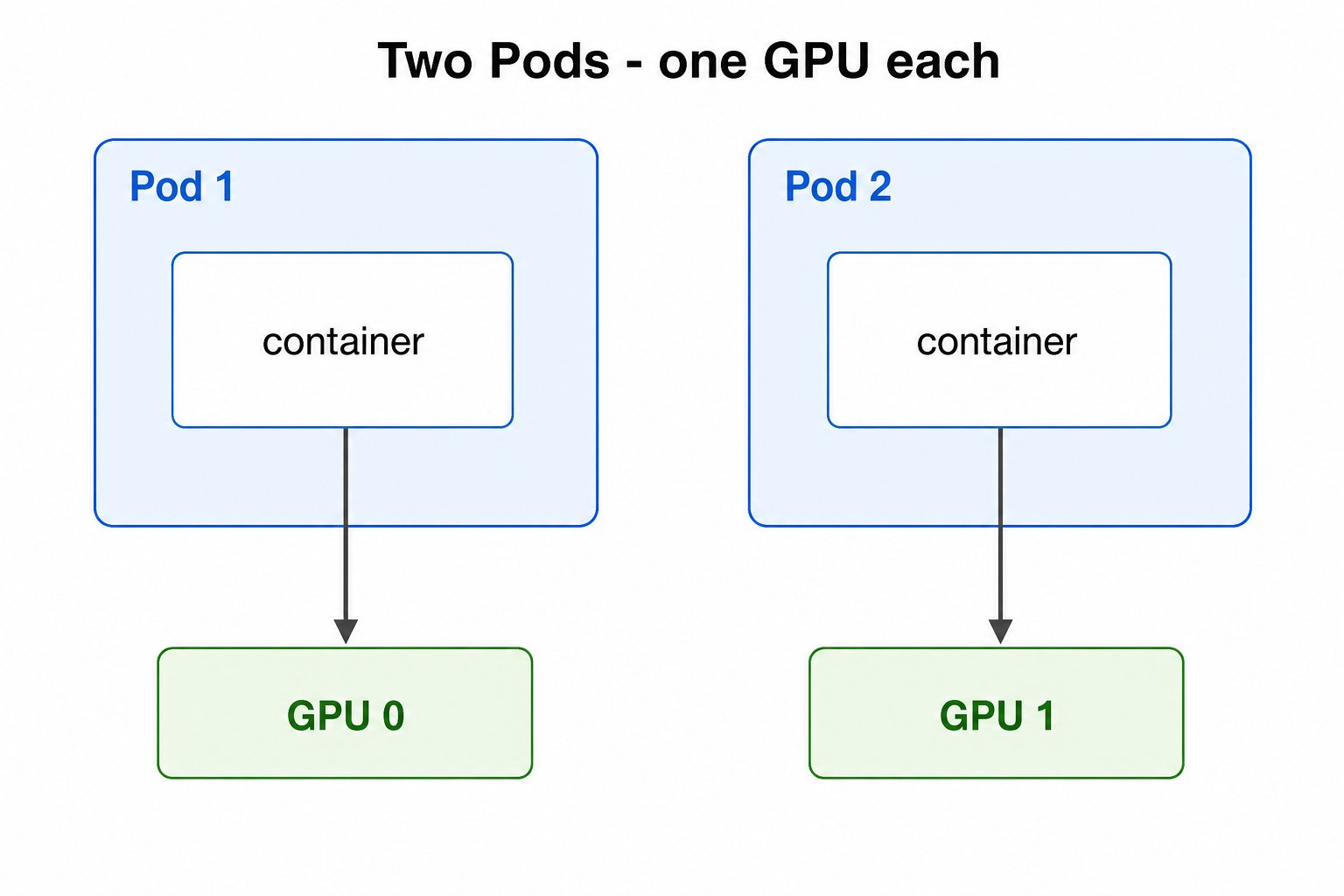
完整 YAML:quickstart/two-pods-one-gpu-each.yaml
完整 YAML:quickstart/two-pods-one-gpu-each.yaml
ResourceClaim(resourceClaimName),落到同一张 GPU。
5.3.2 TimeSlicing 与 MPS
DRA 把共享策略直接写进每个 claim 的GpuConfig,因此能按工作负载单独配置;而 device plugin 的 TimeSlicing / MPS 由整节点共用一份 ConfigMap 决定,同一节点上所有 Pod 只能套用同一套。DRA 的粒度还能更细——同一个 ResourceClaimTemplate 里就能给不同 request 配不同策略:一个 request 走 TimeSlicing、另一个走 MPS,各自落到不同的 GPU。下面这个示例用一个 Pod、4 个容器演示:ts-ctr0/ts-ctr1 共享一张走 TimeSlicing 的 GPU,mps-ctr0/mps-ctr1 共享另一张走 MPS 的 GPU。
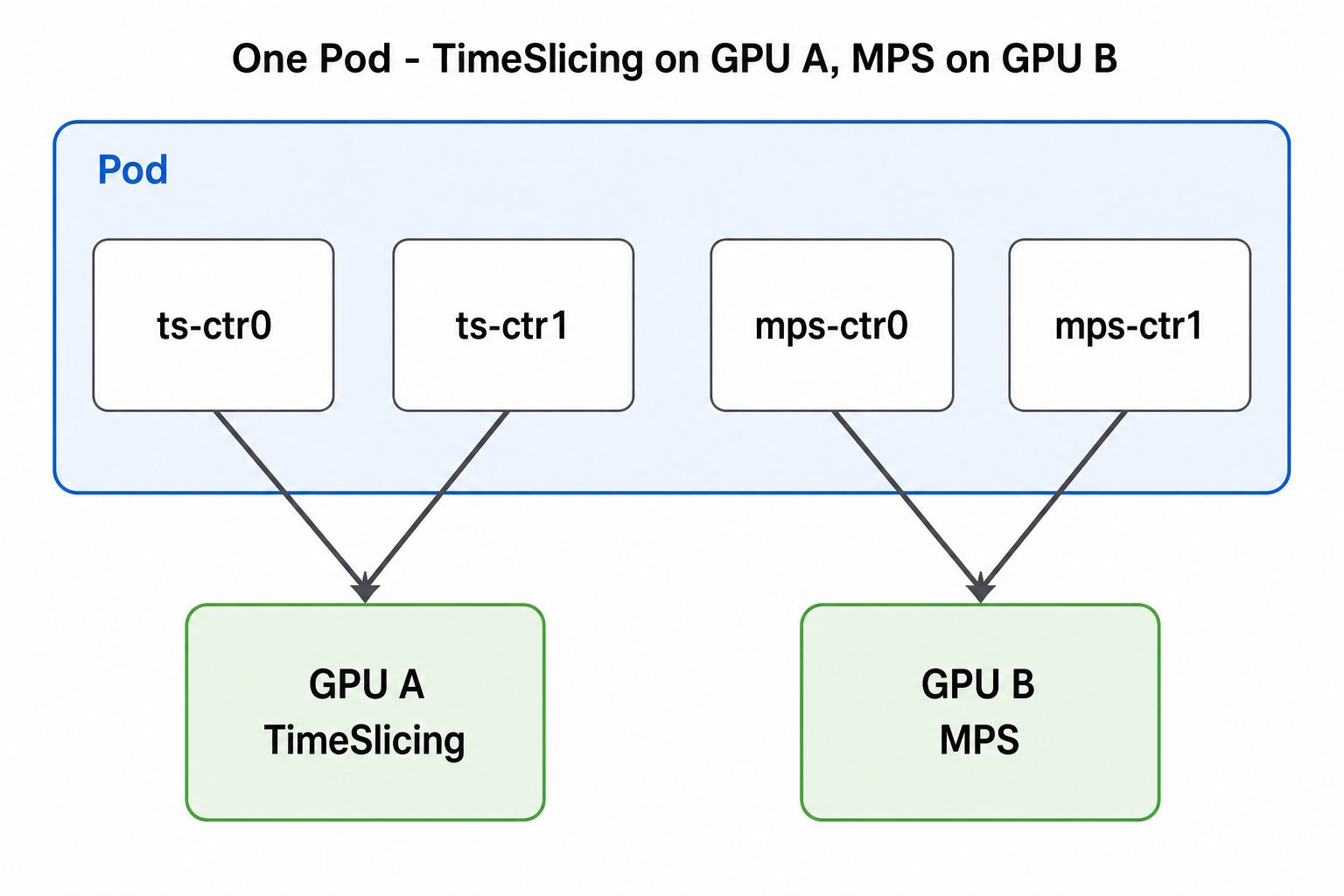
完整 YAML:mps-timeslicing/timeslicing-and-mps-sharing.yaml
完整 YAML:mps-timeslicing/timeslicing-and-mps-sharing.yaml
TimeSlicingSettings、MPSSupport,未开启时 kubelet 会在 NodePrepareResources 阶段拒绝。安装 DRA driver 时用 Helm 打开:
TimeSlicingSettings 不与任何特性冲突,可与 MPSSupport 同时开启;但 MPSSupport 与 DynamicMIG 互斥,两者不能同开(想跑动态 MIG 时需去掉 MPSSupport)。完整的互斥组合见官方 feature gate constraints。
5.3.3 静态 MIG
静态 MIG 需要先在节点上把 GPU 提前做好 MIG 切分(比如用nvidia-mig-parted),之后 ResourceClaim / ResourceClaimTemplate 只能申请这些已经切好的 MIG 规格。
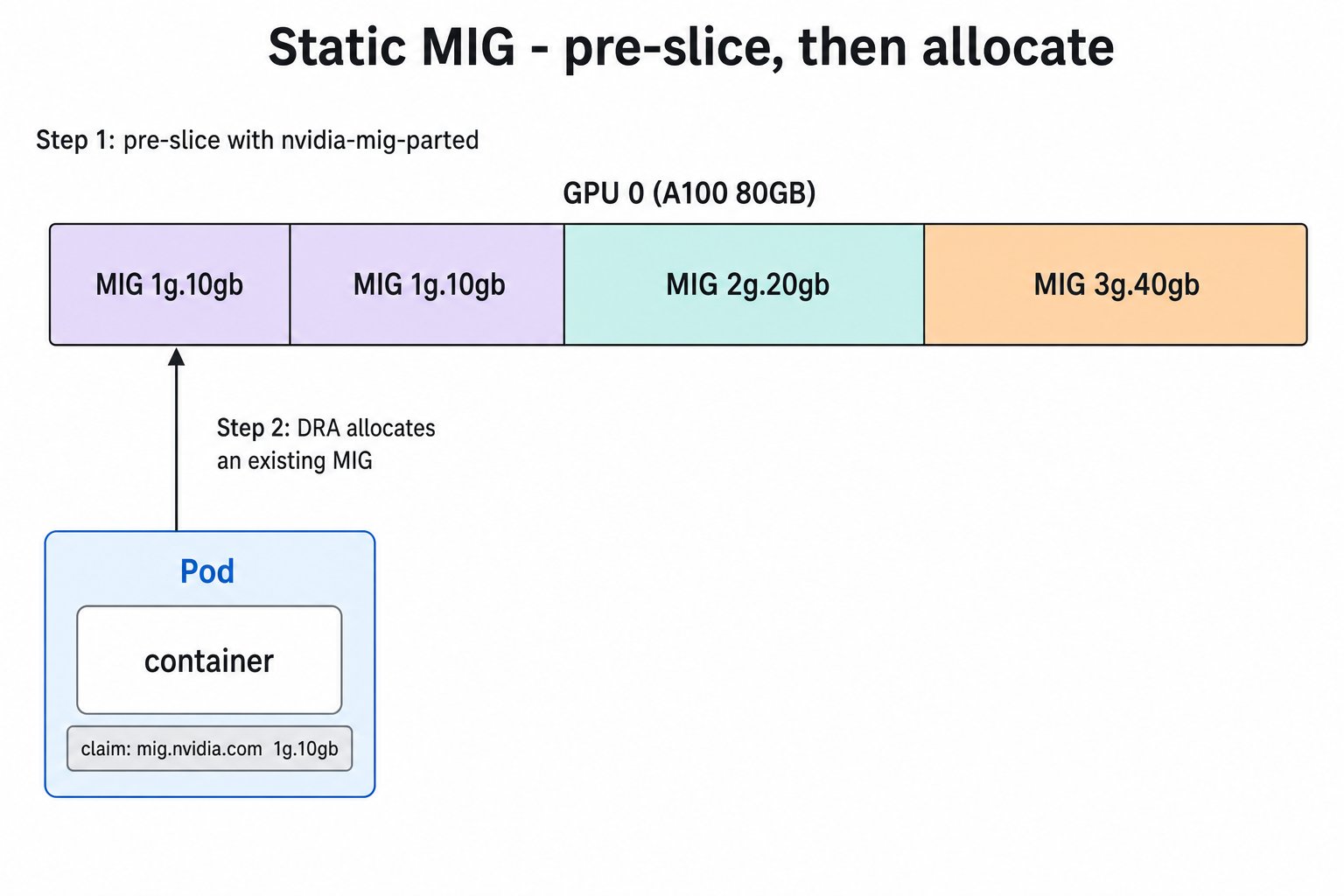
nvidia-mig-parted 布局文件描述每张卡切成什么。下面把 GPU 0 切成 1g.10gb×2 + 2g.20gb + 3g.40gb(compute slice 合计 7g,刚好切满 A100 80GB):
mig.nvidia.com DeviceClass,用 CEL selector 按 profile 选中已经切好的 MIG。完整清单见下:
完整 YAML:static-mig-a100/mig-static.yaml
完整 YAML:static-mig-a100/mig-static.yaml
5.3.4 动态 MIG
H100 及更新架构可按 claim 现切 MIG,无需提前切分:开启DynamicMIG feature gate 后,DRA driver 会直接依据 ResourceClaim 在卡上动态创建对应的 MIG 设备。
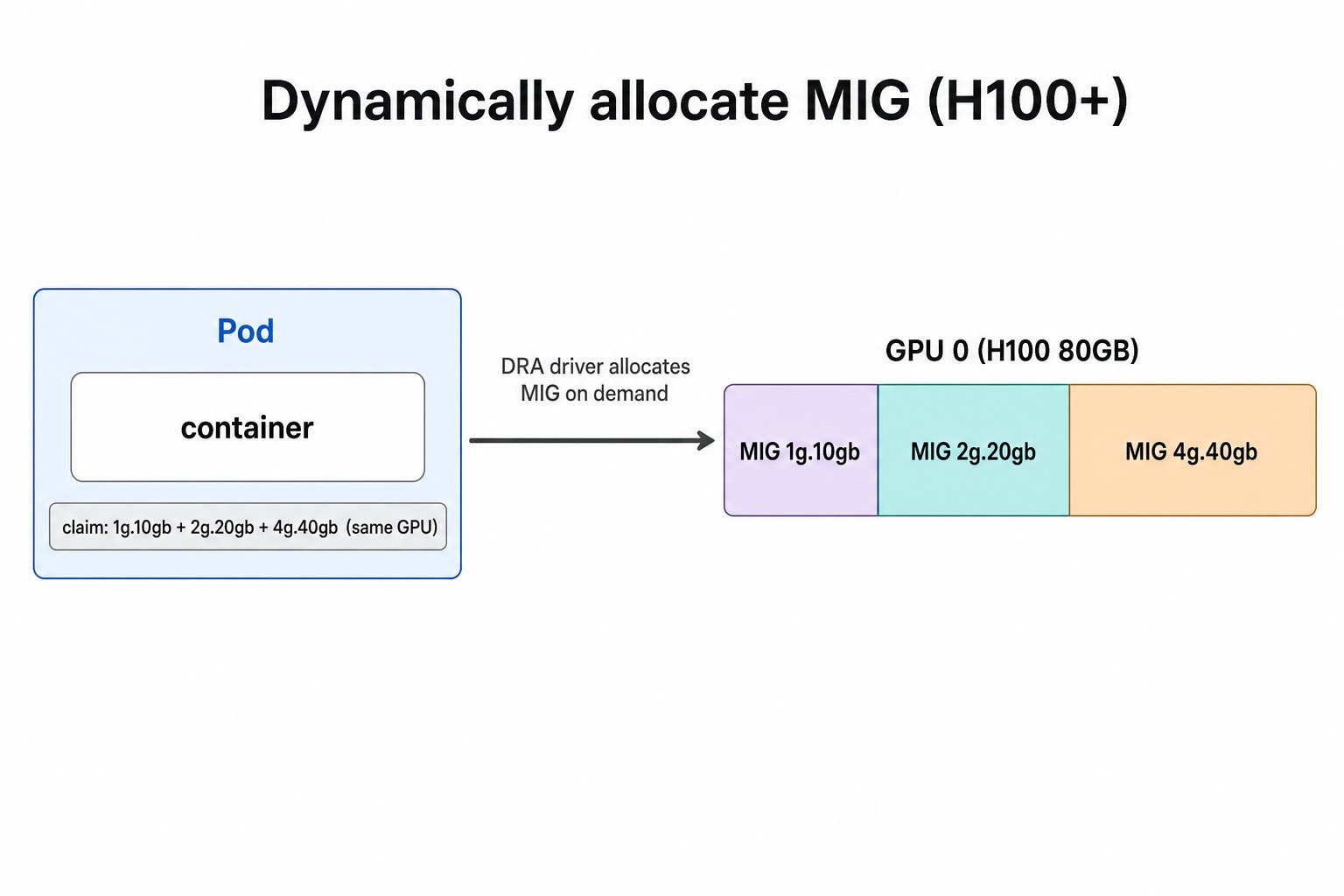
DynamicMIG feature gate(另外 Kubernetes 1.33–1.35 还需在 kube-apiserver、kube-scheduler 手动开启 DRAPartitionableDevices,1.36 起该 feature gate 默认开启):
ResourceClaim 里用 CEL selector 按 profile 选 MIG;区别只在于不用提前切分,driver 会根据申请按需现切出对应的 MIG。
一个 claim 里可以声明多个 request,一次拿到多块 MIG。constraints.matchAttribute: gpu.nvidia.com/parentUUID 是可选的:加上它会把这些 MIG 约束在同一张物理卡上;不加则各 request 独立匹配,可能分散到多张 GPU。
完整 YAML:dynamic-mig-h100/mig-multi-profile.yaml
完整 YAML:dynamic-mig-h100/mig-multi-profile.yaml
- DRA driver 把一张 GPU 的有限资源(显存切片、SM 等)声明成一个
CounterSet(放在ResourceSlice的sharedCounters字段里,通常一张物理卡一个),记录各项资源的总量; - 再把这张卡上所有可能的 MIG 切分组合都作为设备列进
ResourceSlice,每个设备用consumesCounters声明要从对应CounterSet消耗多少; - 调度时,调度器按「池总量 − 已分配
ResourceClaim的消耗」核对每个CounterSet的余量,某项 counter 不够时对应设备就无法被分配。
ResourceSlice(同属一个资源池,按规范拆成两份):右边的 counterset-slice 用 sharedCounters 声明每个 CounterSet 的总量;左边的 devices-slice 把所有可能的(互相重叠的)设备列出来,各用 consumesCounters 声明要从某个 CounterSet 扣掉多少。调度器为每个 CounterSet 跟踪可用 counter,只有余量足够时设备才可分配。
small-device-1 时,从 counterset-1 扣掉 20Gi 显存 + 2 CPU,该 CounterSet 的可用 counter 相应减少。

large-device 需要的 counter 已不够、无法再分配。注意 ResourceSlice 本身不会被改写——调度器是通过已分配的 ResourceClaim 反推每个 CounterSet 还剩多少。

5.3.5 ComputeDomain:多节点 NVLink
早期 NVIDIA DGX 的做法是把尽可能多的 GPU 塞进一台服务器、用高带宽 NVLink 连起来:单机内扩展很强,但作业规模被限制在一台机器内。GB300 NVL72 和 GB200 NVL72 正是为打破这一限制而生:每一台都提供由 NVLink Switch 连接的密集 GPU fabric,在机架内支持 NVIDIA Multi-Node NVLink(MNNVL),并包含具备 IMEX 能力的 compute tray,实现跨节点的 GPU 显存共享——整个机架因此变成一块统一的 GPU fabric,成为超大规模分布式训练与推理的基础。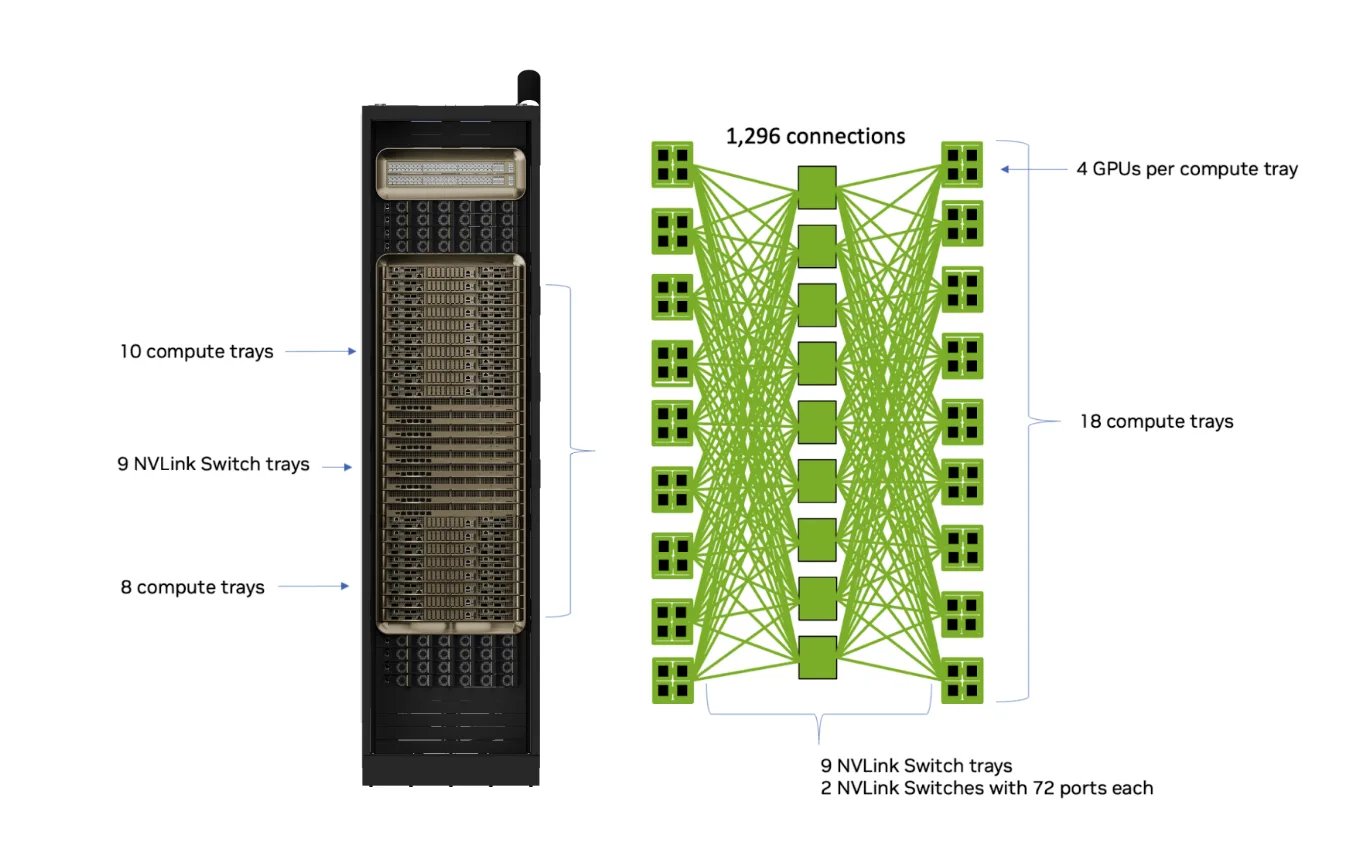
DGX GB200 系统——顶部 10 个、底部 8 个 compute tray,中间通过 9 个 NVLink Switch 相连,把 72 张 GPU 经 Multi-Node NVLink 连成一个全互连 mesh(chip-to-chip 1.8 TB/s,累计带宽超过 130 TB/s)
什么是 IMEX
什么是 IMEX
- 它与创建原始 handle 的进程处在同一个 IMEX domain;
- 它能访问创建原始 handle 的进程所用的同一个 IMEX channel;
- 它持有对该
sharedHandle的引用(sharedHandle的 export / import 具体方式见 Supporting GB200 on Kubernetes)。

handle(指向 ptr),把它导出成一个 sharedHandle;另一端的进程凭这个 sharedHandle 导入、在本地重建出 handle(同样指向那块 fabric 显存的 ptr)。于是两端进程虽然在不同节点、各有独立的地址空间,却通过 NVLink 读写到同一块物理显存——这就是跨节点显存共享的本质。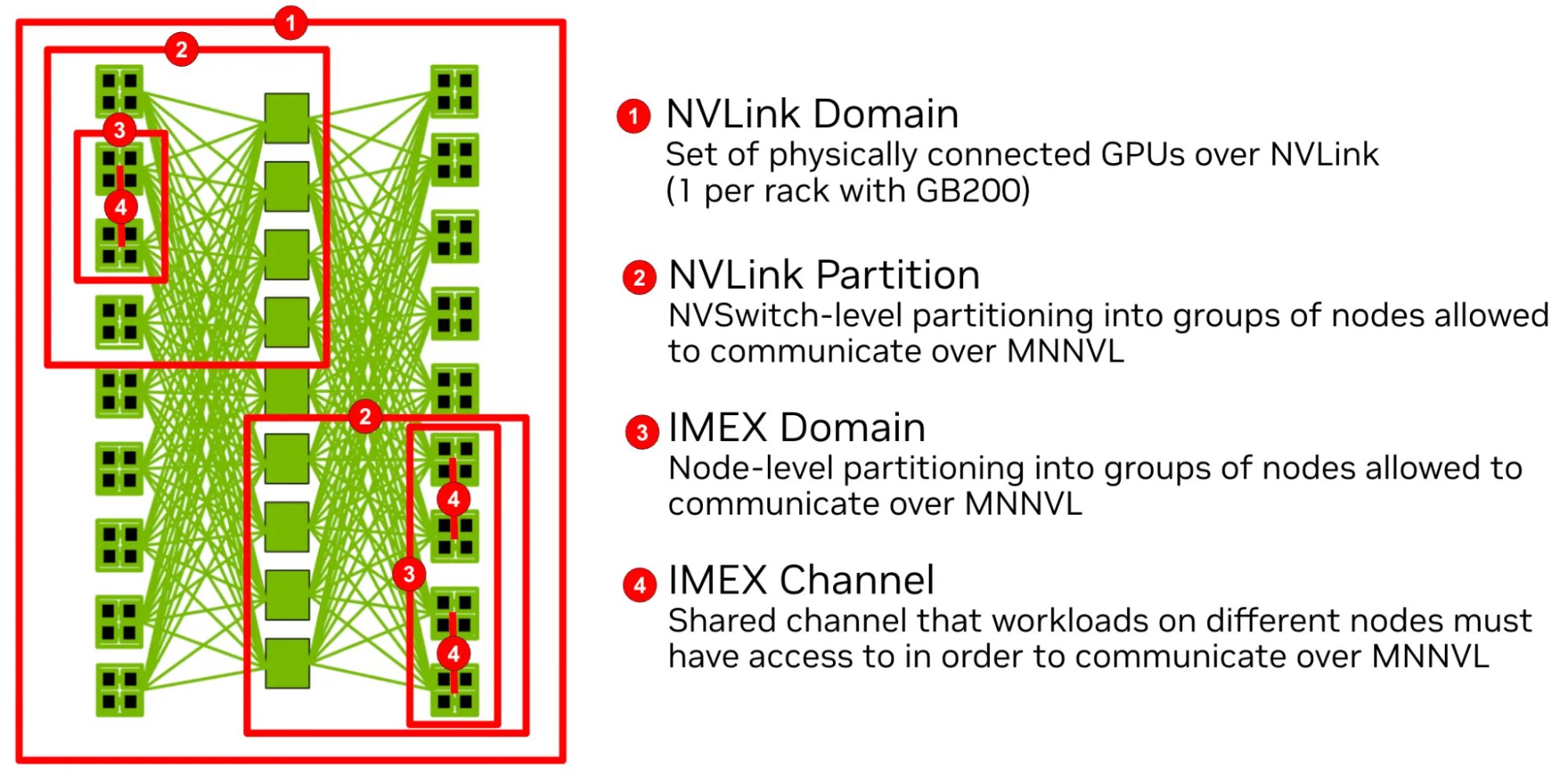
- NVLink Domain(NVLink 域):通过 NVLink 物理互连的一组 GPU;GB200 上一个 rack(NVL72)就是一个 NVLink Domain(72 GPU),有相同的 Cluster UUID。
- NVLink Partition(NVLink 分区):由 NVSwitch 硬件隔离出的分区,分区之间互不相通、用于多租户隔离;GPU 的 Clique ID 就对应它所属的分区(在 K8s 里,GFD 据此给节点打上
nvidia.com/gpu.clique标签)。 - IMEX Domain:某个 NVLink Partition 内运行
nvidia-imex的一组节点,必须共享同一<ClusterUUID, CliqueID>;一个 NVLink Partition 内可以有多个 IMEX Domain。 - IMEX Channel:IMEX Domain 内的一条软件通道,跨节点作业的各个进程拿到同一个 channel 才能互访显存;不同作业用不同 channel,互相隔离。
- 创建
ComputeDomain(图中compute-domain-0)后,compute-domain-controller会配套建出一个 DaemonSet 和一个ResourceClaimTemplate,此时还没真正组网:- 一个 per-domain 的 DaemonSet,用来在节点上运行
nvidia-imex;它的nodeSelector只认带有 ComputeDomain UID 标签的节点——标签形如resource.nvidia.com/computeDomain: <ComputeDomain 的 UID>。 - 一个供 workload 申请 channel 的
ResourceClaimTemplate(compute-domain-0-rct,背后是compute-domain-default-channel.nvidia.com这个 DeviceClass)。 - 此刻还没有节点带这个标签,所以没有 daemon Pod 在跑,也还没有 IMEX domain。
- 一个 per-domain 的 DaemonSet,用来在节点上运行
- workload Pod 引用该
ResourceClaimTemplate并被调度到节点后,daemon 才被拉起来:compute-domain-kubelet-plugin给所在节点打上上述标签,DaemonSet 随即在这批节点上拉起compute-domain-daemon。- 每个 daemon 运行
nvidia-imex(配置目录/imexd由 kubelet-plugin 挂载进 daemon 容器),管理本节点的 NVLink fabric 连接。 - daemon 通过 driver namespace 里的
ComputeDomainCliqueCR 公布自己的 IP、clique 归属和就绪状态。
- daemon 起来后互相组网,channel 也随之注入容器:
- 这些 daemon 组成一个 IMEX domain,也就是这批节点能互访显存的范围。
- workload Pod 申请到 channel 后,
compute-domain-kubelet-plugin向其容器注入对应的 IMEX channel 设备(/dev/nvidia-caps-imex-channels/channel0)。 - 同一 ComputeDomain 下所有 Pod 拿到同一个 channel(图中
channel 0),凭它跨节点读写彼此的 fabric 显存——真正能互访的,就是拿到同一 channel 的这批 Pod。
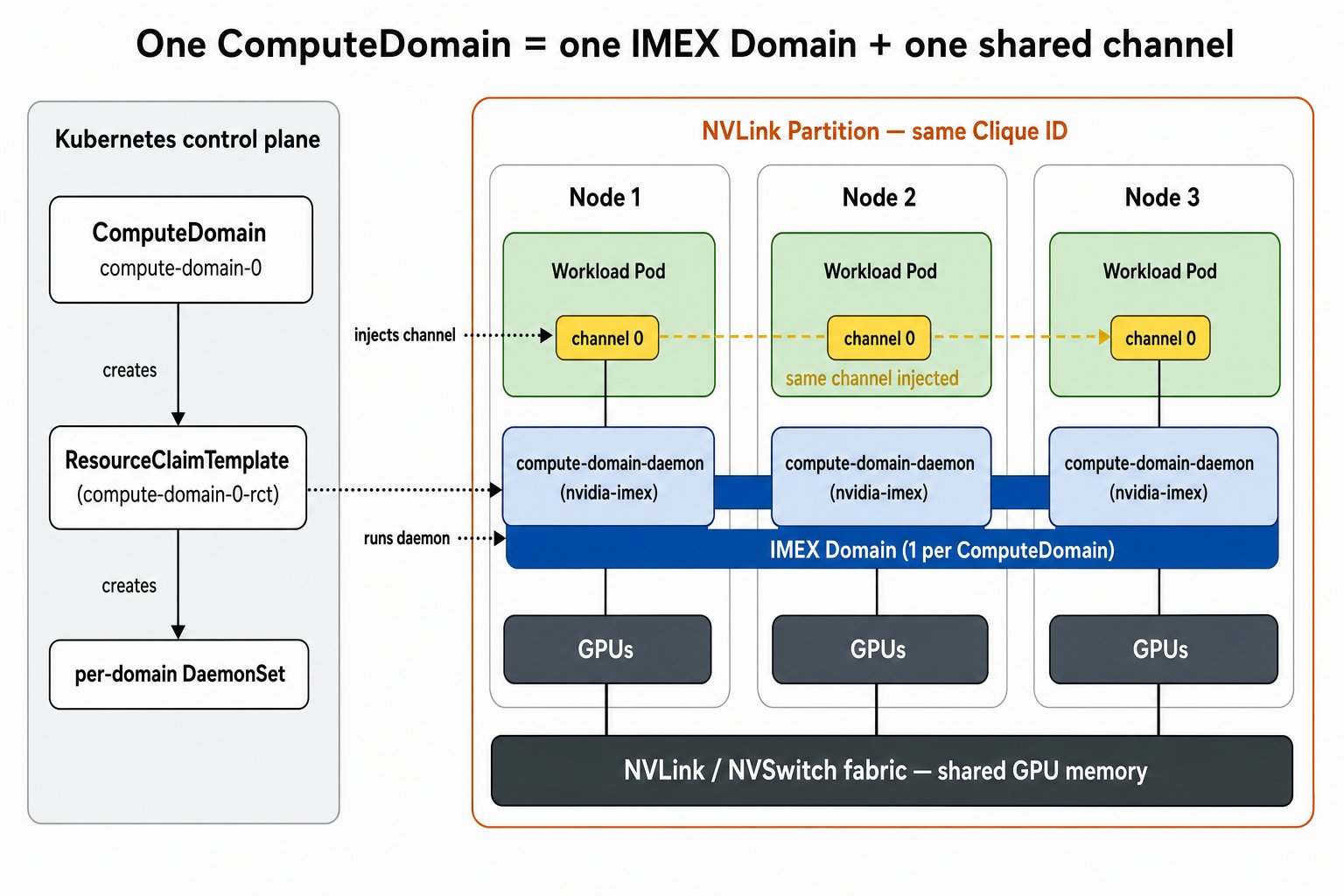
一个 ComputeDomain 对应一个 IMEX domain:controller 先建出 ResourceClaimTemplate 和 per-domain DaemonSet,workload Pod 落到节点后由 nvidia-imex 组成一个 IMEX domain,并给这批 Pod 注入同一个 channel,跨节点经 NVLink/NVSwitch fabric 共享显存
示例:两节点 nvbandwidth 测试(验证跨节点 NVLink)
示例:两节点 nvbandwidth 测试(验证跨节点 NVLink)
nvbandwidth 测试走一遍:每节点用 4 张 GPU,跨两个节点验证 GPU 之间能否以全 NVLink 带宽互访。MPI 作业的编排交给 MPI Operator(MPIJob),ComputeDomain 负责把这两个节点的 IMEX 打通。先装 MPI Operator:numNodes: 2 的 ComputeDomain,和一个引用它 channel 的 MPIJob(1 个 launcher + 2 个 worker,每 worker 4 GPU):MPIJob 的 1 个 launcher + 2 个 worker,以及 ComputeDomain 按 worker 落点节点拉起的 2 个 daemon:- ComputeDomain workloads:官方 workload 示例,覆盖创建
ComputeDomain、申请 channel、查看状态和 feature gates。 - Validate setup for ComputeDomain allocation:ComputeDomain 环境验证 checklist,包含 IMEX channel 注入测试和
nvbandwidth多节点测试。 - NVIDIA DRA Driver for GPUs - GPU Operator docs:解释 ComputeDomain、IMEX 安全边界和 GPU Operator 集成路径。
- Enabling Multi-Node NVLink on Kubernetes for NVIDIA GB200 NVL72 and Beyond:NVIDIA 官方博客,解释 ComputeDomain 与 GB200 NVL72 / MNNVL 的关系。
- Running AI Workloads on Rack-Scale Supercomputers:解释 rack-scale NVLink fabric、Cluster UUID、Clique ID 与拓扑感知调度的关系。
- NVIDIA GB200 NVL Partition:说明 NVLink Domain、NVLink Partition 和平台侧 partition 管理。
- Kubernetes support for GH200 / GB200:ComputeDomain 背景设计资料。
- Supporting GB200 on Kubernetes:GB200 / Kubernetes 支持相关 slides。
5.4 QoS
Kubernetes 按 Pod 的requests / limits 把它分成三个 QoS 级别:Guaranteed、Burstable、BestEffort。节点内存紧张时,kubelet 按 BestEffort → Burstable → Guaranteed 的顺序驱逐 Pod。
Guaranteed——每个容器的 CPU、memory requests 都等于 limits(CPU 取整数还能配合 CPU Manager static 独占核)。这样既不会在内存紧张时被优先驱逐,也是后续做 NUMA 保证分配的前提。
5.5 拓扑感知调度
为支撑延迟敏感、高吞吐的工作负载,Kubernetes 提供了一套 Resource Manager(资源管理器)。它们为那些对 CPU、设备、内存(hugepages)有特定要求的 Pod,协调并优化节点内资源的对齐。 Topology Manager 是 kubelet 的一个组件,负责协调这一组承担上述优化的管理器。这组管理器各管一类资源,都作为 Topology Manager 的 hint provider,与它协商来完成资源分配决策:- CPU Manager:kubelet 的组件,为 CPU 资源提供独占式分配。详见 Control CPU Management Policies on the Node。
- Memory Manager:kubelet 的组件,为内存资源提供独占式分配。详见 Control Memory Management Policies on a Node。
- Device Manager:kubelet 的组件,通过 device plugin API 把硬件设备分配给 Pod(拓扑信息由 device plugin 提供)。详见 Device Plugin Integration with the Topology Manager。
GetTopologyHints),合并后按策略决定是否准入该 Pod;准入后再让它们各自按选定的 NUMA 分配。这样 CPU、内存、设备就尽量落到同一个 NUMA 节点,减少跨 NUMA 访问。
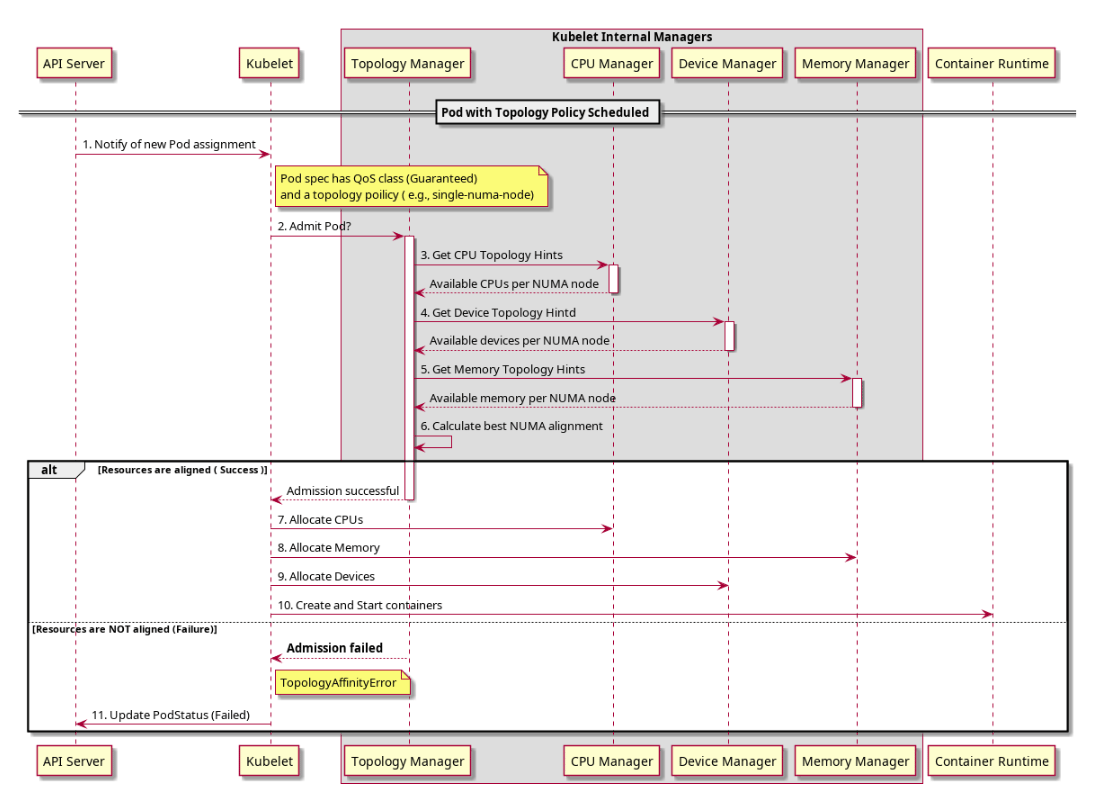
Topology Manager 在 Pod 准入阶段汇总 CPU / Memory / Device Manager 的 NUMA 提示,据此决定 Pod 能否被 kubelet 准入。图源:Kubernetes Topology Manager
--topology-manager-policy flag 或配置字段 topologyManagerPolicy 设置),对齐的严格程度依次递增:
none(默认):不做任何拓扑对齐。best-effort:为每个容器算出首选 NUMA 亲和;即使对不齐到首选,也照常准入(尽力而为)。restricted:算出首选亲和;若实际无法命中首选,则拒绝该 Pod。single-numa-node:判断资源能否落在单个 NUMA node,能则准入,否则拒绝。
topologyManagerScope 设置),决定对齐是「按容器」还是「按 Pod」:
container(默认):逐容器分别对齐,容器之间不成组,各自被独立地对齐到 NUMA。pod:把 Pod 内所有容器当作整体,一起对齐到单个 NUMA node 或同一组 NUMA node(Pod 的资源总量按 effective requests/limits 计算,即取「所有 app 容器请求之和」与「最大的单个 init 容器请求」中的较大值——也就是 Pod 同一时刻的峰值需求)。配合single-numa-node可把整个 Pod 放到一个 NUMA node 上,消除 Pod 内的跨 NUMA 通信开销,适合延迟敏感或高吞吐 IPC 应用。
5.5.1 CPU Manager
CPU Manager 是 kubelet 的组件,为 CPU 资源提供独占式分配能力。 默认情况下,kubelet 用 CFS quota(Linux CFS 调度器基于 cgroup 的 CPU 时间配额)来限制 Pod 的 CPU 上限;当节点上跑着很多 CPU 密集型 Pod 时,工作负载可能迁移到不同的 CPU 核上——取决于 Pod 是否被限流、以及调度时哪些核可用。多数负载对这种迁移不敏感,无需任何干预也能正常工作。但对 CPU cache 亲和、调度延迟明显影响性能的负载,kubelet 允许用 CPU 管理策略来影响核的放置。关键配置:- CPU Manager 有两种 policy(通过
cpuManagerPolicy配置):none(默认):不做额外绑核,沿用 OS 调度器默认的 CPU 亲和(CPU 上限仍由 CFS quota 限制)。static:让 Guaranteed Pod 中「整数 CPU 请求」的容器独占节点上的 CPU 核(独占性由 cpuset cgroup 控制器、即写cpuset.cpus强制);其余容器共用 shared pool。
- 启用
static时,kubelet 要求预留一份大于零的 CPU(否则独占核被占满后 shared pool 会变空,非独占容器无核可跑);下面三个参数任选其一或组合,预留的核都会从独占分配池里排除:
cpuManagerPolicyOptions 用来控制 static 策略的行为,可选项(按字母序):
static 的 KubeletConfiguration 示例:
5.5.2 Memory Manager
Memory Manager 是 kubelet 的组件,为 Guaranteed QoS 的 Pod 提供内存 / hugepages 的 NUMA 保证分配:它生成内存的 NUMA 亲和 hint 交给 Topology Manager,并通过 cgroup 的cpuset.mems 强制内存只从选定的 NUMA node 分配。关键配置:
- Memory Manager 有两种 policy(通过
memoryManagerPolicy配置):None(默认):不做内存 NUMA 对齐,一律返回默认 hint(等于没有 Memory Manager)。Static(仅 Linux):给 Guaranteed Pod 的内存 / hugepages 做 NUMA 保证分配并写cpuset.mems;BestEffort / Burstable 仍返回默认 hint。
- 启用
Static时必须配reservedMemory(逐 NUMA node 预留),且预留总量必须等于kubeReserved+systemReserved+evictionHard的memory.available三者之和,否则 kubelet 启动报错。计算公式如下:
memory.available 默认 100Mi)。含义是:节点总共预留多少内存,就得原样按 NUMA node 拆分下去,两边必须严格相等——多一点少一点 kubelet 都会启动报错。
5.5.3 Device Manager
Device Manager 通过 device plugin API 把设备(GPU、NIC 等)分配给 Pod。为了让设备也能参与 Topology Manager 的 NUMA 对齐,device plugin API 专门扩展出了一个TopologyInfo 结构:plugin 在 ListAndWatch 里逐个上报设备时带上它的 NUMA 归属,Device Manager 据此把设备的 NUMA 偏好转成 hint 交给 Topology Manager。
plugin 上报的单个设备(Device)长这样:
ID:设备唯一标识,不透明字符串,由 plugin 自定义(GPU 常用 UUID / minor number)。Health:健康状态(Healthy/Unhealthy),只有Healthy的设备才计入该资源的 allocatable。Topology.Nodes:设备的 NUMA 归属。这里{ID: 0}表示这块设备挂在 NUMA node 0 上;可填多个表示能从多个 NUMA node 访问,留空(Topology: nil)则表示无 NUMA 偏好。
5.5.4 拓扑感知调度示例
下面就演示一个拓扑感知调度的完整示例。 节点拓扑假设(2 个 NUMA node)KubeletConfiguration 里同时打开 CPU、Memory、Topology 三个 manager,并用 single-numa-node 策略把一个容器的所有资源都对齐到同一个 NUMA node:
requests == limits,因此属于 Guaranteed QoS(QoS 只看 CPU 和内存;GPU 这类扩展资源本身就要求 requests == limits,但不参与 QoS 判定)。只有 Guaranteed 的 Pod 才会触发三个 manager 的 NUMA 保证分配。
Preferred: true({n} 是 NUMA 位掩码的简记,{0,1} 表示同时用到 node0 和 node1)。本例单个 node 就够任一资源(node0 有 46 个可分配核、约 510Gi 内存、4 张 GPU,都 ≥ 请求量),所以三者形状一致:单节点 {0}、{1} 是首选,跨节点 {0,1} 也够但非最优。
Preferred 也全部相与,得到合并结果,再按 single-numa-node 策略筛选。
{0} 和 {1},Topology Manager 取最窄且最优的一个(宽度相同时选低位),即 NUMA node 0。于是准入该 Pod,并让三个 provider 都在 node 0 上分配:
- CPU Manager:从 node0 的可分配核(
2–47)里独占 16 核; - Memory Manager:128Gi 内存全部来自 node0;
- Device Manager:分配
gpu0–gpu3。
nvidia.com/gpu: 8,任何单个 node 都只有 4 张 GPU,合并后不存在成立的单节点组合,single-numa-node 会拒绝准入。
5.5.5 DRA:把拓扑对齐提前到调度阶段
5.5.4 拓扑感知调度示例 的对齐发生在节点准入阶段:scheduler 选节点时只核对节点级资源总量(够几核 CPU、多少内存、几张 GPU),只管数量够不够,不管这些资源在节点内的 NUMA 位置和互联。结果即便节点数量够,Pod 落上去后也可能没按最优的单 NUMA 方式部署,资源被迫跨 NUMA、拖慢性能。 DRA 把这层判断提前到调度阶段:driver 把设备拓扑写成属性(如resource.kubernetes.io/pcieRoot、gpu.nvidia.com/parentUUID),claim 用 constraints.matchAttribute 表达对齐要求,scheduler 选节点时就强制满足,直接挑一个能对齐的节点。GPU、NIC 这类设备之间的互联对齐现已可用;设备之外,CPU 和内存也在被逐步纳入 DRA(KEP-5517 DRANodeAllocatableResources,Kubernetes 1.36 alpha)。
dra-driver-cpu:用 DRA 替代 kubelet CPU Manager 做独占绑核,可按 core 类型、NUMA、LLC 等属性在调度阶段选核;与 CPU Manager 节点级互斥(需cpuManagerPolicy: none)。dra-driver-memory:同思路的 Memory Manager 替代,管内存 / hugepages 的 NUMA 分配。
- Kubernetes Topology Manager
- Control CPU Management Policies on the Node
- Control Memory Management Policies on a Node
- Resource Managers
- dra-driver-cpu
- dra-driver-memory
- KEP-5517 DRANodeAllocatableResources
- NVIDIA GB200 NVL tuning guide
- NVIDIA Topograph
5.6 优化网络通信
多节点 GPU 作业里,Pod 之间要频繁通信。Kubernetes 默认给每个 Pod 分配独立 IP,跨节点 Pod 之间还可能隔着 overlay 网络或 NAT,给性能敏感的 GPU 通信带来额外开销。 对性能敏感作业,可以让 Pod 直接用宿主机网络(hostNetwork: true,Docker 里对应 --network=host),容器网络不再隔离,直接使用宿主机的网络接口:
5.7 网络拓扑感知调度
数据中心网络是分层的交换机结构(节点 → 机架交换机 → spine → core),两个节点相距的交换机层级越多、通信越慢。分布式训练的多个 Pod 一旦被撒到不同机架、不同 spine 下,all-reduce、all-to-all 就会走慢速的跨交换机链路,拖垮整体吞吐。网络拓扑感知调度让调度器理解这套层级,把同一作业的 Pod(作为一个 gang)尽量放进同一个网络性能域,让集合通信走在跳数更少、带宽更高的近端链路上,降低延迟与拥塞。5.7.1 Kubernetes 官方方案
Kubernetes 官方原生提供的网络拓扑感知调度方案是 Topology-Aware Workload Scheduling(v1.36 alpha):在 kube-scheduler 上开启TopologyAwareWorkloadScheduling feature gate,用 PodGroup 表达 gang 调度和拓扑约束——拓扑约束基于某个 node label key(如 topology.kubernetes.io/rack),调度器的 TopologyPlacement 插件按该 label 的取值把节点分组,挑一个能装下整组 Pod 的域:
5.7.2 NVIDIA KAI Scheduler
KAI Scheduler 支持网络拓扑感知调度,做法分两步:先用Topology CRD 声明集群的拓扑层级,再在作业上用注解引用它、表达约束。第一步,Topology CRD 把一组 node label 从最外层(如 block)到最内层(单机)列成层级,scheduler 据此把节点组织成一棵树:
Job)上用注解引用这个 topology 并指定约束层级:kai.scheduler/topology 选择哪个 topology,topology-required-placement 是硬边界(必须落在该层内),topology-preferred-placement 是软优先(在硬边界内尽量收得更紧,只有比 required 更靠下的层级才有意义):
5.7.3 Volcano
Volcano 支持网络拓扑感知调度,做法是用HyperNode CRD 把网络显式建成交换机树:一个 HyperNode 代表一个网络拓扑性能域,通常映射到一个交换机 / TOR;多个 HyperNode 按层级连成树。叶子 HyperNode(tier 1)的成员是真实节点,非叶 HyperNode(tier 2、3…)的成员是下层 HyperNode——tier 越低,域内节点间通信越快。
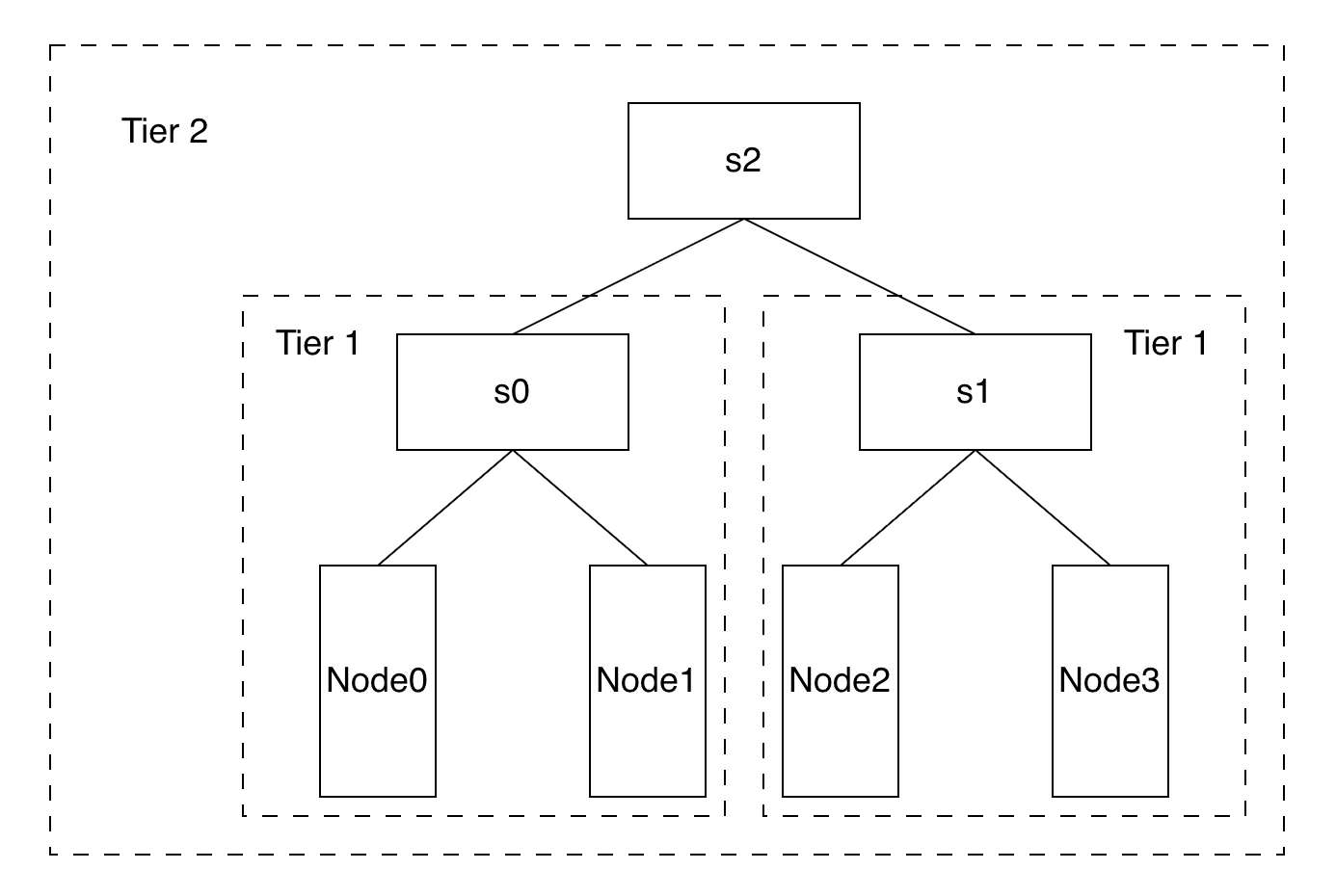
Volcano HyperNode 把网络建成交换机树:叶子(Tier 1,如 s0 / s1)含真实节点,上层(Tier 2,s2)逐级聚合。图源:Volcano Network Topology Aware Scheduling
s0、s1 是 tier 1 的叶子(各含两个节点),s2 是 tier 2、成员是 s0 和 s1:
networkTopology 声明要落在哪一层内。下面这个作业把所有 Pod 严格锁进同一个 leaf(tier 1,即单个 s0 或 s1):
- Topology-Aware Workload Scheduling(Kubernetes)、Kubernetes v1.36: Advancing Workload-Aware Scheduling
- KAI Scheduler Topology 文档
- Volcano Network Topology Aware Scheduling
FAQ
MIG 是专门针对单卡的,还是多卡也能用?
MIG 是专门针对单卡的,还是多卡也能用?
线程运行时修改 nice 值会不会有问题?
线程运行时修改 nice 值会不会有问题?
renice(底层 setpriority / sched_setattr)可以对正在运行的进程 / 线程动态调整 nice,内核会立即按新权重重新参与 CFS 调度,无需重启进程。几点注意:提高优先级(nice 调为负)需要 root 或 CAP_SYS_NICE,降低优先级普通用户即可;nice 只影响 CFS 普通线程之间相对的 CPU 时间分配,不改变程序正确性,也不等于独占 CPU;但不要把关键线程(如 DataLoader、通信辅助线程)的优先级调得过低,否则容易被其他进程抢占,反而拖慢对 GPU 的数据供给。